基础结构#
Bitcask本身非常简单,要是想实现一个最基础的bitcask存储引擎,大概200-300行代码就能实现,这里先简单介绍一下Bitcask的基础结构:
Bitcask是基于日志的,即Log-Structured,即采用顺序写入的方式,无论是删除还是更新都是向日志文件当中追加一个Entry,利用磁盘顺序写入的性能大于随机写入的特点,以达到高性能,但是同样的,在存储空间上会做出牺牲(日志文件当中会存储一些无效、过时的Entry)
Bitcask在数据管理上分为两部分,分别是内存和磁盘:
- 在内存当中维护一个map,key为存储的key,而value为Entry的metadata,记录长度和位置,用于进行偏移读取。map当中始终保存当前key的最新版本的位置
- 磁盘上使用Log-Structured进行管理,任何操作都是写入一个Entry,追加到日志文件的末尾,Log当中的存储单元通常为Entry,Entry的结构大致如下:
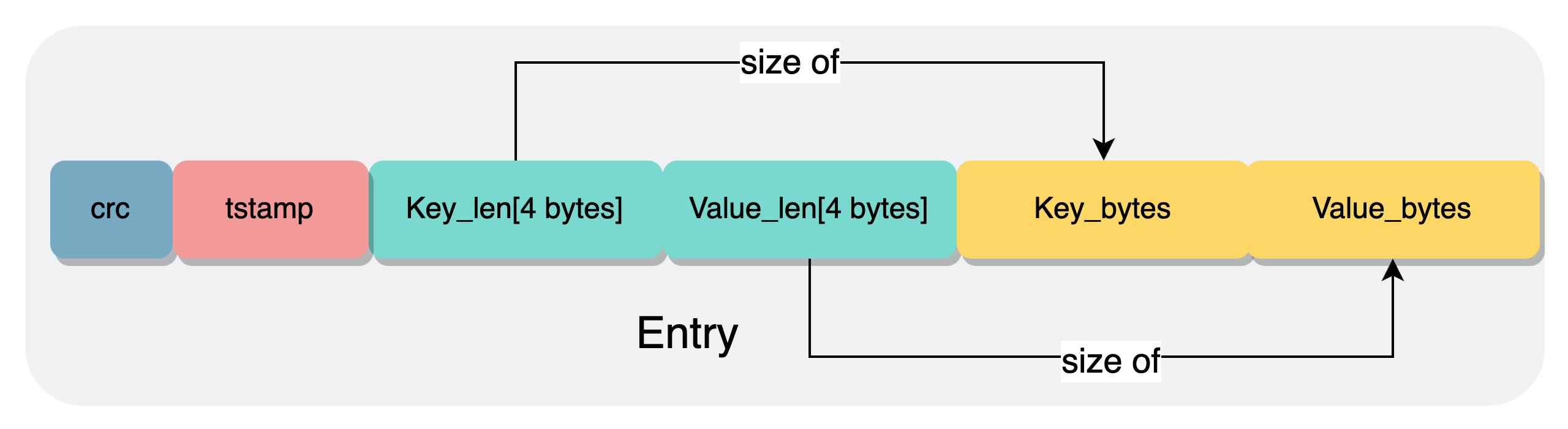
对于最基础的存储引擎,通常只需要提供Get、Put、Delete,大致逻辑如下:
Get:首先查询内存当中的map,如果不存在那么就是真的不存在,如果能查询到,那么就根据metadata去磁盘当中读取出对应的valuePut:首先向磁盘当中写入一条新的Entry,如果并且更新内存的map,保存新Entry的offsetDelete:和Put的逻辑基本一致,只不过value的类型不一样,写入的内容为tombstone,标志val已经被删除,同时删除内存当中的kv
Compaction#
和LSM-Tree一样,Bitcask同样有Compaction的过程,如上面所描述的,在写入过程当中,会有key被更新或者删除,但是旧版本的key依旧会存在于日志文件当中,随着时间的增加,日志文件当中的无效数据就会越来越多,占用额外的存储空间。因此就需要compaction将其清除。
对比LSM-Tree来说,Bitcask的Compaction就会简单非常多,只需要遍历当前内存当中存在的key,读取旧文件,写入到新文件当中,之后将新旧文件进行替换即可。
如果像具体了解Bitcask的话,可以看一下:
如上面所说的,在src/storage/engine/bitcask.rs当中定义了对应的结构体,其中有两个成员变量,分别对应内存当中的map和磁盘当中的日志文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| pub struct BitCask {
/// The active append-only log file.
log: Log,
/// Maps keys to a value position and length in the log file.
keydir: KeyDir,
}
/// Maps keys to a value position and length in the log file.
type KeyDir = std::collections::BTreeMap<Vec<u8>, (u64, u32)>;
struct Log {
/// Path to the log file.
path: PathBuf,
/// The opened file containing the log.
file: std::fs::File,
}
|
Log#
KeyDir没什么好说的,就是一个内存当中的map,这里使用的是BTreeMap的实现方式,便于进行顺序遍历进行compaction。
这里看一下Log的实现,在Log当中,除了初始化的new和用于debug的print,共有三个函数,分别用于读取、写入和根据日志重新构建Bitcask。
read_value和write_entry的实现比较简单:
read_value当中只需要根据传入的偏移量和长度,将对应的value读取出来即可write_entry当中,分别写入key_len,value_len(or tombstone),key_bytes,value_bytes(如果是删除那么久不写入),最后调用flush持久化到磁盘,最后返回一个offset和len,用于保存到BTreeMap当中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| /// Reads a value from the log file.
fn read_value(&mut self, value_pos: u64, value_len: u32) -> Result<Vec<u8>> {
let mut value = vec![0; value_len as usize];
self.file.seek(SeekFrom::Start(value_pos))?;
self.file.read_exact(&mut value)?;
Ok(value)
}
/// Appends a key/value entry to the log file, using a None value for
/// tombstones. It returns the position and length of the entry.
fn write_entry(&mut self, key: &[u8], value: Option<&[u8]>) -> Result<(u64, u32)> {
let key_len = key.len() as u32;
let value_len = value.map_or(0, |v| v.len() as u32);
let value_len_or_tombstone = value.map_or(-1, |v| v.len() as i32);
let len = 4 + 4 + key_len + value_len;
let pos = self.file.seek(SeekFrom::End(0))?;
let mut w = BufWriter::with_capacity(len as usize, &mut self.file);
w.write_all(&key_len.to_be_bytes())?;
w.write_all(&value_len_or_tombstone.to_be_bytes())?;
w.write_all(key)?;
if let Some(value) = value {
w.write_all(value)?;
}
w.flush()?;
Ok((pos, len))
}
|
这里稍微麻烦一点的是build_keydir,即用于在数据库启动时,读取日志文件,恢复出内存当中的BTreeMap,大致逻辑为:
- 从日志文件的开头开始遍历
- 先读取出key_len和value_len,其中,如果value_len为-1则证明当前为tombstone
- 如果是-1就封装一个none,否则计算出value_offset
- 读取出key,之后根据是否为tombstone来决定对map是插入还是删除
- 错误处理
- 循环直至日志文件末尾
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| /// Builds a keydir by scanning the log file. If an incomplete entry is
/// encountered, it is assumed to be caused by an incomplete write operation
/// and the remainder of the file is truncated.
fn build_keydir(&mut self) -> Result<KeyDir> {
let mut len_buf = [0u8; 4];
let mut keydir = KeyDir::new();
let file_len = self.file.metadata()?.len();
let mut r = BufReader::new(&mut self.file);
// ------(1)-----
let mut pos = r.seek(SeekFrom::Start(0))?;
while pos < file_len {
// Read the next entry from the file, returning the key, value
// position, and value length or None for tombstones.
let result = || -> std::result::Result<(Vec<u8>, u64, Option<u32>), std::io::Error> {
// ------(2)-----
r.read_exact(&mut len_buf)?;
let key_len = u32::from_be_bytes(len_buf);
r.read_exact(&mut len_buf)?;
let value_len_or_tombstone = match i32::from_be_bytes(len_buf) {
l if l >= 0 => Some(l as u32),
_ => None, // -1 for tombstones
};
// ------(3)-----
let value_pos = pos + 4 + 4 + key_len as u64;
let mut key = vec![0; key_len as usize];
r.read_exact(&mut key)?;
if let Some(value_len) = value_len_or_tombstone {
if value_pos + value_len as u64 > file_len {
return Err(std::io::Error::new(
std::io::ErrorKind::UnexpectedEof,
"value extends beyond end of file",
));
}
r.seek_relative(value_len as i64)?; // avoids discarding buffer
}
Ok((key, value_pos, value_len_or_tombstone))
}();
// ------(4)-----
match result {
// Populate the keydir with the entry, or remove it on tombstones.
Ok((key, value_pos, Some(value_len))) => {
keydir.insert(key, (value_pos, value_len));
pos = value_pos + value_len as u64;
}
Ok((key, value_pos, None)) => {
keydir.remove(&key);
pos = value_pos;
}
// ------(5)-----
// If an incomplete entry was found at the end of the file, assume an
// incomplete write and truncate the file.
Err(err) if err.kind() == std::io::ErrorKind::UnexpectedEof => {
log::error!("Found incomplete entry at offset {}, truncating file", pos);
self.file.set_len(pos)?;
break;
}
Err(err) => return Err(err.into()),
}
}
Ok(keydir)
}
|
Bitcask#
看完了Log,再来看一下Bitcask本体,可以看到,BitCask有五个对应的实现,除去Display和Drop以外,还有三个impl,分别来看这三个impl
第一个实现中定义了Bitcask初始化相关操作,对应函数为new和new_compact:
new:新建一个Bitcask,并调用上面分析过的log.build_keydir来从日志文件当中恢复内存当中的mapnew_compact:toydb的定义为learning project,对应的数据也为小规模的,因此在toydb的设计当中,只有在数据库启动时才会进行compact操作,并且这个过程是会锁住日志文件的,但是由于这个过程是算在启动当中的,也无伤大雅。在new_compact当中,会计算当前的garbage_ratio,如果超出阈值,就进行compact
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| pub fn new_compact(path: PathBuf, garbage_ratio_threshold: f64) -> Result<Self> {
let mut s = Self::new(path)?;
let status = s.status()?;
let garbage_ratio = status.garbage_disk_size as f64 / status.total_disk_size as f64;
if status.garbage_disk_size > 0 && garbage_ratio >= garbage_ratio_threshold {
log::info!(
"Compacting {} to remove {:.3}MB garbage ({:.0}% of {:.3}MB)",
s.log.path.display(),
status.garbage_disk_size / 1024 / 1024,
garbage_ratio * 100.0,
status.total_disk_size / 1024 / 1024
);
s.compact()?;
log::info!(
"Compacted {} to size {:.3}MB",
s.log.path.display(),
(status.total_disk_size - status.garbage_disk_size) / 1024 / 1024
);
}
Ok(s)
}
|
接下来看第二部分,封装了一些写入操作来为compact提供支持,定义了两个函数:compact与write_log,二者的逻辑都很简单:
- 在
write_log当中,会遍历当前的map,去原本的日志文件当中读取,写入到新的日志文件当中,并且构建新的map - 在
compact当中,创建一个新的文件,调用write_log重建日志文件,并且保存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| impl BitCask {
/// Compacts the current log file by writing out a new log file containing
/// only live keys and replacing the current file with it.
pub fn compact(&mut self) -> Result<()> {
let mut tmp_path = self.log.path.clone();
tmp_path.set_extension("new");
let (mut new_log, new_keydir) = self.write_log(tmp_path)?;
std::fs::rename(&new_log.path, &self.log.path)?;
new_log.path = self.log.path.clone();
self.log = new_log;
self.keydir = new_keydir;
Ok(())
}
/// Writes out a new log file with the live entries of the current log file
/// and returns it along with its keydir. Entries are written in key order.
fn write_log(&mut self, path: PathBuf) -> Result<(Log, KeyDir)> {
let mut new_keydir = KeyDir::new();
let mut new_log = Log::new(path)?;
new_log.file.set_len(0)?; // truncate file if it exists
for (key, (value_pos, value_len)) in self.keydir.iter() {
let value = self.log.read_value(*value_pos, *value_len)?;
let (pos, len) = new_log.write_entry(key, Some(&value))?;
new_keydir.insert(key.clone(), (pos + len as u64 - *value_len as u64, *value_len));
}
Ok((new_log, new_keydir))
}
}
|
第三部分则是engine的实现,在src/storage/mod当中定义了一个trait,而这一部分就是对bitcask进行一个简单的封装,来实现该trait,逻辑都比较简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| pub trait Engine: std::fmt::Display + Send + Sync {
/// The iterator returned by scan(). Traits can't return "impl Trait", and
/// we don't want to use trait objects, so the type must be specified.
type ScanIterator<'a>: DoubleEndedIterator<Item = Result<(Vec<u8>, Vec<u8>)>> + 'a
where
Self: 'a;
/// Deletes a key, or does nothing if it does not exist.
fn delete(&mut self, key: &[u8]) -> Result<()>;
/// Flushes any buffered data to the underlying storage medium.
fn flush(&mut self) -> Result<()>;
/// Gets a value for a key, if it exists.
fn get(&mut self, key: &[u8]) -> Result<Option<Vec<u8>>>;
/// Iterates over an ordered range of key/value pairs.
fn scan<R: std::ops::RangeBounds<Vec<u8>>>(&mut self, range: R) -> Self::ScanIterator<'_>;
/// Sets a value for a key, replacing the existing value if any.
fn set(&mut self, key: &[u8], value: Vec<u8>) -> Result<()>;
/// Returns engine status.
fn status(&mut self) -> Result<Status>;
/// Iterates over all key/value pairs starting with prefix.
fn scan_prefix(&mut self, prefix: &[u8]) -> Self::ScanIterator<'_> {
let start = std::ops::Bound::Included(prefix.to_vec());
let end = match prefix.iter().rposition(|b| *b != 0xff) {
Some(i) => std::ops::Bound::Excluded(
prefix.iter().take(i).copied().chain(std::iter::once(prefix[i] + 1)).collect(),
),
None => std::ops::Bound::Unbounded,
};
self.scan((start, end))
}
}
|
Iterator#
最后,定义了一个ScanIterator,用于进行范围读取,这里的写法还是比较的rusty的。额外定义了一个map函数,调用self.log.read_value()去磁盘当中进行读取,用于将BTreeMap当中的key与offset转换为真实的kv。
由于inner和log都是引用类型,因此标注了生命周期
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| pub struct ScanIterator<'a> {
inner: std::collections::btree_map::Range<'a, Vec<u8>, (u64, u32)>,
log: &'a mut Log,
}
impl<'a> ScanIterator<'a> {
fn map(&mut self, item: (&Vec<u8>, &(u64, u32))) -> <Self as Iterator>::Item {
let (key, (value_pos, value_len)) = item;
Ok((key.clone(), self.log.read_value(*value_pos, *value_len)?))
}
}
impl<'a> Iterator for ScanIterator<'a> {
type Item = Result<(Vec<u8>, Vec<u8>)>;
fn next(&mut self) -> Option<Self::Item> {
self.inner.next().map(|item| self.map(item))
}
}
impl<'a> DoubleEndedIterator for ScanIterator<'a> {
fn next_back(&mut self) -> Option<Self::Item> {
self.inner.next_back().map(|item| self.map(item))
}
}
|
memory#
此外,在同目录下,还定义了一个memory,同样作为Engine的一个实现,表示一个纯内存的存储引擎,使用的就是BTreeMap,将key和value直接存储在内存当中,不会对数据进行持久化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| pub struct Memory {
data: std::collections::BTreeMap<Vec<u8>, Vec<u8>>,
}
impl Memory {
/// Creates a new Memory key-value storage engine.
pub fn new() -> Self {
Self { data: std::collections::BTreeMap::new() }
}
}
impl Engine for Memory {
type ScanIterator<'a> = ScanIterator<'a>;
// 自欺欺人了属于是
fn flush(&mut self) -> Result<()> {
Ok(())
}
fn delete(&mut self, key: &[u8]) -> Result<()> {
self.data.remove(key);
Ok(())
}
fn get(&mut self, key: &[u8]) -> Result<Option<Vec<u8>>> {
Ok(self.data.get(key).cloned())
}
fn scan<R: std::ops::RangeBounds<Vec<u8>>>(&mut self, range: R) -> Self::ScanIterator<'_> {
ScanIterator { inner: self.data.range(range) }
}
fn set(&mut self, key: &[u8], value: Vec<u8>) -> Result<()> {
self.data.insert(key.to_vec(), value);
Ok(())
}
fn status(&mut self) -> Result<Status> {
Ok(Status {
name: self.to_string(),
keys: self.data.len() as u64,
size: self.data.iter().fold(0, |size, (k, v)| size + k.len() as u64 + v.len() as u64),
total_disk_size: 0,
live_disk_size: 0,
garbage_disk_size: 0,
})
}
}
|
Status#
在src/storage/engine/mod.rs当中,定义了一个Status,用于表示当前存储引擎的状态,bitcask和memory在创建时都是设置一个状态,看一看就好
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /// Engine status.
#[derive(Clone, Debug, PartialEq, Serialize, Deserialize)]
pub struct Status {
/// The name of the storage engine.
pub name: String,
/// The number of live keys in the engine.
pub keys: u64,
/// The logical size of live key/value pairs.
pub size: u64,
/// The on-disk size of all data, live and garbage.
pub total_disk_size: u64,
/// The on-disk size of live data.
pub live_disk_size: u64,
/// The on-disk size of garbage data.
pub garbage_disk_size: u64,
}
|