在前面的几章,分别分析了Bitcask,构建于Bitcask之上的MVCC,Raft,以及Raft状态机。在本章中,笔者会将这几个模块组合起来,分析MVCC持久化存储,Raft,Raft状态机之间如何交互,来为SQL算子提供支持,处理一次请求。
在本章,笔者会重点介绍两方面:
- 一是SQL Engine的组成,为上层的算子提供支持事务的读写操作
- 二是 Raft 通信部分,作为分布式数据库,涉及到各个模块之间的通信,其中一部分是在同一节点上使用 channel 实现的,另一部分是跨节点通信,通过 tcp 完成
SQL Engine的逻辑定义在src/sql/engine当中。分为三部分:
- 在
mod.rs当中,定义了一些通用的Trait,即对上层提供的接口。 - 在
kv.rs当中,定义了一个kv engine,对底层MVCC进行封装,来支持SQL的基础CRUD和事务操作。 - 在
raft.rs当中,定义了Raft的Client和状态机的实现,以及为Raft实现了Transaction Trait
在bustub和miniob当中,这一部分的概念并没有很凸显,在SQL算子当中,只需要对heap_file进行简单的封装,向上提供一个table_iterator用于遍历,和基于heap_file的插入和删除接口即可。
toydb是一个分布式的关系型数据库,命令需要先经过Raft达成共识,之后才能够执行和存储。这里定义的SQL Engine,就是屏蔽掉底层的所有实现细节,使上层算子能够像是使用单机的关系型数据库那种完成自身的逻辑。
Executor调用Transaction Trait,Executor并不会去关注实现是什么,但是这里的实际调用是Raft对Transaction Trait的实现,调用之后就会想上面描述的那样,走Raft Client的流程,先共识后执行。
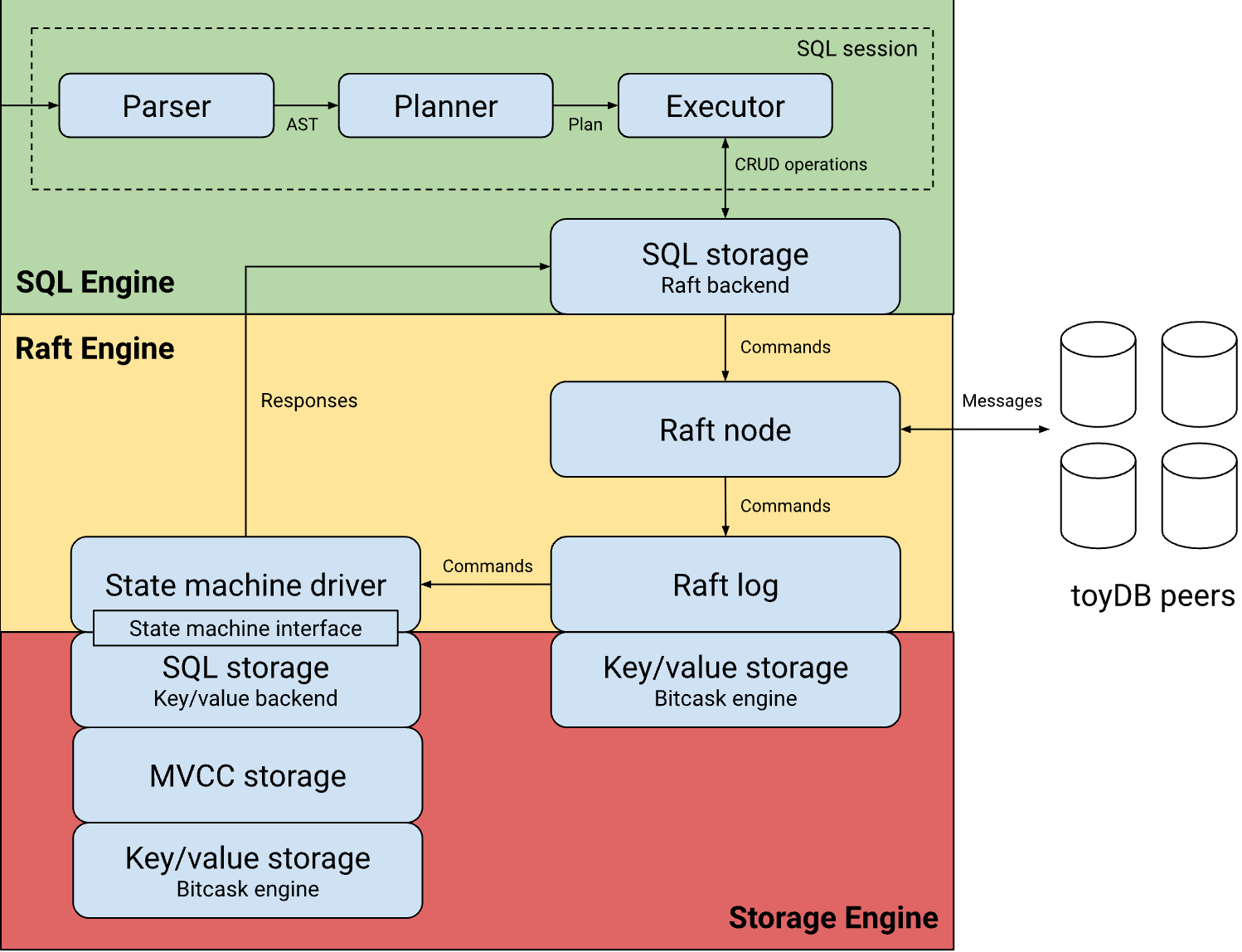
事务与执行#
这一部分共有三个trait,Engine用于开启事务,Transaction和Catalog用于执行。
在src/sql/engine/mod.rs当中,定义了一个Transaction Trait,在toydb当中,事务是sql执行的基本单位。因此在整个执行流程上都需要按照事务的方式来执行,Raft和kv engine都实现了Transaction Trait
Transaction继承自Catalog,Catalog当中封装的是与表结构相关的操作,即DDL,Transaction补充普通的操作类型,即DML。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| pub trait Catalog {
/// Creates a new table
fn create_table(&mut self, table: Table) -> Result<()>;
/// Deletes an existing table, or errors if it does not exist
fn delete_table(&mut self, table: &str) -> Result<()>;
/// Reads a table, if it exists
fn read_table(&self, table: &str) -> Result<Option<Table>>;
/// Iterates over all tables
fn scan_tables(&self) -> Result<Tables>;
/// Reads a table, and errors if it does not exist
fn must_read_table(&self, table: &str) -> Result<Table> {
self.read_table(table)?
.ok_or_else(|| Error::Value(format!("Table {} does not exist", table)))
}
/// Returns all references to a table, as table,column pairs.
fn table_references(&self, table: &str, with_self: bool) -> Result<Vec<(String, Vec<String>)>> {
Ok(self
.scan_tables()?
.filter(|t| with_self || t.name != table)
.map(|t| {
(
t.name,
t.columns
.iter()
.filter(|c| c.references.as_deref() == Some(table))
.map(|c| c.name.clone())
.collect::<Vec<_>>(),
)
})
.filter(|(_, cs)| !cs.is_empty())
.collect())
}
}
pub trait Transaction: Catalog {
/// The transaction's version
fn version(&self) -> u64;
/// Whether the transaction is read-only
fn read_only(&self) -> bool;
/// Commits the transaction
fn commit(self) -> Result<()>;
/// Rolls back the transaction
fn rollback(self) -> Result<()>;
/// Creates a new table row
fn create(&mut self, table: &str, row: Row) -> Result<()>;
/// Deletes a table row
fn delete(&mut self, table: &str, id: &Value) -> Result<()>;
/// Reads a table row, if it exists
fn read(&self, table: &str, id: &Value) -> Result<Option<Row>>;
/// Reads an index entry, if it exists
fn read_index(&self, table: &str, column: &str, value: &Value) -> Result<HashSet<Value>>;
/// Scans a table's rows
fn scan(&self, table: &str, filter: Option<Expression>) -> Result<Scan>;
/// Scans a column's index entries
fn scan_index(&self, table: &str, column: &str) -> Result<IndexScan>;
/// Updates a table row
fn update(&mut self, table: &str, id: &Value, row: Row) -> Result<()>;
}
|
Engine#
这里的Engine与之前在Bitcask和MVCC当中所说的engine不是一个概念,在存储方面,engine指的是存储引擎,而这里的Engine是一个SQL引擎,Engine的本质上为一个Wrapper,对Transaction进行包裹,提供了三种类型的begin用于开启事务,为别对应普通的读写事务,只读事务和time-travel类型的只读事务。如果没有开启事务,就调用Engine当中定义的方法开启一个事务,当事务开启之后,就可以调用Transaction Trait当中的内容来执行事务。
此外还有一个session函数,用于返回一个Session,一个Session用于执行一个独立的statements(即一条SQL,SQL解析会生成一个Statement)。
Engine为一个Trait,kv与Raft分别给出了自己的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| pub trait Engine: Clone {
/// The transaction type
type Transaction: Transaction;
/// Begins a read-write transaction.
fn begin(&self) -> Result<Self::Transaction>;
/// Begins a read-only transaction.
fn begin_read_only(&self) -> Result<Self::Transaction>;
/// Begins a read-only transaction as of a historical version.
fn begin_as_of(&self, version: u64) -> Result<Self::Transaction>;
/// Begins a session for executing individual statements
fn session(&self) -> Result<Session<Self>> {
Ok(Session { engine: self.clone(), txn: None })
}
}
|
Session#
一个Session对应一条SQL的执行,在其中只有两个字段,engine用于真正执行sql,txn保存当前的事务:
1
2
3
4
5
6
| pub struct Session<E: Engine> {
/// The underlying engine
engine: E,
/// The current session transaction, if any
txn: Option<E::Transaction>,
}
|
Session只有一个方法execute(),这是一条SQL执行的起始点,在完成了网络连接部分之后,就会调用到这里,传入未解析的SQL,在其中首先进行解析,生成对应的Statement,之后根据Statement的类型决定如何执行,大致分为各种类型的Begin,Commit,Rollback,和正常SQL这四种类型。
然后在这其中,会完成 Planner → Optimizer → Executor的这个过程,完成SQL执行的过程,这里简单列举几个:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| pub fn execute(&mut self, query: &str) -> Result<ResultSet> {
// FIXME We should match on self.txn as well, but get this error:
// error[E0009]: cannot bind by-move and by-ref in the same pattern
// ...which seems like an arbitrary compiler limitation
match Parser::new(query).parse()? {
ast::Statement::Begin { read_only: false, as_of: None } => {
let txn = self.engine.begin()?;
let result = ResultSet::Begin { version: txn.version(), read_only: false };
self.txn = Some(txn);
Ok(result)
}
ast::Statement::Commit => {
let txn = self.txn.take().unwrap();
let version = txn.version();
txn.commit()?;
Ok(ResultSet::Commit { version })
}
ast::Statement::Rollback => {
let txn = self.txn.take().unwrap();
let version = txn.version();
txn.rollback()?;
Ok(ResultSet::Rollback { version })
}
ast::Statement::Explain(statement) => self.read_with_txn(|txn| {
Ok(ResultSet::Explain(Plan::build(*statement, txn)?.optimize(txn)?.0))
}),
statement @ ast::Statement::Select { .. } => {
let mut txn = self.engine.begin_read_only()?;
let result =
Plan::build(statement, &mut txn)?.optimize(&mut txn)?.execute(&mut txn);
txn.rollback()?;
result
}
statement => {
let mut txn = self.engine.begin()?;
match Plan::build(statement, &mut txn)?.optimize(&mut txn)?.execute(&mut txn) {
Ok(result) => {
txn.commit()?;
Ok(result)
}
Err(error) => {
txn.rollback()?;
Err(error)
}
}
}
}
|
事务实现#
在toydb当中,SQL的执行单位为事务,即便是一条SQL,也会默认开启一个事务,SQL的执行首先会去Raft层进行共识,达成quorum之后再交给底层的MVCC去执行和存储,因此对于一个事务,其无论是begin,commit还是正常的sql执行,都需要先走raft,然后再走MVCC。
那么对于二者事务的动作,就会进行统一的定义,即上面介绍的三个trait:Transacion、Catalog、Engine。MVCC和Raft都给出了自己的实现。
以begin为例,调用begin时会先调用到Raft当中对Transaction中begin的实现,之后Apply时调用到MVCC中对begin的实现,完成一次完整的请求。
在本段中,由于Raft会依赖MVCC,因此以一种自底向上的模式,先介绍MVCC部分,之后再分析Raft。在Raft当中,除了事务相关的部分,还有上一章遗留的状态机实现,也一并在这里分析。
KV Engine#
在kv.rs当中,主要定义了两部分内容,首先是一个KV结构体,为一个storage::mvcc::MVCC的Wrapper。而另一部分就是Transaction Trait的实现。
在KV当中,主要利用带有MVCC逻辑的kv存储引擎来实现事务的功能和存储元数据,供raft.rs当中的某些实现调用,为其提供支持。
KV本身有三个方法:
resume():通过传入的State,恢复出事务的状态,这里的state就是在02-MVCC当中介绍的TransactionStateget_metadata():存储元数据,供Raft状态机使用,存储last_applied_index,调用的是底层的不带版本的kv存储set_metadata():存储元数据,同上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| /// A SQL engine based on an underlying MVCC key/value store.
pub struct KV<E: storage::engine::Engine> {
/// The underlying key/value store.
pub(super) kv: storage::mvcc::MVCC<E>,
}
impl<E: storage::engine::Engine> KV<E> {
/// Creates a new key/value-based SQL engine
pub fn new(engine: E) -> Self {
Self { kv: storage::mvcc::MVCC::new(engine) }
}
/// Resumes a transaction from the given state
pub fn resume(
&self,
state: storage::mvcc::TransactionState,
) -> Result<<Self as super::Engine>::Transaction> {
Ok(<Self as super::Engine>::Transaction::new(self.kv.resume(state)?))
}
/// Fetches an unversioned metadata value
pub fn get_metadata(&self, key: &[u8]) -> Result<Option<Vec<u8>>> {
self.kv.get_unversioned(key)
}
/// Sets an unversioned metadata value
pub fn set_metadata(&self, key: &[u8], value: Vec<u8>) -> Result<()> {
self.kv.set_unversioned(key, value)
}
}
|
此外KV还实现了定义在mod.rs当中的Engine Trait,同样也是直接调用底层的对应的方法即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| impl<E: storage::engine::Engine> super::Engine for KV<E> {
type Transaction = Transaction<E>;
fn begin(&self) -> Result<Self::Transaction> {
Ok(Self::Transaction::new(self.kv.begin()?))
}
fn begin_read_only(&self) -> Result<Self::Transaction> {
Ok(Self::Transaction::new(self.kv.begin_read_only()?))
}
fn begin_as_of(&self, version: u64) -> Result<Self::Transaction> {
Ok(Self::Transaction::new(self.kv.begin_as_of(version)?))
}
}
|
Transaction#
和KV一样,Transaction也是一个Wrapper,其中只有一个字段,就是mvcc当中的Transaction。
这一部分的逻辑就是先做一些预处理,将原本只有get set和begin等方法的MVCC kv存储引擎,扩展为MVCC的SQL存储引擎,支持建表,插入删除一行数据,全表扫描等SQL功能
1
2
3
| pub struct Transaction<E: storage::engine::Engine> {
txn: storage::mvcc::Transaction<E>,
}
|
Transaction的实现分成了三部分:
- 自身定义了一些存储和加载索引的操作
- 实现Transaction trait和
- 实现Catalog trait。
Index
首先,toydb当中的索引是非聚簇索引
由于toydb的底层是KV存储,因此并不能像bustub那样去分文件存储,toydb的索引格式为:<table + column + key,HashSet<primary_key>>的复合key-value。这样便可以使用kv存储引擎来保存。在实现上value使用HashSet保存一个表中同一列所有值相同的主键id
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| fn index_save(
&mut self,
table: &str,
column: &str,
value: &Value,
index: HashSet<Value>,
) -> Result<()> {
let key = Key::Index(table.into(), column.into(), value.into()).encode()?;
if index.is_empty() {
self.txn.delete(&key)
} else {
self.txn.set(&key, serialize(&index)?)
}
}
|
Transaction
到处都是Transaction,这里的Transaction是构建在storage::mvcc之上,来实现mod.rs当中的Transaction Trait。将kv造作转换为基础的sql操作,如Insert、Delete、SeqScan、IndexScan等。挑几个看一下:
create
create用于在已经存在的表当中插入一条数据:
- 根据table name读取出table的metadata
- 根据metadata校验插入的row,检验其在column上与table是否符合
- 根据主键id进行读取,如果存在则放弃插入,不允许有primary_key重复的row
- 调用底层storage::mvcc存储row,key为table + primary_key,val为row
- 调用上面的index_save,index_load更新索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| fn create(&mut self, table: &str, row: Row) -> Result<()> {
// (1)
let table = self.must_read_table(table)?;
// (2)
table.validate_row(&row, self)?;
let id = table.get_row_key(&row)?;
// (3)
if self.read(&table.name, &id)?.is_some() {
return Err(Error::Value(format!(
"Primary key {} already exists for table {}",
id, table.name
)));
}
// (4)
self.txn.set(&Key::Row((&table.name).into(), (&id).into()).encode()?, serialize(&row)?)?;
// (5) Update indexes
for (i, column) in table.columns.iter().enumerate().filter(|(_, c)| c.index) {
let mut index = self.index_load(&table.name, &column.name, &row[i])?;
index.insert(id.clone());
self.index_save(&table.name, &column.name, &row[i], index)?;
}
Ok(())
}
|
scan
scan用于实现一个SeqScan + Filter的功能(函数式编程魅力时刻):
- 首先根据table name读取出table metadata
- 创建一个KeyPrefix,传入table.name,这样进行前缀扫描会从存储引擎当中获取出该table的所有的key,转换为迭代器
- 使用一个map来处理读取结果,iter遍历返回的是一个
Result<(Vec<u8>,Vec<u8>),Error>的key-val对,如果Ok(),就读取出val进行反序列化 - 对反序列化得到的value进行谓词匹配,根据匹配结果进行进一步的封装
- collect成Vec,转换为iter向上返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| fn scan(&self, table: &str, filter: Option<Expression>) -> Result<super::Scan> {
let table = self.must_read_table(table)?;
Ok(Box::new(
self.txn
.scan_prefix(&KeyPrefix::Row((&table.name).into()).encode()?)?
.iter()
.map(|r| r.and_then(|(_, v)| deserialize(&v)))
.filter_map(move |r| match r {
Ok(row) => match &filter {
Some(filter) => match filter.evaluate(Some(&row)) {
Ok(Value::Boolean(b)) if b => Some(Ok(row)),
Ok(Value::Boolean(_)) | Ok(Value::Null) => None,
Ok(v) => Some(Err(Error::Value(format!(
"Filter returned {}, expected boolean",
v
)))),
Err(err) => Some(Err(err)),
},
None => Some(Ok(row)),
},
err => Some(err),
})
.collect::<Vec<_>>()
.into_iter(),
))
}
|
read & read_index
这两个的实现差不多,都是构建出一个key,然后去存储引擎当中读取:
1
2
3
4
5
6
7
8
9
10
11
12
13
| fn read(&self, table: &str, id: &Value) -> Result<Option<Row>> {
self.txn
.get(&Key::Row(table.into(), id.into()).encode()?)?
.map(|v| deserialize(&v))
.transpose()
}
fn read_index(&self, table: &str, column: &str, value: &Value) -> Result<HashSet<Value>> {
if !self.must_read_table(table)?.get_column(column)?.index {
return Err(Error::Value(format!("No index on {}.{}", table, column)));
}
self.index_load(table, column, value)
}
|
其他的受限于篇幅,就不在本文展开了,读者可自行阅读
Catalog
在Catalog当中,实现的方法都是和表结构相关的,即DDL,如创建删除表等。总体来说和Transaction逻辑差不多
create_table
和create差不多,创建一个table的key,存到存储引擎当中,key为table.name,val为table.metadata。
1
2
3
4
5
6
7
8
9
10
11
12
| pub struct Table {
pub name: String,
pub columns: Vec<Column>,
}
fn create_table(&mut self, table: Table) -> Result<()> {
if self.read_table(&table.name)?.is_some() {
return Err(Error::Value(format!("Table {} already exists", table.name)));
}
table.validate(self)?;
self.txn.set(&Key::Table((&table.name).into()).encode()?, serialize(&table)?)
}
|
其他的都差不多,就不展示了。
Raft#
除了Raft Package之外,其他的与Raft相关的逻辑都定义在src/sql/engine/raft.rs当中,大致分为:
- Raft状态机的实现
- Raft对事务的支持,与上面KV相对应,包括
Transaction、Catalog和Engine - Raft Client,负责与Raft Server进行通信,将需要执行的命令发送给Server
状态机实现#
在介绍完KV Engine的实现之后,可以补全上一章留下的Raft状态机的实现了。在上一章中,说明了Raft状态机会使用Notify和Querys来分别管理写请求和只读请求,二者的处理方式不一样,写请求需要走日志达成共识,而读请求可以使用ReadIndex来进行优化。
请求类型
为了区分读写请求,使用枚举进行定义:
首先在src/raft/message.rs当中,定义了一个枚举,用于确定Request的类型,是读(Query)还是写(Mutate):
1
2
3
4
5
6
7
| /// A client request.
#[derive(Clone, Debug, PartialEq, Serialize, Deserialize)]
pub enum Request {
Query(Vec<u8>),
Mutate(Vec<u8>),
Status,
}
|
在src/sql/engine/raft.rs当中将请求类型进行的细化,使用枚举根据sql算子的类型进行分类(也并不是与SQL算子一一对应的,只不过是算子执行过程中需要的操作,但总体上还是和SQL还是能对的上号的):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| enum Query {
/// Fetches engine status
Status,
/// Reads a row
Read { txn: TransactionState, table: String, id: Value },
/// Reads an index entry
ReadIndex { txn: TransactionState, table: String, column: String, value: Value },
/// Scans a table's rows
Scan { txn: TransactionState, table: String, filter: Option<Expression> },
/// Scans an index
ScanIndex { txn: TransactionState, table: String, column: String },
/// Scans the tables
ScanTables { txn: TransactionState },
/// Reads a table
ReadTable { txn: TransactionState, table: String },
}
enum Mutation {
/// Begins a transaction
Begin { read_only: bool, as_of: Option<u64> },
/// Commits the given transaction
Commit(TransactionState),
/// Rolls back the given transaction
Rollback(TransactionState),
/// Creates a new row
Create { txn: TransactionState, table: String, row: Row },
/// Deletes a row
Delete { txn: TransactionState, table: String, id: Value },
/// Updates a row
Update { txn: TransactionState, table: String, id: Value, row: Row },
/// Creates a table
CreateTable { txn: TransactionState, schema: Table },
/// Deletes a table
DeleteTable { txn: TransactionState, table: String },
}
|
状态机
状态机实现定义如下,其中有两个字段,一个是在上文当中介绍的KV Engine,用于持久化存储数据,另外一个是applied_index:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| pub struct State<E: storage::engine::Engine> {
/// The underlying KV SQL engine
engine: super::KV<E>,
/// The last applied index
applied_index: u64,
}
pub trait State: Send {
/// Returns the last applied index from the state machine.
fn get_applied_index(&self) -> Index;
/// Applies a log entry to the state machine. If it returns Error::Internal,
/// the Raft node halts. Any other error is considered applied and returned
/// to the caller.
///
/// The entry may contain a noop command, which is committed by Raft during
/// leader changes. This still needs to be applied to the state machine to
/// properly track the applied index, and returns an empty result.
///
/// TODO: consider using runtime assertions instead of Error::Internal.
fn apply(&mut self, entry: Entry) -> Result<Vec<u8>>;
/// Queries the state machine. All errors are propagated to the caller.
fn query(&self, command: Vec<u8>) -> Result<Vec<u8>>;
}
|
get_applied_index实现很简单,直接返回即可
apply将Raft当中commit的日志交给Raft状态机来执行,这里需要Apply的一定是Mutate类型的,在Raft状态机当中,解析出对应的命令之后,根据Mutate的具体类型,调用mutate(&mut self, mutation: Mutation)来执行命令,在该函数当中,根据命令类型来调用底层KV Engine对应的实现来执行,之后使用set_metadata()来更新last_applied_index。
在02-MVCC当中,留下了一个伏笔:
在注释当中,对于TransactionState的设计理念做了比较详细的说明,简而言之就是,事务状态的设计使得事务可以在不同的组件之间安全地传递,并且可以在不直接引用事务本身的情况下被引用,有助于简化事务管理。
A Transaction’s state, which determines its write version and isolation. It is separate from Transaction to allow it to be passed around independently of the engine. There are two main motivations for this:
- It can be exported via Transaction.state(), (de)serialized, and later used to instantiate a new functionally equivalent Transaction via Transaction::resume(). This allows passing the transaction between the storage engine and SQL engine (potentially running on a different node) across the Raft state machine boundary.
- It can be borrowed independently of Engine, allowing references to it in VisibleIterator, which would otherwise result in self-references.
在enum Mutate当中,会携带一个TransactionState,这个State会随着命令被传递,在mutate()当中,获取到TransactionState就可以恢复出事务的状态,然后就可以继续执行该事务,实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| fn apply(&mut self, entry: Entry) -> Result<Vec<u8>> {
assert_eq!(entry.index, self.applied_index + 1, "entry index not after applied index");
let result = match &entry.command {
Some(command) => match self.mutate(bincode::deserialize(command)?) {
error @ Err(Error::Internal(_)) => return error, // don't record as applied
result => result,
},
None => Ok(Vec::new()),
};
self.applied_index = entry.index;
self.engine.set_metadata(b"applied_index", bincode::serialize(&entry.index)?)?;
result
}
fn mutate(&mut self, mutation: Mutation) -> Result<Vec<u8>> {
match mutation {
// ...
// ...
// 使用resume恢复出事务状态,继续事务的执行
Mutation::CreateTable { txn, schema } => {
bincode::serialize(&self.engine.resume(txn)?.create_table(schema)?)
}
Mutation::DeleteTable { txn, table } => {
bincode::serialize(&self.engine.resume(txn)?.delete_table(&table)?)
}
}
}
|
Query也差不多,反序列化后调用KV Engine当中对应的实现即可,完成一条只读请求。
Raft Client#
Raft Client并不是一个独立运行的Client,只是用于在SQL执行前,将对应的命令先发送给Server去共识,之后再真实执行,一次完整的请求过程如下:
- 解析sql,调用对应的sql算子开始执行,将需要执行的命令通过client发送给server
- server的Leader拿到命令之后开始进行日志复制,尝试达成共识
- 达成共识之后,在Raft状态机调用Apply或者Query执行对应的命令
- Leader从状态机当中接收到对应的执行结果,返回给Client
- Client 处理执行结果,向上返回完成 SQL 的执行。
在raft.rs当中,定义了一个Client的结构体,其中只有一个字段,就是用来发送请求的channel,通过该channel,会将请求发送到Server Leader处,client-server之间怎样进行通信的,会留到后面单独分析。
1
2
3
4
5
6
7
| /// A client for the local Raft node.
#[derive(Clone)]
struct Client {
// 这里的tx为raft_tx,raft_server那边拿到的为raft_rx,raft_rx在Raft模块当中被重命名为client_tx
// 所以这里的tx对应的是client_tx
tx: mpsc::UnboundedSender<(raft::Request, oneshot::Sender<Result<raft::Response>>)>,
}
|
在实现上,定义一个execute()用于承担发送命令的功能,在此之上分别封装mutate和query用于发送读写请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| impl Client {
/// Creates a new Raft client.
fn new(
tx: mpsc::UnboundedSender<(raft::Request, oneshot::Sender<Result<raft::Response>>)>,
) -> Self {
Self { tx }
}
/// Executes a request against the Raft cluster.
/// 执行一个请求,创建一个一次性的channel,将channel的发送端交给raft.server,raft server再将request
/// 发送到channeld当中,Raft node就会受到对应的Request,然后在此处阻塞,等待Leader的回应
fn execute(&self, request: raft::Request) -> Result<raft::Response> {
let (response_tx, response_rx) = oneshot::channel();
self.tx.send((request, response_tx))?;
futures::executor::block_on(response_rx)?
}
/// Mutates the Raft state machine, deserializing the response into the
/// return type.
fn mutate<V: DeserializeOwned>(&self, mutation: Mutation) -> Result<V> {
match self.execute(raft::Request::Mutate(bincode::serialize(&mutation)?))? {
raft::Response::Mutate(response) => Ok(bincode::deserialize(&response)?),
resp => Err(Error::Internal(format!("Unexpected Raft mutation response {:?}", resp))),
}
}
/// Queries the Raft state machine, deserializing the response into the
/// return type.
fn query<V: DeserializeOwned>(&self, query: Query) -> Result<V> {
match self.execute(raft::Request::Query(bincode::serialize(&query)?))? {
raft::Response::Query(response) => Ok(bincode::deserialize(&response)?),
resp => Err(Error::Internal(format!("Unexpected Raft query response {:?}", resp))),
}
}
/// Fetches Raft node status.
fn status(&self) -> Result<raft::Status> {
match self.execute(raft::Request::Status)? {
raft::Response::Status(status) => Ok(status),
resp => Err(Error::Internal(format!("Unexpected Raft status response {:?}", resp))),
}
}
}
|
在这一部分,定义了一个Raft结构体,作为Client的Wrapper,并且为Raft实现了engine trait,在地位上与上文的KV Engine相同,用于开启一个事务。
1
2
3
| pub struct Raft {
client: Client,
}
|
Transaction#
这一部分和KV Engine当中的Transaction一样,都是一个Wrapper,在KV Engine中,Transaction作为Wrapper调用了底层MVCC的事务实现,将SQL操作转换成了KV操作。
在Raft Transaction当中,同样是一个Wrapper,封装成各种细化的请求类型通过Client进行发送,类型很多,不一一列举了,Catalog同理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| pub struct Transaction {
client: Client,
state: TransactionState,
}
impl super::Transaction for Transaction {
fn create(&mut self, table: &str, row: Row) -> Result<()> {
self.client.mutate(Mutation::Create {
txn: self.state.clone(),
table: table.to_string(),
row,
})
}
fn delete(&mut self, table: &str, id: &Value) -> Result<()> {
self.client.mutate(Mutation::Delete {
txn: self.state.clone(),
table: table.to_string(),
id: id.clone(),
})
}
fn read(&self, table: &str, id: &Value) -> Result<Option<Row>> {
self.client.query(Query::Read {
txn: self.state.clone(),
table: table.to_string(),
id: id.clone(),
})
}
// ...
}
|
至此,sql engine部分的内容全部介绍完毕,单论某一部分都很简单,没有什么复杂的逻辑,无非是定义了一些trait,和两个wrapper,将MVCC存储和Raft Client封装成SQL事务的模式。这一部分比较复杂的是各个模块之间的交互,和信息传递。在本章的剩余部分,笔者会重点介绍各部分之间是如何进行通信的。
共识粒度#
在toydb当中,sql engine的基本单位为一条事务命令,这里的事务命令指的是在src/sql/engine/mod.rs当中定义的Transaction Trait当中的命令,如create,delete,scan等,或者说,共识的粒度是对存储引擎的一次操作。
到了sql engine这里,实际上是已经没有的SQL的概念的,sql engine只实现了Transaction Trait并对外提供,因此并没有采用一条SQL来作为共识的单位。
更重要的是,相同的SQL在不同的时刻,不同的节点上执行,得到的执行计划,执行结果都有可能是不一样的,即无法保证幂等性,最简单是SELECT NOW()。经过Raft同步到从节点上执行会产生时间差,从而导致执行结果不一致。此外,SQL本身也充满了复杂性包括多表查询、子查询、事务嵌套等,使用SQL进行同步也会为系统引入额外的复杂性。
虽然本系列还没有分析SQL是如何执行的,这里挑一个比较简单的Insert为例,说明一下toydb当中共识的粒度:
- 执行insert时,首先需要读取出当前的table,这里调用了
txn.must_read_table(),作为一条只读请求交给Raft去形成共识 - 之后每插入一行,都会调用
txn.create(),作为一条写请求发送给Raft
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| impl<T: Transaction> Executor<T> for Insert {
fn execute(self: Box<Self>, txn: &mut T) -> Result<ResultSet> {
let table = txn.must_read_table(&self.table)?;
let mut count = 0;
for expressions in self.rows {
let mut row =
expressions.into_iter().map(|expr| expr.evaluate(None)).collect::<Result<_>>()?;
if self.columns.is_empty() {
row = Self::pad_row(&table, row)?;
} else {
row = Self::make_row(&table, &self.columns, row)?;
}
txn.create(&table.name, row)?;
count += 1;
}
Ok(ResultSet::Create { count })
}
}
|
通信方式#
toydb作为一个分布式的关系型数据库,由于引入了Raft,从而导致存在很多网络通信和信息交换的方式,大致类型有:
- 最基础的Client-Server之间的通信,发送sql与执行sql
- Raft Client与Raft Server之间的通信
- Raft Node节点之间的通信
- Raft Node与Raft状态机之间的通信
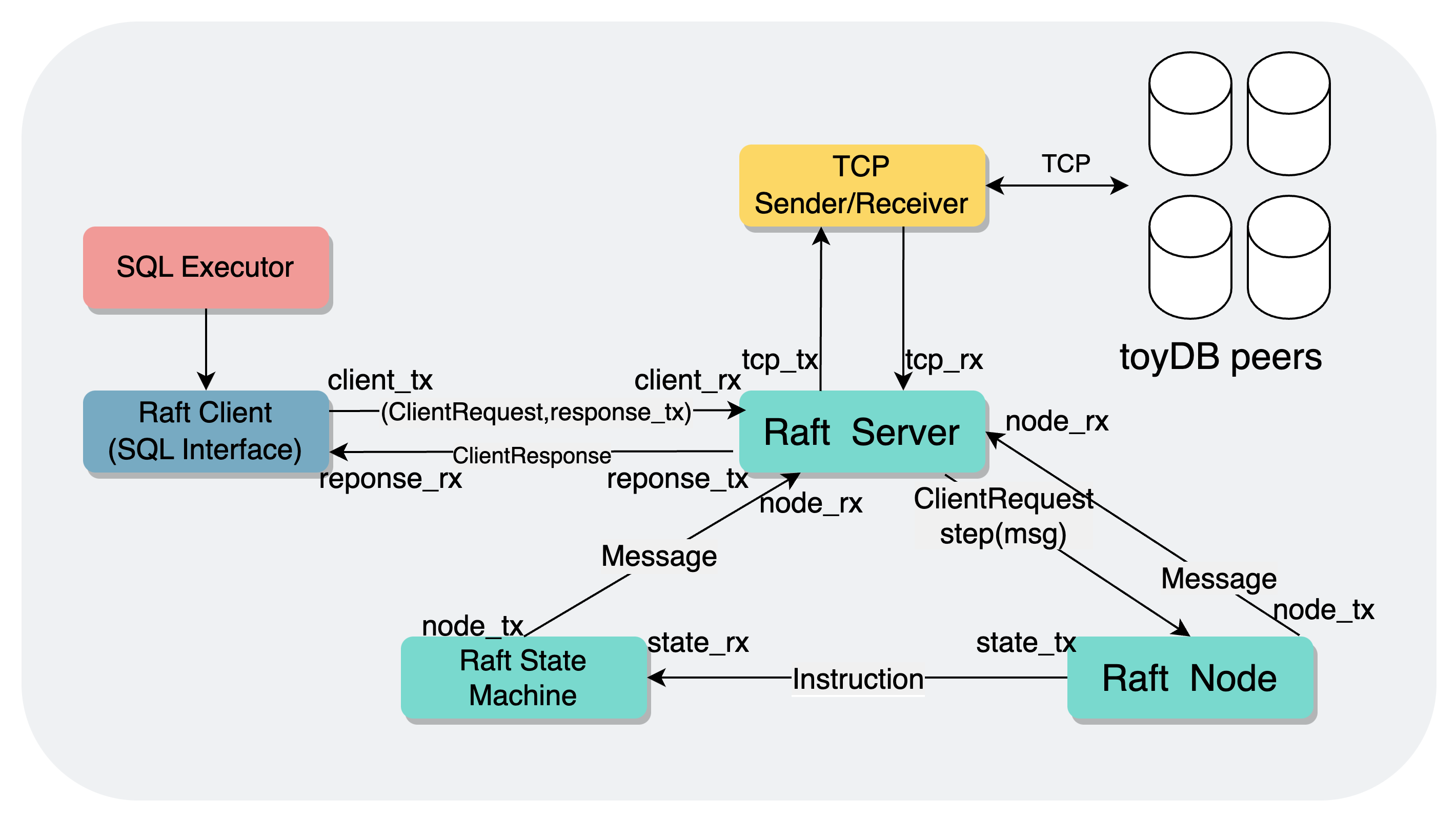
SQL Client-Server#
作为一个Client-Server结构的数据库,最基础的通信就是Client与Server之间的,Client发送sql,Server执行sql。Client与Server显然不会在同一台计算机上运行,二者之间是使用tcp进行连接的。
Client端不是主要的内容,Server端就是监听端口,不断获取请求,然后创建一个Session来执行SQL,之后将结果返回给Client。
这一部分的逻辑定义在src/server.rs当中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /// Serves SQL clients.
async fn serve_sql(listener: TcpListener, engine: sql::engine::Raft) -> Result<()> {
let mut listener = TcpListenerStream::new(listener);
while let Some(socket) = listener.try_next().await? {
let peer = socket.peer_addr()?;
let session = Session::new(engine.clone())?;
tokio::spawn(async move {
info!("Client {} connected", peer);
match session.handle(socket).await {
Ok(()) => info!("Client {} disconnected", peer),
Err(err) => error!("Client {} error: {}", peer, err),
}
});
}
Ok(())
}
|
Server#
剩余三种通信都是属于Server端的内部通信,在toydb当中,通过一个eventloop处理了所有的通信,在创建eventloop时,传入了四个channel:
tcp_tx:raft节点之间相互交流的发送端,用于将底层node塞入信箱当中的Message发送给其他的节点node_rx:node Message消息的接收端,用于从raft模块当中接收Message,然后交给tcp_tx去发送,同时也会处理状态机发送给Raft模块的Messagatcp_rx:raft节点之间相互交流的接收端,接收其他节点传来的Message,然后交给自身的Raft去执行client_rx:接收Raft client发送的Request,交给自身的Raft去执行,达成共识
这一部分的逻辑主体是通过tokio::select!来实现的,在逻辑上与go当中的select是差不多的,只不过go的select是监听同步channel,而tokio::select!是等待异步任务的执行完成,分别从上述的三个channel当中获取Message,推动Raft节点,后续其他三种类型的通信都会依赖于这一部分的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| loop {
tokio::select! {
// 监听ticker,驱动下层Raft,间隔为100ms
_ = ticker.tick() => node = node.tick()?,
// 获取从其他raft节点发送而来的Message,交给下层的Raft去处理
Some(msg) = tcp_rx.next() => node = node.step(msg)?,
// 获取下层Raft放入信箱的Message,发送给对应的节点
Some(msg) = node_rx.next() => {
match msg {
Message{to: Address::Node(_), ..} => tcp_tx.send(msg)?,
Message{to: Address::Broadcast, ..} => tcp_tx.send(msg)?,
Message{to: Address::Client, event: Event::ClientResponse{ id, response }, ..} => {
if let Some(response_tx) = requests.remove(&id) {
response_tx
.send(response)
.map_err(|e| Error::Internal(format!("Failed to send response {:?}", e)))?;
}
}
_ => return Err(Error::Internal(format!("Unexpected message {:?}", msg))),
}
}
// 获取client发送的消息,交给Raft模块去处理,这里的client并不是用户的client,而是要执行命令的sql端
Some((request, response_tx)) = client_rx.next() => {
let id = Uuid::new_v4().as_bytes().to_vec();
let msg = Message{
from: Address::Client,
to: Address::Node(node.id()),
term: 0,
event: Event::ClientRequest{id: id.clone(), request},
};
node = node.step(msg)?;
requests.insert(id, response_tx);
}
}
}
|
Raft Client-Server#
Client
Raft Client的定义在src/sql/engine/raft.rs当中Client当中只有一个字段tx,为一个消息类型为(raft::Request, oneshot::Sender<Result<raft::Response>)的channel发送端,使用这个给Raft Server发送消息。
tx的来源为在Server.serve()中创建:
raft_tx为raft client-server之间消息的发送端,交给sql engine去发送raft_rx为raft client-server之间消息的接收端,交给raft server去接收,raft_rx在server端被重命名为client_rx。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| struct Client {
// 这里的tx为raft_tx,raft_server那边拿到的为raft_rx,raft_rx在Raft模块当中被重命名为client_rx
// 所以这里的tx对应的是client_tx
tx: mpsc::UnboundedSender<(raft::Request, oneshot::Sender<Result<raft::Response>>)>,
}
pub async fn serve(self) -> Result<()> {
// listener
// ...
// raft_tx为raft client-server之间消息的发送端,交给sql_engine去发送
// raft_rx为raft client-server之间消息的接收端,交给raft server去收
let (raft_tx, raft_rx) = mpsc::unbounded_channel();
let sql_engine = sql::engine::Raft::new(raft_tx);
tokio::try_join!(
self.raft.serve(raft_listener, raft_rx),
Self::serve_sql(sql_listener, sql_engine),
)?;
Ok(())
}
|
读写请求都会调用execute()来向Raft Server去通信。在execute()当中,会调用oneshot::channel()创建一个一次性的channel,将channel的消息发送端response_tx和request一同发送给Raft Server。
Server接收并执行完之后,会使用传过去的发送端再将响应发送回来,Client等待从接收端获取消息,拿到Raft Server对request的执行结果向上返回。此时,创建的oneshot channel就可以销毁了。
Server
接收:
Server端的接收逻辑就在上面所说的eventloop当中,从client_rx(上面传来的raft_rx)接收到Client发送的request和response_tx。
由于请求需要先通过Raft完成共识,之后Apply了才能够执行,这里先使用一个HashMap保存请求,等到Apply并执行完之后再从HashMap中获取出暂存的response_rx,再响应Client。
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 获取client发送的消息,交给Raft模块去处理,这里的client并不是用户的client,而是要执行命令的sql端
// 暂存命令,等到日志Apply并执行完之后再响应客户端
Some((request, response_tx)) = client_rx.next() => {
let id = Uuid::new_v4().as_bytes().to_vec();
let msg = Message{
from: Address::Client,
to: Address::Node(node.id()),
term: 0,
event: Event::ClientRequest{id: id.clone(), request},
};
node = node.step(msg)?;
requests.insert(id, response_tx);
}
|
发送:
在Raft状态机当中,当请求Apply时,就会发送一条消息给Raft Leader Node,写请求通过notify_applied(),读请求通过query_execute(),通知Leader目前该命令已经Apply,并且执行完成,可以响应Client了,这一部分的逻辑定义在src/raft/state.rs中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| pub fn apply(&mut self, state: &mut dyn State, entry: Entry) -> Result<Index> {
// Apply the command.
debug!("Applying {:?}", entry);
match state.apply(entry) {
Err(error @ Error::Internal(_)) => return Err(error),
result => self.notify_applied(state.get_applied_index(), result)?,
};
// Try to execute any pending queries, since they may have been submitted for a
// commit_index which hadn't been applied yet.
self.query_execute(state)?;
Ok(state.get_applied_index())
}
/// Notifies a client about an applied log entry, if any.
fn notify_applied(&mut self, index: Index, result: Result<Vec<u8>>) -> Result<()> {
if let Some((to, id)) = self.notify.remove(&index) {
self.send(to, Event::ClientResponse { id, response: result.map(Response::Mutate) })?;
}
Ok(())
}
/// Executes any queries that are ready.
fn query_execute(&mut self, state: &mut dyn State) -> Result<()> {
for query in self.query_ready(state.get_applied_index()) {
debug!("Executing query {:?}", query.command);
let result = state.query(query.command);
if let Err(error @ Error::Internal(_)) = result {
return Err(error);
}
self.send(
query.address,
Event::ClientResponse { id: query.id, response: result.map(Response::Query) },
)?
}
Ok(())
}
|
当Leader接收到了Event::ClientResponse之后,不会做额外处理,设置接收端的地址为Client,直接发送塞入到信箱(node_tx),交给上层Server去发送,这一部分的逻辑定义在src/raft/leader.rs中:
1
2
3
4
5
6
| Event::ClientResponse { id, mut response } => {
if let Ok(Response::Status(ref mut status)) = response {
status.server = self.id;
}
self.send(Address::Client, Event::ClientResponse { id, response })?;
}
|
Message塞入到node_tx中,自然就会在Server中被node_rx接收到,根据发送端到地址匹配处理,如果是Address::Client,那么就获取并删除当时存入的那个response_tx,通过response_tx将执行结果发送给Raft Client。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // 获取下层Raft放入信箱的Message,发送给对应的节点
Some(msg) = node_rx.next() => {
match msg {
Message{to: Address::Node(_), ..} => tcp_tx.send(msg)?,
Message{to: Address::Broadcast, ..} => tcp_tx.send(msg)?,
Message{to: Address::Client, event: Event::ClientResponse{ id, response }, ..} => {
if let Some(response_tx) = requests.remove(&id) {
response_tx
.send(response)
.map_err(|e| Error::Internal(format!("Failed to send response {:?}", e)))?;
}
}
_ => return Err(Error::Internal(format!("Unexpected message {:?}", msg))),
}
}
|
至此,Raft Client-Server完成了一次完整的通信过程。
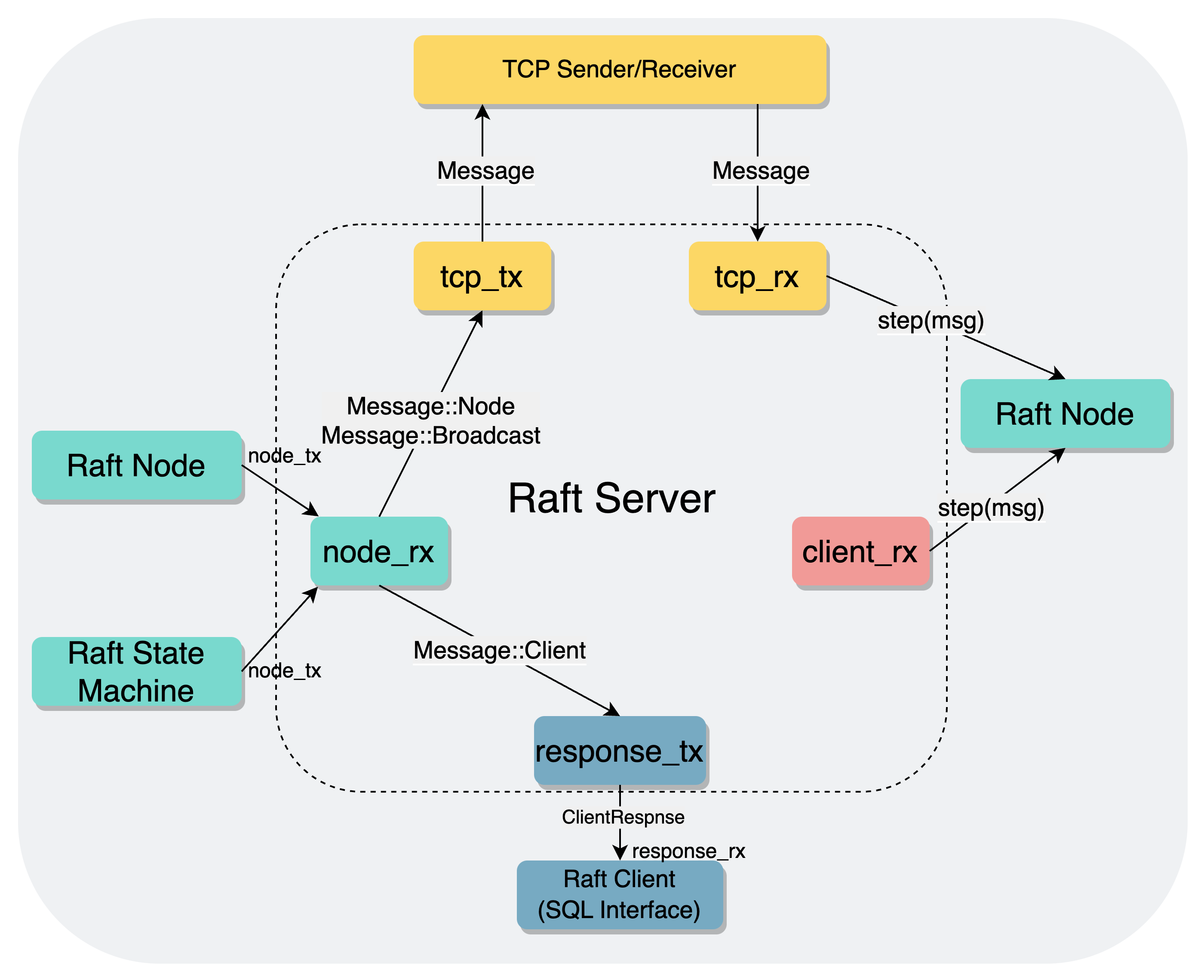
Raft Node#
这一部分是Raft模块中各个节点之间的通信,对应6.824当中的直接调用AppendEntries,RequsetVoteRPC的过程,只不过在toydb中使用Message处理信息交换,因此就是发送Message。
Raft节点如果需要发送一条Message,那么就调用send,将其塞入到node_tx当中,交给Server去发送,比如进行heartbeat时,就传入一个接收地址为Address::Broadcast,消息类型为Event::Heartbeat的Message,表示要将心跳信息进行广播
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| /// Broadcasts a heartbeat to all peers.
pub(super) fn heartbeat(&mut self) -> Result<()> {
let (commit_index, commit_term) = self.log.get_commit_index();
self.send(Address::Broadcast, Event::Heartbeat { commit_index, commit_term })?;
// NB: We don't reset self.since_heartbeat here, because we want to send
// periodic heartbeats regardless of any on-demand heartbeats.
Ok(())
}
/// Sends an event
fn send(&self, to: Address, event: Event) -> Result<()> {
let msg = Message { term: self.term, from: Address::Node(self.id), to, event };
debug!("Sending {:?}", msg);
Ok(self.node_tx.send(msg)?)
}
|
这一部分的发送逻辑和上面有些重合,同样是在eventloop中从node_rx获取Message,再把Message传入到tcp_tx中,准备进行发送。
和eventloop一同启动的还有一个tcp_sender的task,在其中,又将Message经历了一次在channel中的发送和接收,最终调用到tcp_send_peer(),将Message通过tcp发送给对应的Raft Node
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| async fn tcp_send(
peers: HashMap<NodeID, String>,
out_rx: mpsc::UnboundedReceiver<Message>,
) -> Result<()> {
let mut out_rx = UnboundedReceiverStream::new(out_rx);
let mut peer_txs: HashMap<NodeID, mpsc::Sender<Message>> = HashMap::new();
for (id, addr) in peers.into_iter() {
let (tx, rx) = mpsc::channel::<Message>(1000);
peer_txs.insert(id, tx);
tokio::spawn(Self::tcp_send_peer(addr, rx));
}
while let Some(message) = out_rx.next().await {
let to = match message.to {
Address::Broadcast => peer_txs.keys().copied().collect(),
Address::Node(peer) => vec![peer],
addr => {
error!("Received outbound message for non-TCP address {:?}", addr);
continue;
}
};
for id in to {
match peer_txs.get_mut(&id) {
Some(tx) => match tx.try_send(message.clone()) {
Ok(()) => {}
Err(mpsc::error::TrySendError::Full(_)) => {
debug!("Full send buffer for peer {}, discarding message", id)
}
Err(error) => return Err(error.into()),
},
None => error!("Received outbound message for unknown peer {}", id),
}
}
}
Ok(())
}
/// Sends outbound messages to a peer, continuously reconnecting.
async fn tcp_send_peer(addr: String, out_rx: mpsc::Receiver<Message>) {
let mut out_rx = ReceiverStream::new(out_rx);
loop {
match TcpStream::connect(&addr).await {
Ok(socket) => {
debug!("Connected to Raft peer {}", addr);
match Self::tcp_send_peer_session(socket, &mut out_rx).await {
Ok(()) => break,
Err(err) => error!("Failed sending to Raft peer {}: {}", addr, err),
}
}
Err(err) => error!("Failed connecting to Raft peer {}: {}", addr, err),
}
tokio::time::sleep(Duration::from_millis(1000)).await;
}
debug!("Disconnected from Raft peer {}", addr);
}
|
Raft Node & State Machine#
Raft节点与状态机之间是通过state_rx,state_tx,node_tx,node_rx进行交互的:
- Raft节点通过
state_tx中向状态机发送Instruction,从node_rx中接收状态机发送的Message - Raft状态机从
state_rx中接收Raft节点发送的Instruction,通过node_tx向Raft节点发送Message,状态机。通过node_tx发送的消息最后会和其他的Message一样,走一遍tcp的流程,最后又传到的当前的节点,然后调用step()交给Leader
Raft节点发送与接收:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| // Raft节点发送:commit时通过state_tx向状态机发送Instruction
fn maybe_commit(&mut self) -> Result<Index> {
// ...
// ...
if commit_index > prev_commit_index {
self.log.commit(commit_index)?;
// TODO: Move application elsewhere, but needs access to applied index.
let mut scan = self.log.scan((prev_commit_index + 1)..=commit_index)?;
while let Some(entry) = scan.next().transpose()? {
self.state_tx.send(Instruction::Apply { entry })?;
}
}
}
// Raft节点接收:接收状态机发送的Message,走一遍tcp发送回当前节点,调用step去处理
Some(msg) = node_rx.next() => {
match msg {
Message{to: Address::Node(_), ..} => tcp_tx.send(msg)?,
Message{to: Address::Broadcast, ..} => tcp_tx.send(msg)?,
Message{to: Address::Client, event: Event::ClientResponse{ id, response }, ..} => {
if let Some(response_tx) = requests.remove(&id) {
response_tx
.send(response)
.map_err(|e| Error::Internal(format!("Failed to send response {:?}", e)))?;
}
}
_ => return Err(Error::Internal(format!("Unexpected message {:?}", msg))),
}
}
|
状态机发送与接收:
状态机是通过Driver.drive()进行驱动的,会不断地从state_rx中获取Raft节点发送而来的Instruction,然后进行执行,发送逻辑在之前介绍过了,传入到node_tx中即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 状态机接收:
/// Drives a state machine.
pub async fn drive(mut self, mut state: Box<dyn State>) -> Result<()> {
debug!("Starting state machine driver at applied index {}", state.get_applied_index());
while let Some(instruction) = self.state_rx.next().await {
if let Err(error) = self.execute(instruction, &mut *state) {
error!("Halting state machine due to error: {}", error);
return Err(error);
}
}
debug!("Stopping state machine driver");
Ok(())
}
// 状态机发送:
fn send(&self, to: Address, event: Event) -> Result<()> {
// TODO: This needs to use the correct term.
let msg = Message { from: Address::Node(self.node_id), to, term: 0, event };
debug!("Sending {:?}", msg);
Ok(self.node_tx.send(msg)?)
}
|
在这一部分,主要完成了一个组装的过程,将MVCC存储引擎与Raft结合,为SQL的执行提供支持。在这种模式下,在算子中调用提供的Transaction接口,就会先通过Raft Client将请求发送给Raft Server,等待Apply之后再调用MVCC存储引擎去执行,最后依次响应,返回到算子当中。结束一次执行。
除此之外,补全了Raft状态机的实现和节点间的通信这一部分涉及到多个channel和tcp通信,同一节点上的命令可以使用channel发送,不同节点之间使用tcp发送,虽然没有直接调用rpc直观,但是结构上更加清晰,易于管理。