toydb的Raft实现,相比于6.824更接近于生产级别的,和etcd/raft在结构上比较相似,但是并没有实现Raft大论文当中的优化,并且相比Raft小论文也砍掉了一些优化,比如fast backup,snapshot等。不过在写法上还是很有rust的味道的。可以分为一下几个模块:
- Node:分别定义Leader、Candidate、Follower各自的行为和通用的行为(定义在mod.rs当中)
- log:以kv engine作为底层,持久化存储Raft的log,同时也会用于持久化存储元数据,所有需要进行持久化存储的都会使用log模块
- State:Raft状态机,构建于Raft之上,相当于6.824当中的Lab3
- Server:通信模块,负责与其他Raft节点之间进行通信,基于tcp实现
在本章当中,笔者会首先分析toydb当中的Raft的一些基础模块,之后再按照选举和日志复制的逻辑来进行分析Raft的逻辑。对于Raft本身,笔者不会做过多介绍,如果想了解Raft本身建议看Raft小论文/大论文,6.824
- raft.pdf
- web.stanford.edu/~ouster/cgi-bin/papers/OngaroPhD.pdf
Message#
在toydb当中,Raft模块使用Event作为事件的载体,而Message为Event的封装,整个Raft的执行过程就是不断处理Message的过程,这与etcd当中的设计非常相似,所以先来看一下Message相关内容,定义在src/raft/message.rs当中。
Message的发送目标采用一个枚举来表示
- Broadcast:为广播类型,需要发送给所有的节点
- Node:为单独发送,指定NodeID,在上层网络模块再转换成ip进行发送
- Client:用于回复Client
1
2
3
4
5
6
7
8
9
10
11
| #[derive(Clone, Copy, Debug, Eq, Hash, PartialEq, Serialize, Deserialize)]
pub enum Address {
/// Broadcast to all peers. Only valid as an outbound recipient (to).
Broadcast,
/// A node with the specified node ID (local or remote). Valid both as
/// sender and recipient.
Node(NodeID),
/// A local client. Can only send ClientRequest messages, and receive
/// ClientResponse messages.
Client,
}
|
Message定义为一个结构体,其中包含发送Message时的Term,发送方与接收方,以及Event
1
2
3
4
5
6
7
8
9
10
11
12
13
| /// A message passed between Raft nodes.
#[derive(Clone, Debug, PartialEq, Serialize, Deserialize)]
pub struct Message {
/// The current term of the sender. Must be set, unless the sender is
/// Address::Client, in which case it must be 0.
pub term: Term,
/// The sender address.
pub from: Address,
/// The recipient address.
pub to: Address,
/// The message payload.
pub event: Event,
}
|
Message的主体是Event,Event定义为一个枚举类型,在其中表示了Raft当中的所有事件,如果需要额外的信息,就封装成一个结构体,否则设置成一个枚举字段即可。如心跳信息,candidate开启选举等等,在代码当中每一种类型都给出了详细的注释,读者可自行阅读
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| #[derive(Clone, Debug, PartialEq, Serialize, Deserialize)]
pub enum Event {
/// Leaders send periodic heartbeats to its followers.
Heartbeat {
/// The index of the leader's last committed log entry.
commit_index: Index,
/// The term of the leader's last committed log entry.
commit_term: Term,
},
/// Followers confirm loyalty to leader after heartbeats.
ConfirmLeader {
/// The commit_index of the original leader heartbeat, to confirm
/// read requests.
commit_index: Index,
/// If false, the follower does not have the entry at commit_index
/// and would like the leader to replicate it.
has_committed: bool,
},
/// Candidates solicit votes from all peers when campaigning for leadership.
SolicitVote {
// The index of the candidate's last stored log entry
last_index: Index,
// The term of the candidate's last stored log entry
last_term: Term,
},
/// Followers may grant a single vote to a candidate per term, on a
/// first-come basis. Candidates implicitly vote for themselves.
GrantVote,
/// Leaders replicate log entries to followers by appending it to their log.
AppendEntries {
/// The index of the log entry immediately preceding the submitted commands.
base_index: Index,
/// The term of the log entry immediately preceding the submitted commands.
base_term: Term,
/// Commands to replicate.
entries: Vec<Entry>,
},
/// Followers may accept a set of log entries from a leader.
AcceptEntries {
/// The index of the last log entry.
last_index: Index,
},
/// Followers may also reject a set of log entries from a leader.
RejectEntries,
/// A client request. This can be submitted to the leader, or to a follower
/// which will forward it to its leader. If there is no leader, or the
/// leader or term changes, the request is aborted with an Error::Abort
/// ClientResponse and the client must retry.
ClientRequest {
/// The request ID. This is arbitrary, but must be globally unique for
/// the duration of the request.
id: RequestID,
/// The request.
request: Request,
},
/// A client response.
ClientResponse {
/// The response ID. This matches the ID of the ClientRequest.
id: RequestID,
/// The response, or an error.
response: Result<Response>,
},
}
|
对比一下etcd当中的Message类型,在rust当中使用enum Event进行封装是不是简洁很多呢,event同一事件只会有一种类型和数据,避免携带不必要的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| type Message struct {
Type MessageType `protobuf:"varint,1,opt,name=type,enum=raftpb.MessageType" json:"type"`
To uint64 `protobuf:"varint,2,opt,name=to" json:"to"`
From uint64 `protobuf:"varint,3,opt,name=from" json:"from"`
Term uint64 `protobuf:"varint,4,opt,name=term" json:"term"`
// logTerm is generally used for appending Raft logs to followers. For example,
// (type=MsgApp,index=100,logTerm=5) means leader appends entries starting at
// index=101, and the term of entry at index 100 is 5.
// (type=MsgAppResp,reject=true,index=100,logTerm=5) means follower rejects some
// entries from its leader as it already has an entry with term 5 at index 100.
LogTerm uint64 `protobuf:"varint,5,opt,name=logTerm" json:"logTerm"`
Index uint64 `protobuf:"varint,6,opt,name=index" json:"index"`
Entries []Entry `protobuf:"bytes,7,rep,name=entries" json:"entries"`
Commit uint64 `protobuf:"varint,8,opt,name=commit" json:"commit"`
Snapshot Snapshot `protobuf:"bytes,9,opt,name=snapshot" json:"snapshot"`
Reject bool `protobuf:"varint,10,opt,name=reject" json:"reject"`
RejectHint uint64 `protobuf:"varint,11,opt,name=rejectHint" json:"rejectHint"`
Context []byte `protobuf:"bytes,12,opt,name=context" json:"context,omitempty"`
}
|
Node#
Node这一部分表示在Raft运行过程中,Raft节点的角色和执行动作,在这一部分仅简单介绍涉及到的结构体,而执行逻辑分为选举和日志复制两部分进行分析。
toydb当中使用RoleNode来表示节点的状态和角色,其中:
- log为一个与kv engine交互的模块,负责所有持久化存储的工作
- node_tx用于进行节点之间的通信(节点之间真实传输使用的是tcp,这个mpsc更像是一个信箱,将Message添加到其中,等待之后发送,这一部分的设计也与etcd相同,不过etcd是一个批处理的形式,会攒一波消息一同发送)
- state_tx用于与上层状态机进行通信
1
2
3
4
5
6
7
8
9
10
| // A Raft node with role R
pub struct RoleNode<R> {
id: NodeID,
peers: HashSet<NodeID>,
term: Term,
log: Log,
node_tx: mpsc::UnboundedSender<Message>,
state_tx: mpsc::UnboundedSender<Instruction>,
role: R,
}
|
Role代表当前节点的角色,分别有Leader、Candidate、Follower,封装了一些每种不同角色特有的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
pub struct Leader {
/// Peer replication progress.
progress: HashMap<NodeID, Progress>,
/// Number of ticks since last periodic heartbeat.
since_heartbeat: Ticks,
}
pub struct Follower {
/// The leader, or None if just initialized.
leader: Option<NodeID>,
/// The number of ticks since the last message from the leader.
leader_seen: Ticks,
/// The leader_seen timeout before triggering an election.
election_timeout: Ticks,
/// The node we voted for in the current term, if any.
voted_for: Option<NodeID>,
// Local client requests that have been forwarded to the leader. These are
// aborted on leader/term changes.
pub(super) forwarded: HashSet<RequestID>,
}
pub struct Candidate {
/// Votes received (including ourself).
votes: HashSet<NodeID>,
/// Ticks elapsed since election start.
election_duration: Ticks,
/// Election timeout, in ticks.
election_timeout: Ticks,
}
|
在RoleNode当中,配备了几个基础的函数,后面流程中可能用到,先提一下,都比较简单:
become_role():切换角色,更新rolequorum():计算集群“大多数”的数量send():将Message塞入信箱当中,之后会被读取并发送assert_node():检查当前的term与持久化存储的term是否相同assert_step():在step函数处理Message之前先对Message进行校验- 检查Message的接收方:判断是否应该由当前节点处理,step函数不应该处理发送给client的Message和不属于自己的Message
- 检查Message的发送方:不应该有Broadcast类型的发送方,Broadcast只应该作为接收方存在;对client发送的Message进行检查;检查由其他节点发送而来的消息,该节点是妇女存在于集群当中,以及需要携带term
角色切换#
Leader
Leader只有一种角色切换,即接收到更高的term从而退位,转换成follower,定义在RoleNode<Leader>.become_follower()当中,由于因为检测到更高的term,因此需要更新自身的term并进行持久化的工作:
1
2
3
4
5
6
7
8
9
10
11
12
| /// Transforms the leader into a follower. This can only happen if we find a
/// new term, so we become a leaderless follower.
fn become_follower(mut self, term: Term) -> Result<RoleNode<Follower>> {
assert!(term >= self.term, "Term regression {} -> {}", self.term, term);
assert!(term > self.term, "Can only become follower in later term");
info!("Discovered new term {}", term);
self.term = term;
self.log.set_term(term, None)?;
self.state_tx.send(Instruction::Abort)?;
Ok(self.become_role(Follower::new(None, None)))
}
|
Candidate
candidate在输掉选举之后或者接收到更高的Term就会转换为Follower:
- 在输掉选举时,会接收到新的Leader的Heartbeat,因此可以知道新的Leader是谁,更新自身状态时将当前的Leader保存
- 接收到更高Term时,有可能只是其他进度更新的Follower给予的回应,因此无法得知Leader是谁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| /// Transforms the node into a follower. We either lost the election
/// and follow the winner, or we discovered a new term in which case
/// we step into it as a leaderless follower.
fn become_follower(mut self, term: Term, leader: Option<NodeID>) -> Result<RoleNode<Follower>> {
assert!(term >= self.term, "Term regression {} -> {}", self.term, term);
if let Some(leader) = leader {
// We lost the election, follow the winner.
assert_eq!(term, self.term, "Can't follow leader in different term");
info!("Lost election, following leader {} in term {}", leader, term);
let voted_for = Some(self.id); // by definition
Ok(self.become_role(Follower::new(Some(leader), voted_for)))
} else {
// We found a new term, but we don't necessarily know who the leader
// is yet. We'll find out when we step a message from it.
assert_ne!(term, self.term, "Can't become leaderless follower in current term");
info!("Discovered new term {}", term);
self.term = term;
self.log.set_term(term, None)?;
Ok(self.become_role(Follower::new(None, None)))
}
}
|
candidate如果能够成功当选,那么就可以转换为Leader,上线之后发送心跳信息并且追加一条non-op,,追加的non-op的原因在raft论文当中作出了解释,这里简单提一下,Raft不能够提交自己任期以外的日志,只能够在提交当前任期的日志时顺带提交之前的日志,否则会出现提交日志被覆盖的安全性问题(具体样例见论文figure 8),如果开启read index线性一致性读优化的情况下,系统如果不收到写请求就无法提交之前的日志,从而阻塞系统状态(读写都会被阻塞,read index 需要Leader在当前任期提交过日志之后才能执行),non-op可以尽快恢复系统状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
| /// Transition to leader role.
fn become_leader(self) -> Result<RoleNode<Leader>> {
info!("Won election for term {}, becoming leader", self.term);
let peers = self.peers.clone();
let (last_index, _) = self.log.get_last_index();
let mut node = self.become_role(Leader::new(peers, last_index));
node.heartbeat()?;
// Propose an empty command when assuming leadership, to disambiguate
// previous entries in the log. See section 8 in the Raft paper.
node.propose(None)?;
Ok(node)
}
|
Follower
Follower在选举超时时会转换为Candidate,并且调用compaign()开始选举。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| fn become_candidate(mut self) -> Result<RoleNode<Candidate>> {
// Abort any forwarded requests. These must be retried with new leader.
self.abort_forwarded()?;
let mut node = self.become_role(Candidate::new());
node.campaign()?;
Ok(node)
}
/// Processes a logical clock tick.
pub fn tick(mut self) -> Result<Node> {
self.assert()?;
self.role.leader_seen += 1;
if self.role.leader_seen >= self.role.election_timeout {
return Ok(self.become_candidate()?.into());
}
Ok(self.into())
}
|
Follower在接受到Leader的Heartbeat、AppendEntries时,或者更高的Term的消息时,都会更新自身状态进行跟随
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| /// Transforms the node into a follower, either a leaderless follower in a
/// new term or following a leader in the current term.
fn become_follower(mut self, leader: Option<NodeID>, term: Term) -> Result<RoleNode<Follower>> {
assert!(term >= self.term, "Term regression {} -> {}", self.term, term);
// Abort any forwarded requests. These must be retried with new leader.
self.abort_forwarded()?;
if let Some(leader) = leader {
// We found a leader in the current term.
assert_eq!(self.role.leader, None, "Already have leader in term");
assert_eq!(term, self.term, "Can't follow leader in different term");
info!("Following leader {} in term {}", leader, term);
self.role = Follower::new(Some(leader), self.role.voted_for);
} else {
// We found a new term, but we don't necessarily know who the leader
// is yet. We'll find out when we step a message from it.
assert_ne!(term, self.term, "Can't become leaderless follower in current term");
info!("Discovered new term {}", term);
self.term = term;
self.log.set_term(term, None)?;
self.role = Follower::new(None, None);
}
Ok(self)
}
|
消息转发#
在toydb当中,Follower是允许和Client通信的,但是不能够处理信息,Follower需要将消息转发给Leader,Leader处理完之后再由Follower响应Client,这一部分的逻辑在follower.step()当中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| // Forward client requests to the leader, or abort them if there is
// none (the client must retry).
Event::ClientRequest { ref id, .. } => {
if msg.from != Address::Client {
error!("Received client request from non-client {:?}", msg.from);
return Ok(self.into());
}
let id = id.clone();
if let Some(leader) = self.role.leader {
debug!("Forwarding request to leader {}: {:?}", leader, msg);
self.role.forwarded.insert(id);
self.send(Address::Node(leader), msg.event)?
} else {
self.send(msg.from, Event::ClientResponse { id, response: Err(Error::Abort) })?
}
}
// Returns client responses for forwarded requests.
// 接收到client的消息之后,转发给leader,leader处理完之后再回应follower
// 之后继续由follower去响应给client,这里为什么不告知client 真正的Leader是什么?
Event::ClientResponse { id, mut response } => {
if !self.is_leader(&msg.from) {
error!("Received client response from non-leader {:?}", msg.from);
return Ok(self.into());
}
// TODO: Get rid of this field, it should be returned at the RPC
// server level instead.
if let Ok(Response::Status(ref mut status)) = response {
status.server = self.id;
}
// 处理完就可以从请求队列当中移除,并且响应Client
// 请求队列是用于记录Follower接收到并且未处理完的ClientRequest,用于在通知Leader时,就可以将这些未处理的请求全部告知Client,让其找到Leader再去重新执行
if self.role.forwarded.remove(&id) {
self.send(Address::Client, Event::ClientResponse { id, response })?;
}
}
|
不过Follower既然已经转发给Leader并且正确得到回应,那么就说明Follower知道Leader是谁了,此时回复Client时可以告知Client当前节点不是Leader,之后Client就可以找Leader去通信,但是toydb并没有这样实现,告知Client当前身份这个过程在toydb当中进行了单独的封装:
在Follower能够确认Leader时,如从Leader处接收到Heartbeat和AppendEntries时,就会调用上文的follower.become_follower()重置状态,在这个函数里面,会调用一个abort_forwarded(),在其中,会使用std::mem::take将role.forwarded给重置,并且遍历其中未处理的消息,依次告知Error,之后Client再进行重试。
1
2
3
4
5
6
7
8
| /// Aborts all forwarded requests.
fn abort_forwarded(&mut self) -> Result<()> {
for id in std::mem::take(&mut self.role.forwarded) {
debug!("Aborting forwarded request {:x?}", id);
self.send(Address::Client, Event::ClientResponse { id, response: Err(Error::Abort) })?;
}
Ok(())
}
|
初始化#
在toydb启动时,会调用Server::new()来创建一个server节点,在其中,一部分初始化与client进行通信,而另一部分则是初始化raft节点,初始化完成之后就会调用serve来提供网络服务,其中会调用到raft.serve()来启动raft节点:
1
2
3
4
5
6
7
| // toydb.rs main
Server::new(cfg.id, cfg.peers, raft_log, raft_state)
.await?
.listen(&cfg.listen_sql, &cfg.listen_raft)
.await?
.serve()
.await
|
在raft.serve()当中,就会调用raft.eventloop()正式启动raft接收和处理事件,在eventloop当中,传入了一个channel的发送端,创建了三个channel:
- tcp_tx:raft节点之间相互交流的发送端,用于将底层node塞入信箱当中的Message发送给其他的节点
- node_rx:node Message消息的接收端,用于从下层的raft当中接收Message,然后交给tcp_tx去发送
- tcp_rx:raft节点之间相互交流的接收端,接收其他节点传来的Message,然后交给自身的Raft去执行
- Client_rx: 接收 client 发送的 Message,交给自身的 Raft 去执行,这里的 client 并不是用户的 client,而是要执行命令的 sql 端,sql 端对于要执行的命令,首先会交给 Raft 来进行共识,这个过程是以 client-server 结构来执行的,sql 端充当 client,raft-server 充当 server。
这一部分的逻辑主体是通过tokio::select!来实现的,在逻辑上与go当中的select是差不多的,只不过go的select是监听同步channel,而tokio::select!是等待异步任务的执行完成,分别从上述的三个channel当中获取Message,推动Raft节点。
除了channel的通信之外,select当中还有一个Ticker,以100ms的间隔运行,用于将物理时钟转换为逻辑时钟,提供给下层,驱动Raft。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| /// Runs the event loop.
async fn eventloop(
mut node: Node,
node_rx: mpsc::UnboundedReceiver<Message>,
client_rx: mpsc::UnboundedReceiver<(Request, oneshot::Sender<Result<Response>>)>,
tcp_rx: mpsc::UnboundedReceiver<Message>,
tcp_tx: mpsc::UnboundedSender<Message>,
) -> Result<()> {
let mut node_rx = UnboundedReceiverStream::new(node_rx);
let mut tcp_rx = UnboundedReceiverStream::new(tcp_rx);
let mut client_rx = UnboundedReceiverStream::new(client_rx);
let mut ticker = tokio::time::interval(TICK_INTERVAL);
let mut requests = HashMap::<Vec<u8>, oneshot::Sender<Result<Response>>>::new();
loop {
tokio::select! {
// 监听ticker,驱动下层Raft,间隔为100ms
_ = ticker.tick() => node = node.tick()?,
// 获取从其他raft节点发送而来的Message,交给下层的Raft去处理
Some(msg) = tcp_rx.next() => node = node.step(msg)?,
// 获取下层Raft放入信箱的Message,发送给对应的节点
Some(msg) = node_rx.next() => {
match msg {
Message{to: Address::Node(_), ..} => tcp_tx.send(msg)?,
Message{to: Address::Broadcast, ..} => tcp_tx.send(msg)?,
Message{to: Address::Client, event: Event::ClientResponse{ id, response }, ..} => {
if let Some(response_tx) = requests.remove(&id) {
response_tx
.send(response)
.map_err(|e| Error::Internal(format!("Failed to send response {:?}", e)))?;
}
}
_ => return Err(Error::Internal(format!("Unexpected message {:?}", msg))),
}
}
// 获取client发送的消息,交给下层去处理,这里的client并不是用户的client,而是要执行命令的sql端
Some((request, response_tx)) = client_rx.next() => {
let id = Uuid::new_v4().as_bytes().to_vec();
let msg = Message{
from: Address::Client,
to: Address::Node(node.id()),
term: 0,
event: Event::ClientRequest{id: id.clone(), request},
};
node = node.step(msg)?;
requests.insert(id, response_tx);
}
}
}
}
|
Leader Election#
Raft的选举过程受到Ticker的驱动,如上面所展示的,上层server层会以100ms为间隔将物理时钟转换为逻辑时钟,下层的tick()定义在mod.rs当中,对于不同角色的节点,分别调用对应的tick(),在选举当中,对应的就是Follower的tick():
1
2
3
4
5
6
7
8
9
| /// Moves time forward by a tick.
pub fn tick(self) -> Result<Self> {
match self {
Node::Candidate(n) => n.tick(),
Node::Follower(n) => n.tick(),
Node::Leader(n) => n.tick(),
}
}
|
在Follower的tick()当中,增大election_duration,如果超出了限制,就转换为candidate,开启选举,选举的入口为self.compaign(),这与etcd/raft的实现是一致的。
在toydb当中设置的是10-20个逻辑时钟,即1-2s的随机时间,这里比论文当中(150ms-300ms)设置的长很多,和etcd设置一致。但是toydb的heartbeat为3个逻辑时钟,所以其实也不会有太大的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| /// The interval between leader heartbeats, in ticks.
const HEARTBEAT_INTERVAL: Ticks = 3;
/// The randomized election timeout range (min-max), in ticks. This is
/// randomized per node to avoid ties.
const ELECTION_TIMEOUT_RANGE: std::ops::Range<u8> = 10..20;
// Follower.tick,转换为candidate
pub fn tick(mut self) -> Result<Node> {
self.assert()?;
self.role.leader_seen += 1;
if self.role.leader_seen >= self.role.election_timeout {
return Ok(self.become_candidate()?.into());
}
Ok(self.into())
}
// 转换为candidate之后会立刻开始选举
/// Transforms the node into a candidate, by campaigning for leadership in a
/// new term.
fn become_candidate(mut self) -> Result<RoleNode<Candidate>> {
// Abort any forwarded requests. These must be retried with new leader.
self.abort_forwarded()?;
let mut node = self.become_role(Candidate::new());
node.campaign()?;
Ok(node)
}
// Candidate.tick,在第一次选举失败之后会调用到
/// Processes a logical clock tick.
pub fn tick(mut self) -> Result<Node> {
self.assert()?;
self.role.election_duration += 1;
if self.role.election_duration >= self.role.election_timeout {
self.campaign()?;
}
Ok(self.into())
}
|
compaign
在compaign当中,逻辑按照小论文当中实现:
- 自增term
- 为自己投一票
- 持久化保存term
- 发送Message,向其他的节点请求投票,发送一条Event类型为SolicitVote类型的Message
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| /// Campaign for leadership by increasing the term, voting for ourself, and
/// soliciting votes from all peers.
pub(super) fn campaign(&mut self) -> Result<()> {
let term = self.term + 1;
info!("Starting new election for term {}", term);
self.role = Candidate::new();
self.role.votes.insert(self.id); // vote for ourself
self.term = term;
self.log.set_term(term, Some(self.id))?;
let (last_index, last_term) = self.log.get_last_index();
self.send(Address::Broadcast, Event::SolicitVote { last_index, last_term })?;
Ok(())
}
|
SolicitVote
SolicitVote类型的Message由其他的Follower来处理,对于所有Message的处理,都定义在step()当中,这里逻辑和上面一样,根据节点角色再去进行调用,SolicitVote在follower.step()当中:
- 如果当前term投过票了就忽略
- 做安全性检查,只会给日志状态最新的节点投票
- 检查通过则投票,并做持久化记录,存储vote for
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| Event::SolicitVote { last_index, last_term } => {
let from = msg.from.unwrap();
// If we already voted for someone else in this term, ignore it.
if let Some(voted_for) = self.role.voted_for {
if from != voted_for {
return Ok(self.into());
}
}
// Only vote if the candidate's log is at least as up-to-date as
// our log.
let (log_index, log_term) = self.log.get_last_index();
if last_term > log_term || last_term == log_term && last_index >= log_index {
info!("Voting for {} in term {} election", from, self.term);
self.send(Address::Node(from), Event::GrantVote)?;
self.log.set_term(self.term, Some(from))?;
self.role.voted_for = Some(from);
}
}
/// 定义在log当中,用于对term和vote_for进行持久化存储
/// Sets the most recent term, and cast vote (if any).
pub fn set_term(&mut self, term: Term, voted_for: Option<NodeID>) -> Result<()> {
self.engine.set(&Key::TermVote.encode()?, bincode::serialize(&(term, voted_for))?)?;
self.maybe_flush()
}
|
BecomeLeader
当candidate接收到Follower的投票回复之后,会记录票数,如果达到了quorum,那么就转换为leader,这一部分的逻辑同样是定义在step当中
当选为Leader之后,更新一些信息之后,会发送心跳信息告知其他的节点Leader已经当选。
之后会追加一条no-op,non-op的作用已经在上文角色切换部分解释了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| Event::GrantVote => {
self.role.votes.insert(msg.from.unwrap());
if self.role.votes.len() as u64 >= self.quorum() {
return Ok(self.become_leader()?.into());
}
}
fn become_leader(self) -> Result<RoleNode<Leader>> {
info!("Won election for term {}, becoming leader", self.term);
let peers = self.peers.clone();
let (last_index, _) = self.log.get_last_index();
let mut node = self.become_role(Leader::new(peers, last_index));
node.heartbeat()?;
// Propose an empty command when assuming leadership, to disambiguate
// previous entries in the log. See section 8 in the Raft paper.
node.propose(None)?;
Ok(node)
}
|
toydb当中Leader Election的实现非常简单,基本上完全按照raft小论文当中的描述,像是PreVote,Check Quorum,Leader Lease一概没有,不过这也很符合其toy的定位。
Log Replication#
Log#
在看日志复制之前,先看一下Log的实现:
Log模块并不只存储LogEntry,这里其实是对底层kv存储引擎的封装,所有需要进行持久化的数据都丢到存储引擎当中,包括current_term和vote_for,这里还额外存储了一个commit_index用于在commit时做一个安全校验,Entry是log的基本单位,实现同样是借助枚举来实现的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| /// A log key, encoded using KeyCode.
#[derive(Clone, Debug, PartialEq, Serialize, Deserialize)]
pub enum Key {
/// A log entry, storing the term and command.
Entry(Index),
/// Stores the current term and vote (if any).
TermVote,
/// Stores the current commit index (if any).
CommitIndex,
}
/// A log entry.
#[derive(Clone, Debug, PartialEq, Serialize, Deserialize)]
pub struct Entry {
/// The entry index.
pub index: Index,
/// The term in which the entry was added.
pub term: Term,
/// The state machine command. None is used to commit noops during leader election.
pub command: Option<Vec<u8>>,
}
|
Log本体定义如下,包括一个engine用于进行存储,和一些元数据,在初始化时,会从engine当中把元数据给加载出来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| pub struct Log {
/// The underlying storage engine.
engine: Box<dyn Engine>,
/// The index of the last stored entry.
last_index: Index,
/// The term of the last stored entry.
last_term: Term,
/// The index of the last committed entry.
commit_index: Index,
/// The term of the last committed entry.
commit_term: Term,
/// Whether to sync writes to disk.
sync: bool,
}
|
其中的函数实现,逻辑都比较简单,并且也都提供了丰富的注释,这里就不展开。
Heartbeat#
与6.824当中使用heartbeat来携带日志不同,在toydb当中,heartbeat就仅仅是用于维护leader身份,以及推动follower的commit_index,不会携带log entry。heartbeat的发送逻辑在leader.tick()当中,heartbeat的处理在follower.step()当中:
- 接收到了heartbeat就不断将自己转换为follower
- 根据leader传来到commit_index和自身log的情况,推动commit的进度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // leader.tick()
/// Processes a logical clock tick.
pub fn tick(mut self) -> Result<Node> {
self.assert()?;
self.role.since_heartbeat += 1;
if self.role.since_heartbeat >= HEARTBEAT_INTERVAL {
self.heartbeat()?;
self.role.since_heartbeat = 0;
}
Ok(self.into())
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| pub enum Event {
/// Leaders send periodic heartbeats to its followers.
Heartbeat {
/// The index of the leader's last committed log entry.
commit_index: Index,
/// The term of the leader's last committed log entry.
commit_term: Term,
},
/// ......
/// ......
}
// follower.step()当中处理心跳信息
// The leader will send periodic heartbeats. If we don't have a
// leader in this term yet, follow it. If the commit_index advances,
// apply state transitions.
Event::Heartbeat { commit_index, commit_term } => {
// Check that the heartbeat is from our leader.
let from = msg.from.unwrap();
match self.role.leader {
Some(leader) => assert_eq!(from, leader, "Multiple leaders in term"),
None => self = self.become_follower(Some(from), msg.term)?,
}
// Advance commit index and apply entries if possible.
let has_committed = self.log.has(commit_index, commit_term)?;
let (old_commit_index, _) = self.log.get_commit_index();
if has_committed && commit_index > old_commit_index {
self.log.commit(commit_index)?;
let mut scan = self.log.scan((old_commit_index + 1)..=commit_index)?;
// 与状态机进行交互
while let Some(entry) = scan.next().transpose()? {
self.state_tx.send(Instruction::Apply { entry })?;
}
}
self.send(msg.from, Event::ConfirmLeader { commit_index, has_committed })?;
}
|
Log Replication#
Log Replication的入口在Leader.step()当中,Leader会处理由Client发送而来的请求,在这里会调用propose(),在propose当中,真正开始进行日志复制,将命令转换为日志存储到本地,之后再发送给其他的节点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // leader.step() 接受客户端请求
Event::ClientRequest { id, request: Request::Mutate(command) } => {
let index = self.propose(Some(command))?;
self.state_tx.send(Instruction::Notify { id, address: msg.from, index })?;
if self.peers.is_empty() {
self.maybe_commit()?;
}
}
// propose,真正开始日志复制的逻辑
/// Proposes a command for consensus by appending it to our log and
/// replicating it to peers. If successful, it will eventually be committed
/// and applied to the state machine.
pub(super) fn propose(&mut self, command: Option<Vec<u8>>) -> Result<Index> {
let index = self.log.append(self.term, command)?;
for peer in self.peers.clone() {
self.send_log(peer)?;
}
Ok(index)
}
|
Progress
Progress的含义是,站在Leader的角度,观察到的follower的复制进度,定义了next_index和match_index,之后使用一个HashMap来管理各个节点的进度,由于和etcd相比少了流水线发送和滑动窗口流量控制等,Progress的实现简单了很多:
1
2
3
4
5
6
7
8
9
10
11
12
13
| struct Progress {
/// The next index to replicate to the peer.
next: Index,
/// The last index known to be replicated to the peer.
last: Index,
}
pub struct Leader {
/// Peer replication progress.
progress: HashMap<NodeID, Progress>,
/// Number of ticks since last periodic heartbeat.
since_heartbeat: Ticks,
}
|
propose#
在propose当中,会首先将日志持久化到本地,之后调用send_log()进行发送,在send_log()当中,会根据Progress找到需要发送的日志,之后从本地进行读取。
- 根据progress获取到next之后,先从本地读取next - 1的Entry,next - 1的Entry是用于检测日志冲突的,理应存在于Leader本地
- 扫描出next之后的所有Entry,连同base_index和base_term封装成一条
AppendEntries发送给follower
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /// Sends pending log entries to a peer.
fn send_log(&mut self, peer: NodeID) -> Result<()> {
let (base_index, base_term) = match self.role.progress.get(&peer) {
Some(Progress { next, .. }) if *next > 1 => match self.log.get(next - 1)? {
Some(entry) => (entry.index, entry.term),
None => panic!("Missing base entry {}", next - 1),
},
Some(_) => (0, 0),
None => panic!("Unknown peer {}", peer),
};
let entries = self.log.scan((base_index + 1)..)?.collect::<Result<Vec<_>>>()?;
debug!("Replicating {} entries at base {} to {}", entries.len(), base_index, peer);
self.send(Address::Node(peer), Event::AppendEntries { base_index, base_term, entries })?;
Ok(())
}
|
AppendEntries#
Leader封装了一条AppendEntries发送给Follower,相对应的就在Follower.step()当中进行处理:
- 能够接收到AppendEntries证明能够确认Leader,因此就调用
become_follower()更新自身状态,对Leader进行跟随 - 尝试匹配日志,并将其应用于自身,如果不匹配则返回一条Reject,让Leader再去做backup,找到正确的日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| // Replicate entries from the leader. If we don't have a leader in
// this term yet, follow it.
Event::AppendEntries { base_index, base_term, entries } => {
// Check that the entries are from our leader.
let from = msg.from.unwrap();
match self.role.leader {
Some(leader) => assert_eq!(from, leader, "Multiple leaders in term"),
None => self = self.become_follower(Some(from), msg.term)?,
}
// Append the entries, if possible.
if base_index > 0 && !self.log.has(base_index, base_term)? {
debug!("Rejecting log entries at base {}", base_index);
self.send(msg.from, Event::RejectEntries)?
} else {
let last_index = self.log.splice(entries)?;
self.send(msg.from, Event::AcceptEntries { last_index })?
}
}
|
在Leader端的处理分为两种,分别是成功响应的Event::AppendEntries和EventRejectEntries:
- 如果Follower能够成功匹配日志,那么Leader就会去更新进度,并且计算quorum,尝试进行commit
- 如果匹配失败,在Leader端progress向前回退一个,再尝试发送日志,进行探测,直至找到找到正确的位置,这里是没有实现的fast backup的,在效率上会存在一定的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| Event::AcceptEntries { last_index } => {
assert!(
last_index <= self.log.get_last_index().0,
"Follower accepted entries after last index"
);
let from = msg.from.unwrap();
self.role.progress.entry(from).and_modify(|p| {
p.last = last_index;
p.next = last_index + 1;
});
self.maybe_commit()?;
}
// A follower rejected log entries we sent it, typically because it
// does not have the base index in its log. Try to replicate from
// the previous entry.
//
// This linear probing, as described in the Raft paper, can be very
// slow with long divergent logs, but we keep it simple.
Event::RejectEntries => {
let from = msg.from.unwrap();
self.role.progress.entry(from).and_modify(|p| {
if p.next > 1 {
p.next -= 1
}
});
self.send_log(from)?;
}
|
Commit#
每次Leader确定了有follower保存了日志之后就会尝试进行commit,在rust当中,借助函数式编程,能将这个过程写的很优雅(没接触过函数式编程看了想骂娘):
- 首先获取到progress的HashMap,之后获取到HashMap的所有value(value是一个next_index和last_index组成的元组)
- 再做一个转换,获取last_index,这一步会得到一个由所有last_index组成的迭代器
- 之后使用chain将leader的last_index追加进去,最后转换为Vec
- 排序并反转之后第quorum大的last_index就是与follower达成共识的index
在vscode当中,rust-analyzer能够很清楚的显示出每一步都得到了什么:
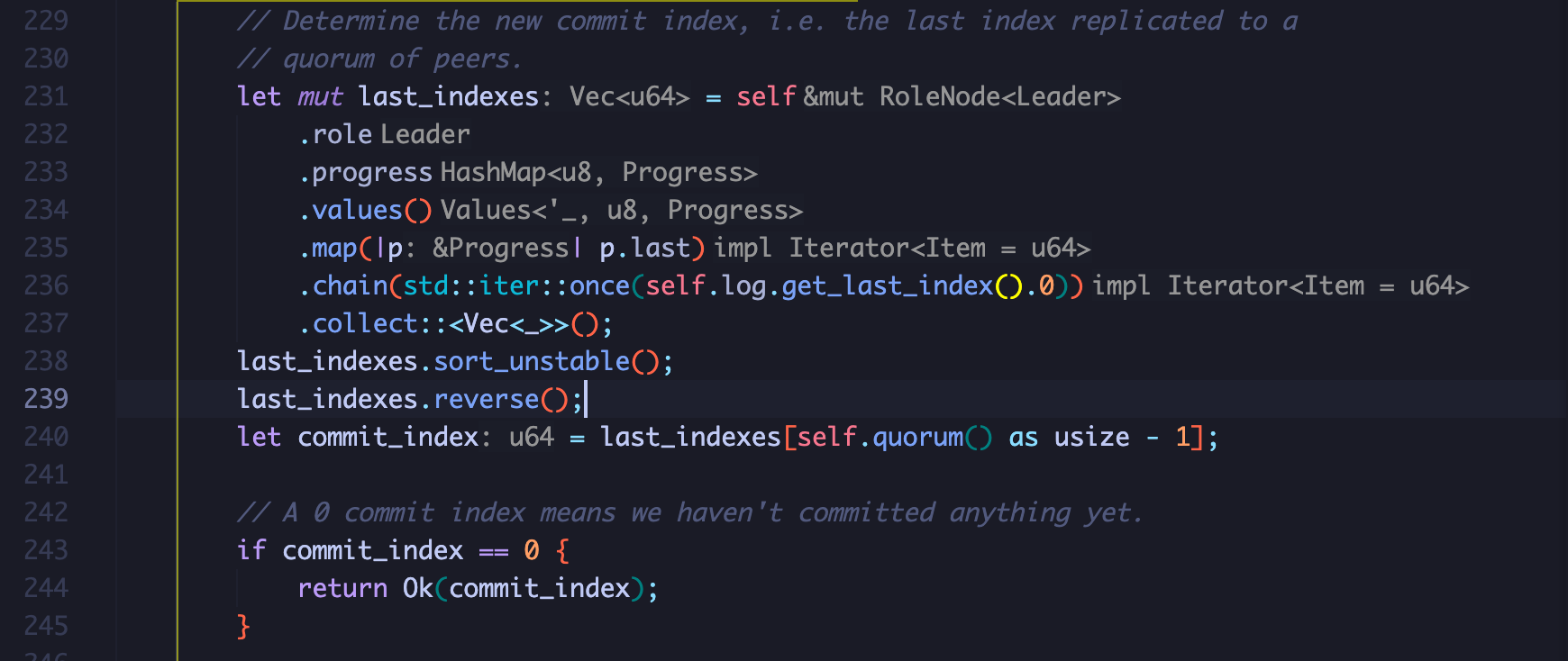
获取到commit_index之后做一些校验:
- 此次计算出的commit_index要大于上一次的commit_index
- 获取出 commit_index 对应的 entry,判断是不是当前的 Term,Leader 只能提交属于自己任期的日志 (见 raft 小论文 figure 8)
如果是新的commit_index,就在本地进行记录,并且扫描出从上一次commit到新commit_index之间的所有的日志,向上层状态机进行apply,即向state_tx channel当中发送一条信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| // Make sure the commit index does not regress.
let (prev_commit_index, _) = self.log.get_commit_index();
assert!(
commit_index >= prev_commit_index,
"Commit index regression {} -> {}",
prev_commit_index,
commit_index
);
// We can only safely commit up to an entry from our own term, see
// figure 8 in Raft paper.
match self.log.get(commit_index)? {
Some(entry) if entry.term == self.term => {}
Some(_) => return Ok(prev_commit_index),
None => panic!("Commit index {} missing", commit_index),
};
// Commit and apply the new entries.
if commit_index > prev_commit_index {
self.log.commit(commit_index)?;
// TODO: Move application elsewhere, but needs access to applied index.
let mut scan = self.log.scan((prev_commit_index + 1)..=commit_index)?;
while let Some(entry) = scan.next().transpose()? {
self.state_tx.send(Instruction::Apply { entry })?;
}
}
|
Summary#
以上就是toydb当中Raft模块的全部内容,这里的Raft模块指的是Raft本身的逻辑部分,不包括上层的状态机和发送命令的Client,这一部分笔者留到下一章的sql engine当中进行分析,最后以toydb与MIT6.824以及etcd进行一个简单的对比,来结束这一章
MIT-6.824
在MIT-6.824的Lab2当中,实现了一个基础的Raft模块,在其中几乎完整的复现了《In Search of an Understandable Consensus Algorithm (Extended Version)》一文,但没有实现集群配置变更,并且在持久化和snapshot上做了简化。
但是MIT6.824当中的实现并不是那么工程化,或者说接近生产环境,虽然每个人的实现方式不同,但是至少初始框架是这样的,相比于Tinykv来说。在6.824当中,在需要通信的时候就直接发送rpc调用对应的函数,以一种很直观的方式复现了Raft,当中定义的函数也都遵循论文当中figure2,基本上把figure2翻译成golang就能实现出来。
etcd/raft
etcd/raft作为一个投入生产环境的raft package,代码结构自然是清晰严谨的。
在基础结构上,etcd/raft将raft视为一个状态机,上层给予Raft一些输入,如tick或者message,Raft就会根据输入作出一些响应,更改自身状态,最后提供一些输出,上层处理完输出之后再调用Advance来继续推进Raft去更新状态。
在etcd当中,raft package仅提供raft的逻辑,如如何进行选举和发送日志,但是如持久化存储,网络通信都由上层应用负责,raft package通过Ready将需要存储的日志,快照,以及需要发送的消息交给上层。
在结构上,etcd/raft以Message为主体和驱动,整个Raft的执行流程就是在tick的驱动下,不断的执行和发送Message的过程,并不会像MIT6.824当中那样在一个函数当中能看到完整的rpc调用和处理流程,每个Message只会负责整体逻辑的一部分,执行完自己的内容就生成一个新的Message发送,其他拿到这条Message的来完成这个事件的剩余逻辑,举个例子,在进行选举时:
- candidate首先会向其他节点发送一个请求投票的Message,此时candidate目前负责的逻辑已经执行结束,candidate可以去执行其他内容
- follower受到candidate发送的Message就会进行处理,投票或者忽略,同样将结果封装成一条Message再发送给candidate
- Candidate 再收到 Message 之后继续完成剩余的逻辑,统计投票,决定是否当选
整个执行过程是松散、非连续的。但是主体逻辑全部使用 Message 来承载的话,整体结构就会非常清晰,raft 只需要不断的处理 Message 即可,并在适当的时候产生新的 Message
在实现上,etcd/raft完整的实现了Raft小论文当中的内容,包括在MIT-6.824当中没有实现的集群变更,并且对于Raft大论文《CONSENSUS: BRIDGING THEORY AND PRACTICE》当中的优化也进行了实现:
- 在结构上:采用了批处理的形式,即
Ready会向上层返回一批需要处理数据,上层用户进行集中处理,在Raft运行的过程中,只需要把log添加到对应的位置,将需要发送的Message放入“信箱”,届时一并通过Ready返回(这个其实和Raft大论文没什么关系,只不过都是优化就一并提一下了) - 在选举部分:ectd/raft实现了PreVote、Check Quorum、Leader Lease的优化
- 在日志复制上,ectd/raft采用了流水线设计,会在阻塞探测模式,流水线发送,快照发送三种模式下切换,在流水线模式下,etcd/raft可以在未接收到上次发送日志响应的情况下继续发送日志,并且使用滑动窗口来进行流量控制。并且在日志发送时,采用并行发送的方式,即存储与发送并行,可以在本地还未进行持久化存储的情况下就发送,某些情况下,follower可能在leader存储日志之前就接收到日志。在日志不匹配时,follower会返回一个hint,从而Leader可以快速进行回退,找到正确的位置。
- 在线性一致性读上,提供了 ReadIndex 和 Lease Read 两种方式,以绕过 Log Read,提高系统吞吐量
如果想进一步了解etcd/raft的话,推荐看这一系列,就像其名字一样,深入浅出:深入浅出etcd/raft —— 0x00 引言 - 叉鸽 MrCroxx 的博客
toydb
内容上,toydb相比于Raft小论文和MIT-6.824有所删减,同样没有实现集群成员变更,此外,没有实现日志的快速回退,和快照功能。而etcd当中的种种优化就更没有了(toydb通过Raft状态机实现了一个ReadIndex的功能,其他的就都没有了)
在结构上toydb基本上与etcd/raft一致,使用逻辑时钟+Message进行驱动,上面对etcd的分析对toydb基本上都适用。只不过toydb的持久化是由Raft自己负责的,所有与持久化相关的内容都扔进kv存储引擎当中,无论是元数据还是日志。但是网络模块是在上层实现的,在Raft当中也是和etcd一样,只需要把Message塞入信箱即可。
总的来说,toydb做了一个很好的取舍,用非常工程化的结构实现了一个几乎没有任何优化的,简单的Raft模块,代码逻辑非常的清晰,当然代价就是会损失一定的性能,如同步进行持久化,和日志出现不匹配时需要一条条进行回退。不过作为一个Learning Project,个人认为还是实现的非常优雅的,很值得用来学习。
对于Raft上层状态机和Client的相关内容,涉及到比较复杂的通信和异步编程,限于篇幅就不再本章当中进行分析,会留在下一章的kv engine当中一并进行分析。
由于分布式系统比较复杂,在toydb当中,在client,Raft,以及Raft状态机之间的逻辑比较复杂,涉及到大量的异步编程和信息交换,笔者水平有限,难免会出现错误,欢迎读者进行批评指正,再完成了Raft状态机部分,我也会重新校验整理这篇文章,以求达到一个更好的效果。