toydb是一个完全由rust编写的分布式关系型数据库,相对于其代码规模,其功能实现上可以说是非常的完善了,使用大约1.5w的rust代码,实现了:
- SQL引擎
- SQL解析:词法分析 + 语法分析,最后生成一个棵AST
- SQL执行:根据AST生成一个Planner,以及使用Optimizer进行优化,最后执行,Executor上使用了火山模型
- Raft模块:整体设计上采用了类etcd的状态机结构,通过逻辑时钟 + message + step来驱动raft状态机的变更
- 存储引擎:使用了Log-Structured当中最简单的Bitcask
- 事务:提供最基本的 ACID 和 MVCC 支持
项目的整体架构图如下:
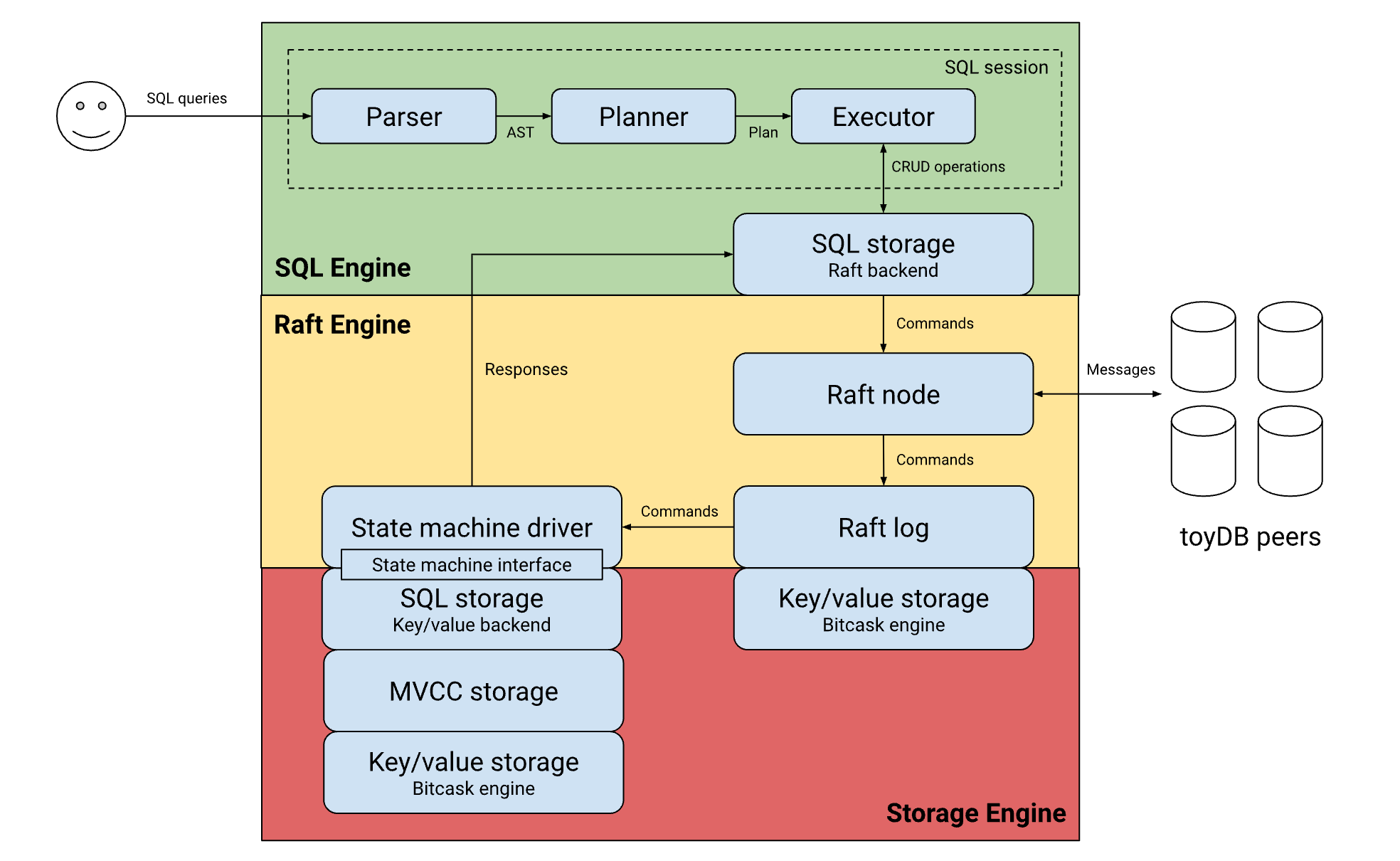
执行流程#
在本章当中,以一次简单的SQL执行过程,来了解一下toydb的整体架构和调用链
server#
toydb整体是采用client-server结构的,client在这里不做分析,在src目录下存在一个server.rs,其中定义了server的一些相关逻辑,那么程序的入口自然而言的就是server.rs了,server负责与客户端以及其他的raft节点之间的通信,主要的就是三个函数:listen、serve、serve_sql
listen:传入两个addr,分别代表用于接收client发送的sql的ip以及用于raft通信的ip,在通信上,为了应对高并发,采用了async/await异步编程的方式(tokio),这里不过多分析serve:接受网络请求并进行处理,在其中分别调用raft.serve和serve_sql,raft.serve留到raft模块当中进行分析serve_sql:sql执行的入口
 serve_sql:
serve_sql:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /// Serves SQL clients.
async fn serve_sql(listener: TcpListener, engine: sql::engine::Raft) -> Result<()> {
let mut listener = TcpListenerStream::new(listener);
while let Some(socket) = listener.try_next().await? {
let peer = socket.peer_addr()?;
let session = Session::new(engine.clone())?;
tokio::spawn(async move {
info!("Client {} connected", peer);
match session.handle(socket).await {
Ok(()) => info!("Client {} disconnected", peer),
Err(err) => error!("Client {} error: {}", peer, err),
}
});
}
Ok(())
}
|
可以看到,在其中处理完网络链接之后,调用了session.handle(socket),在其中从tcp流当中获取了request之后,就调用了self.request(request)。后面剩下的都是些对于执行结果的处理,用于进行返回。
在request当中,会根据request的类型,来决定如何执行,request本身为一个枚举类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| #[derive(Debug, Serialize, Deserialize)]
pub enum Request {
Execute(String),
GetTable(String),
ListTables,
Status,
}
/// Executes a request.
pub fn request(&mut self, request: Request) -> Result<Response> {
debug!("Processing request {:?}", request);
let response = match request {
Request::Execute(query) => Response::Execute(self.sql.execute(&query)?),
Request::GetTable(table) => {
Response::GetTable(self.sql.read_with_txn(|txn| txn.must_read_table(&table))?)
}
Request::ListTables => Response::ListTables(
self.sql.read_with_txn(|txn| Ok(txn.scan_tables()?.map(|t| t.name).collect()))?,
),
Request::Status => Response::Status(self.engine.status()?),
};
debug!("Returning response {:?}", response);
Ok(response)
}
|
SQL引擎#
普通的sql的request类型为Request::Execute,因此就会调用self.sql.execute(&query),在这里面,终于到真正的sql执行过程了,首先会创建一个Parser来解析sql,得到一个AST,之后根据AST的statement类型,其中有一些事务相关的,而对于普通的sql,则会走最后一部分,调用链为Plan::build -> optimize -> execute,算是比较标准的sql执行流程了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 这一部分是原本没有开启事务的,会默认开启一个事务
statement => {
let mut txn = self.engine.begin()?;
match Plan::build(statement, &mut txn)?.optimize(&mut txn)?.execute(&mut txn) {
Ok(result) => {
txn.commit()?;
Ok(result)
}
Err(error) => {
txn.rollback()?;
Err(error)
}
}
}
|
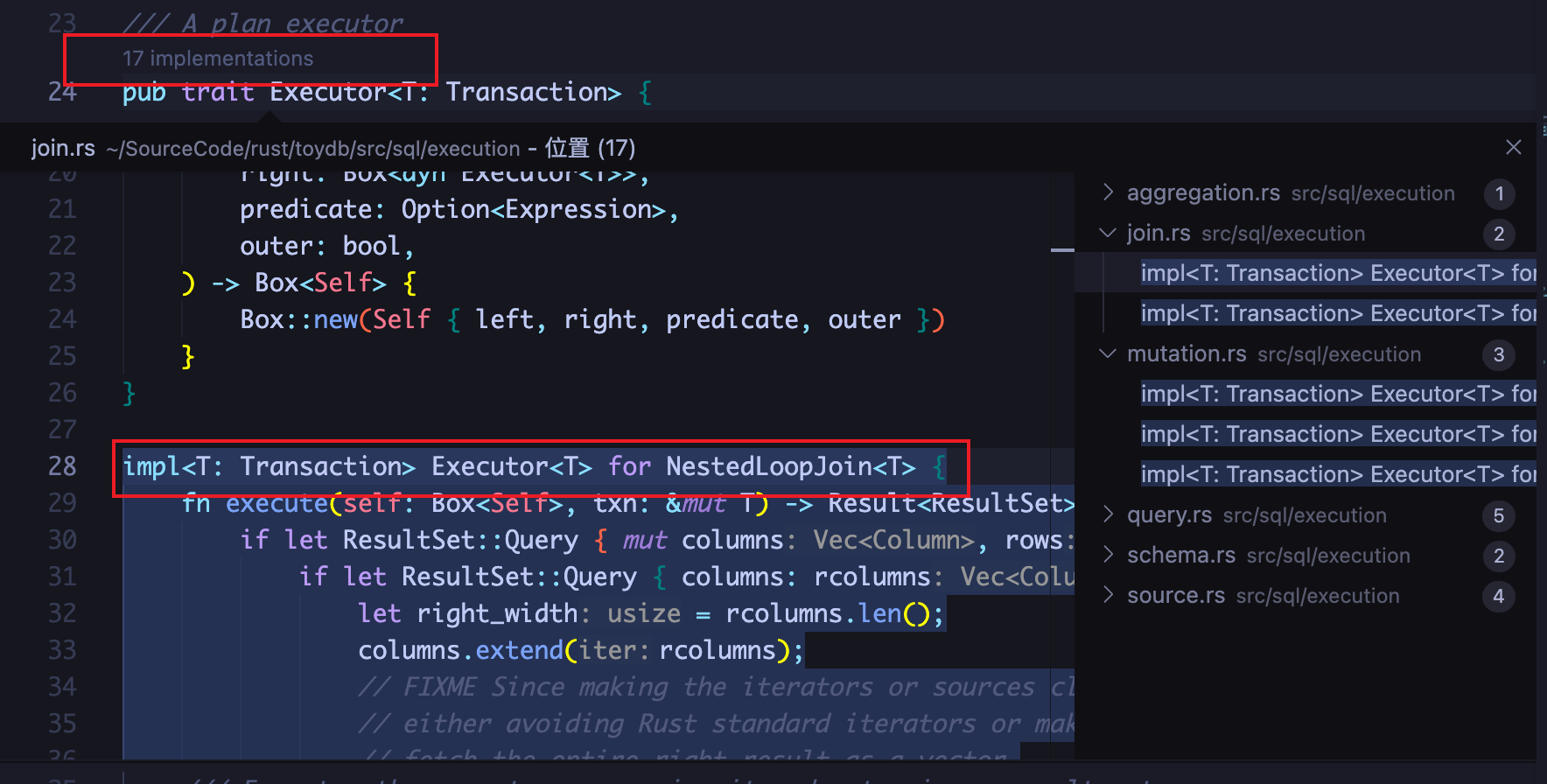
之后就是定义了一个Executor trait,然后其中包含一个execute,之后每添加一个算子就实现这个特征即可,可以看到的是,目前该特征有17个实现,那么就是所有算子了,对于算子怎么实现的,这里不做展开
1
2
3
4
5
6
7
8
9
| impl<T: Transaction> Executor<T> for Scan {
fn execute(self: Box<Self>, txn: &mut T) -> Result<ResultSet> {
let table = txn.must_read_table(&self.table)?;
Ok(ResultSet::Query {
columns: table.columns.iter().map(|c| Column { name: Some(c.name.clone()) }).collect(),
rows: Box::new(txn.scan(&table.name, self.filter)?),
})
}
}
|
这里以最简单的Scan为例,继续执行流程,在其中调用了txn.scan,之后就比较的复杂了,这里简单说一下流程,细节留着后面再单独进行分析,大致流程是先查询Raft的状态机,再走到存储层进行操作,在存储层当中的执行顺序大致为kv engine -> mvcc -> bitcask。
施工路线#
- bitcask
- storage engine
- raft
- sql engine
- mvcc
之所以开这个系列,主要是最近写毕设用到了rust,而自己目前的rust基本上是三脚猫水平,刚好toydb足够精简,加上功能十分的齐全,因此就以toydb作为rust实践学习,力图分析完主要代码逻辑,但是由于笔者的rust水平不佳,期间难免存在理解偏差与错误,欢迎读者批评指正,最后,希望这个系列不会烂尾:)