SPFresh: Incremental In-Place Update for Billion-Scale Vector Search
Introduction
本文聚焦于两个方面,一个是采用in-place(即原地更新)的方式更新索引,而另一个则是如何维护高质量的索引。对于之前的ANNS算法,无论是基于图的还是基于簇(cluster)的,通常采用的是重建索引的方式,即积累一段时间的新向量,到达一定程度后重新构建整个索引。但这样带来的问题就是会消耗大量的资源,并且构建索引的过程也会给查询带来延迟。
这种原地更新是有必要的,在目前的场景下,VDBMS会接收到大量的增量信息,而如果每次都采用重建索引的方式就会带来大量的额外开销。
目前无论是基于图的,还是簇的,都会在内存当中维护一个"shortcut",对于图来说,可以是向量的量化形式(DiskANN),而对于簇的形式,则使用的是质心(SPANN)。在进行搜索时首先使用 shortcut 进行初步搜索,之后再去进行进一步的搜索。因此 shortcut 的质量就会决定最终的搜索结果,如果 shortcut 不能够很好的代表对应的详细数据,如质心无法正确表示 posting list,那最后的搜索质量就会下降,即发生了数据分布倾斜。
在SPFresh当中,提出了LIRE,a Lightweight Incremental RE-balancing protocol,其核心思想就是利用已经存在的有着良好分区特性的索引。对这类索引的更新只会在小范围影响自己和邻居,因此需要做的就是平衡好此次更新涉及到的这一个小范围。
目前有三个挑战:
- 为了保持较短的搜索延迟,LIRE需要及时拆分和合并分区来维持分区的均匀分布
- 为了保持较高的搜索精度,LIRE 需要识别导致索引中数据不平衡的最小向量集。应重新分配这些向量以保持高索引质量。
- LIRE 的实现应该是轻量级的
对应的解决措施:
- 主动拆分和合并分区来维持分区大小的均匀分布
- 定义了两个基本准则来保证re-balance之后的分区不会违反NPA(rule of nearest neighbor posting assignment)
- 通过前馈管道的形式进行解耦成两阶段,将reassign的过程从更新的路径上移走
- 使用基于SSD的user-space的存储引擎来绕过传统存储堆栈,优化存储性能
Background
向量搜索和ANNS在很多地方都已经提及了,这里就不详细描述了,贴一张图
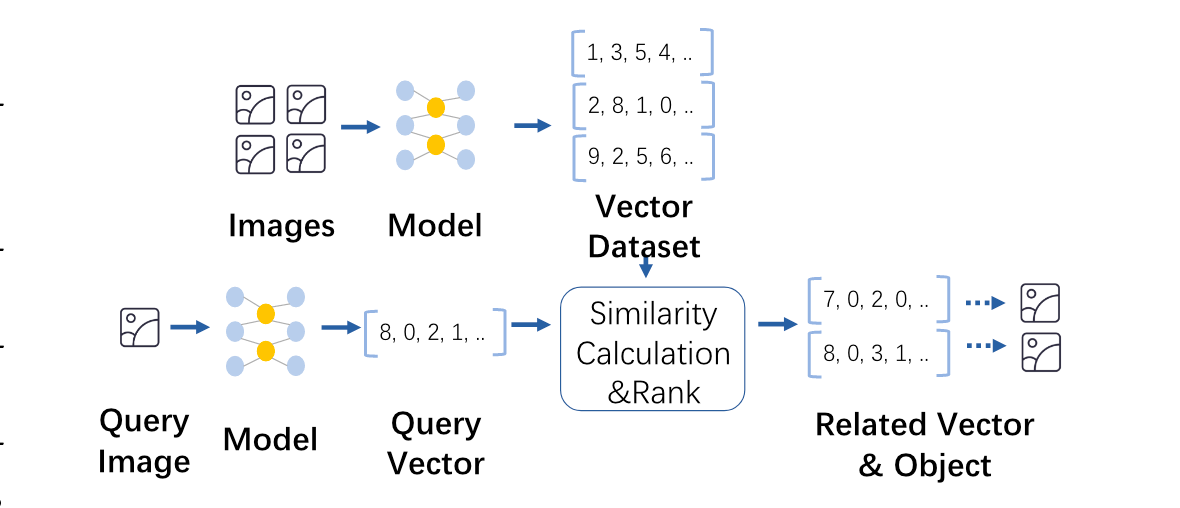 向量索引组织形式
向量索引组织形式
这里讨论了两个比较主流的索引组织形式,分别是基于图的(Fine-grained graph-based vector indices)和基于簇的(Coarse-grained cluster-based vector indices),在架构上都是内存-磁盘的混合架构。
Fine-grained graph-based vector indices
基于图的细粒度向量索引,在一张图当中,使用顶点来代表向量,使用边来表示两个向量的距离,如果两个向量足够近的话,就使用一条边来连接。在进行K临近搜索时,使用贪心算法遍历图,优先搜索距离最近的邻居。
部分算法的实现选择全部基于内存来实现,这样做的代价就是会带来大量的内存开销。一小部分算法会选择使用内存-磁盘的混合架构,如DiskANN,DiskANN采用的解决方案是在内存当中存储使用PQ量化压缩之后的顶点,以便节省内存开销,并且用于作为一级索引来加速查询。
Coarse-grained cluster-based vector indices
基于簇的粗粒度向量索引,将相近的向量管理在同一个簇当中,同一个簇当中的向量使用全连接图,而不同簇之间不存在边。
比较有代表性的就是SPANN,SPANN在内存当中存储簇的质心,先搜索出K临近的质心,之后再去搜索质心对应的簇,找到符合要求的向量。从而在实现高搜索性能的同时,保证了较低的内存开销。
相比于局部敏感性哈希和kmeans,SPANN在创建簇时对簇进行了大小上的平衡(基于分层的实现),并且采用的是重建索引的方式来完成更新(out-of-place),(在目前的改进方案中,不需要使用out-of-place,但是为了防止数据倾斜的发生,依旧需要周期性的重建索引)代价就是重建索引的高开销,包括时间和空间,时间上不必多说,空间上需要在更新期维护一个副索引,搜索时需要两个索引都进行搜索(就像redis的渐进式rehash,维护了两个哈希表,搜索时检测两个哈希表)
 但是如果直接使用in-placed的更新方法,直接在某个簇内追加向量,那么就必然会导致最后的数据分区倾斜的问题,这也是in-place更新方式最先需要解决的。
但是如果直接使用in-placed的更新方法,直接在某个簇内追加向量,那么就必然会导致最后的数据分区倾斜的问题,这也是in-place更新方式最先需要解决的。
设计目标
- 在维护大规模索引时保证低资源开销
- 搜索和更新都实现高吞吐量和低延迟
- 新向量可以高概率被检索到。
为此,设计了SPFresh,在索引数据结构中进行原地、增量式的更新,以适应数据分布的偏移
LIRE Protocol Design
LIRE基于 SPANN,SPANN的相关内容如下[[SPANN]]
LIRE: Lightweight Incremental RE-balancing
能够形成良好分区的关键时遵循nearest partition assignment(NPA):每个向量应该放入最近的posting list中,以便对应的质心能够很好表示该簇当中所有的向量。如下图,A在达到一定大小之后需要分裂,黄色的向量距离最近的质心是B,而B中绿色的向量距离最近的是A2.因此就不能简单的将A拆分为两个分区,而是应该视为对A以及周边簇中所有向量的重新分配。
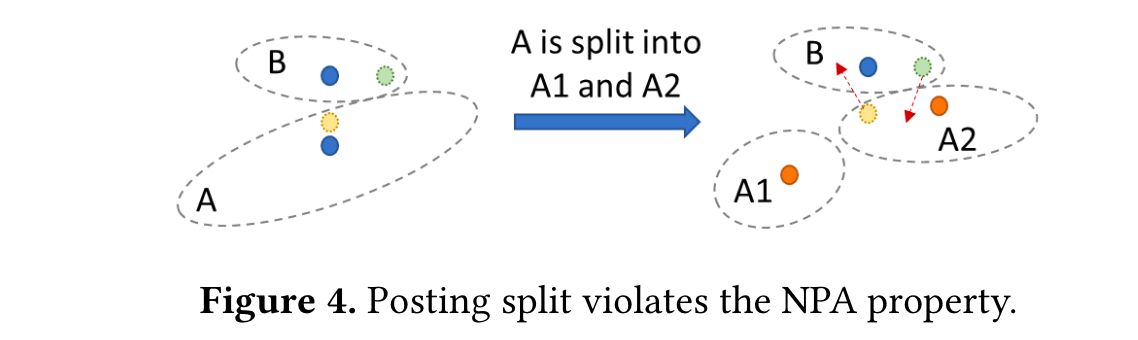
为了保证不违反NPA原则,LIRE定义了五种基本操作:Insert,Delete,Merge,Split,Reassign
Insert & Delete
Insert遵循原本的SPANN的设计,直接将vector插入到对应的簇当中,删除的话可以保证该向量之后都对用户不可见,但没必要真正删除掉,使用一个🪦标记一下即可,等到后续再延迟删除。 Insert和Delete是外部接口,其他作为内部借口由insert delete触发调用
Split
当posting list的长度超出限制,就将其分割成两个较小的部分,这一步会导致违反NPA,因此需要reassign操作。在最初会首先清除当中已经被删除的向量,而如果此时长度还是超出阈值,则进行split。
Merge
当posting list过小时,就需要对其进行合并,合并的实际过程是删除当前的posting list和对应的质心,将所有的向量添加到周围临近的posting list当中。这一步同样有可能违反NPA,因此也需要进行reassign
Reassign
重分配的过程涉及到操作磁盘上的posting list,所以应当尽可能的缩小涉及的范围。对于merge操作,只需要对于被删除中心对应的向量即可。但是由于split创建了两个新的质心,因此就复杂的多,为了不违反NPA原则,定义了两个必要条件(假定距离使用欧几里得距离进行讨论),如果满足其中之一,则需要考虑进行重分配:
- $$D(v,A_o)\le D(v,A_i) ,\forall i\in 1,2$$D为距离函数,$A_o$代表旧的被分割的质心,$A_i$为新创建的质心,这一条意味着如果原本的质心为离向量v最近的质心,并不代表新创建的两个质心为离v最近的质心,周围可能存在更近的质心,样例即为上图。相反的,如果新建的质心距离更短,那么就无需担心(不等条件传递,$D(v,A_i)\le D(v,A_0)) \le D(v,B)$
- $$D(v,Ai) \le D(v,A_o) , \exists i \in 1,2$$这种情况下,对于B而言需要考虑对其中的元素进行重分配,道理同样是不等条件传递,可能诞生新的更近质心。 由于需要对分裂和周边的postling list的所有向量进行检测,开销是巨大的,为了最小化开销,LIRE 仅通过选择几个 $A_o$ 的最近的postling list来检查附近的postling list进行重新分配检查,在此基础上应用两个条件检查来生成最终的重新分配集。第 5 节中的实验表明,只需少量附近的postling list进行两个必要的条件检查就足以维持索引质量。
Split-Reassign Convergence
在这一部分进行证明:虽然合并和分割的过程会出现级联现象,但是最终会收敛到一个稳定的状态。
首先merge操作在到达最低阈值之后就会停止,显而易见。
对于insert操作,假设insert会引发一系列的更改,记为$C_i,C_{i+1},…,C_{i + N}$,证明收敛性就是证明N是一个有限数。对于集合C而言,有以下的特点:
- $|C| \le |V|$,V代表整个数据集,C为质心集合,显而易见c的数量 小于等于v的数量
- $|C_{i+1}| = |C_i| + 1$: 每次分裂都会删除一个旧的集合,生成两个新的集合,因此每次分裂就是多处一个集合
基于属性二递推有:$|C_{i + N}| = |C_i| = N$,根据属性一,所以有$N \le V - |C_i|$,因此,既然V是一个有限数,那么N同样是个有限数。
SPFresh Design and Implementation
Overall Architecture
整体架构如图:分别有一个轻量的in-place updater,一个低开销的Local Rebuilder和一个快速存储的Block Controller
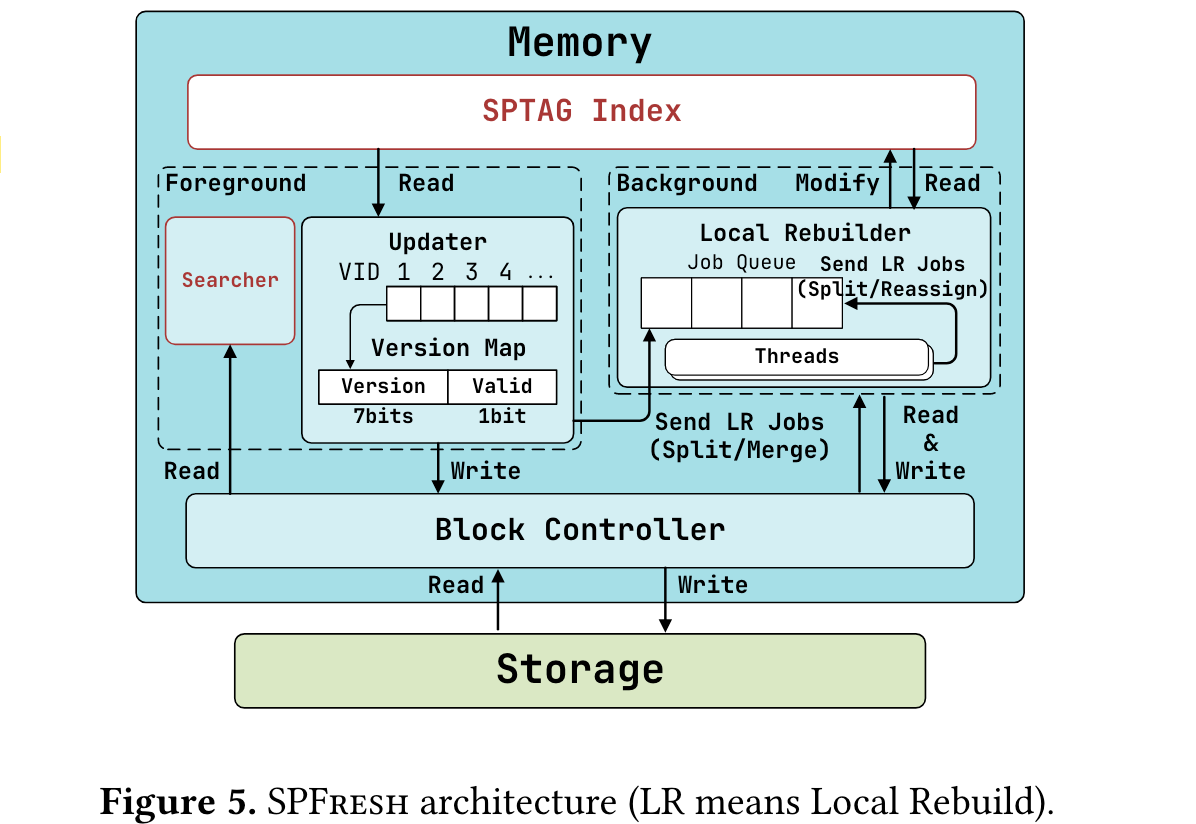 Updater
Updater
将新的向量添加到对应的posting list的后面,并且维护一个map来记录被删除的向量,即墓碑机制,还用于追踪每个向量的副本。通过增加版本号,它将旧副本标记为已删除。
如果内存中的版本号大于磁盘上的版本号,则向量已过时,可借此进行GC,使用版本号可以推迟和批量进行GC,从而控制向量清除的I/O开销。实际数据的删除是在local rebuilder部分异步进行的。 向量插入完成后,更新程序会检查posting list的长度,如果长度超过分割限制,则将分割作业发送到local rebuilder
Local Rebuilder
在其中维护了一个任务队列,当中存储split merge reassign任务,然后分发任务给多个后线程去执行。
- split由updater触发,当发现长度超过阈值时,并且会根据vector map去删除已经删除的向量。
- merge 由Searher触发,当发现长度小于最低阈值时
- reassign由split和merge触发 当merge和split完成之后,SPFresh就会去更新内存当中的SPTAG index
Block Controller
存储posting list,提供读写服务,使用SPDK来提供一种直接操作SSD block的接口,来避免使用一些存储引擎导致的读/写放大
Local Rebuilder Design
设计local rebuilder的目的就是为了将merge,split,reassign等操作从updater的执行流程当中移除,避免不必要的阻塞,目前update分成了两部分,前端的Updater和后端的Local Rebuilder。
平衡算法:split过程当中,Local Rebuilder 利用SPANN当中提出的中的多约束平衡聚类算法来生成高质量的质心和平衡的posting list(SPANN当中认为这个算法在N过大的情况下效果不好,使用的是分层平衡,由于只是分成两个,不存在SPANN当中面临的N过大的问题,没必要使用分层)。
vector map
前文当中提到了使用一个vector map来记录版本信息,这里详细说一下。
首先,在SPANN当中指出,为了提升召回率,对于边界上的向量会存储多个备份在不同的postling list(A,B,C)当中。但是在reassign的时候,由于SPFresh希望减少reassign过程的开销,不会处理所以的邻居,例如,在A当中删除某个索引,触发了merge,指波及到了A B D,那么C当中的副本应该被删除但是没删除,后续有可能在找到质心C时又读取到这个向量。
因此,这这里引入了版本控制,一方面是为了GC,即真正删除的可以通过map找到并清除,另一方面就是为了处理这种漏网之鱼:reassign向量时,我们会在版本映射中增加其版本号,并将原始向量数据及其新版本号附加到目标posting list中
Concurrent Rebuild
- 读取postling list不需要锁。因此,识别用于reassign的向量是无锁的,因为它仅搜索索引并检查两个必要条件
- 在进行reassign的过程当中,是有可能出现将向量添加到一个被删除的postling list当中,此时终止掉ressign并对该向量重新执行。在我们的实验中,只有不到 0.001% 的插入请求遇到了拆分导致的posting缺失问题。因此,中止和重新执行的开销很小。
- 在reassign过程当中,通过对版本号使用CAS原语来保证并发安全,如果失败同样是放弃并重新执行
Block Controller Design
Block Controller基于SPDK实现,最大的特点是直接操作SSD 的block,而不是使用如LSM-Tree等存储引擎,避免无意义的开销
存储数据布局
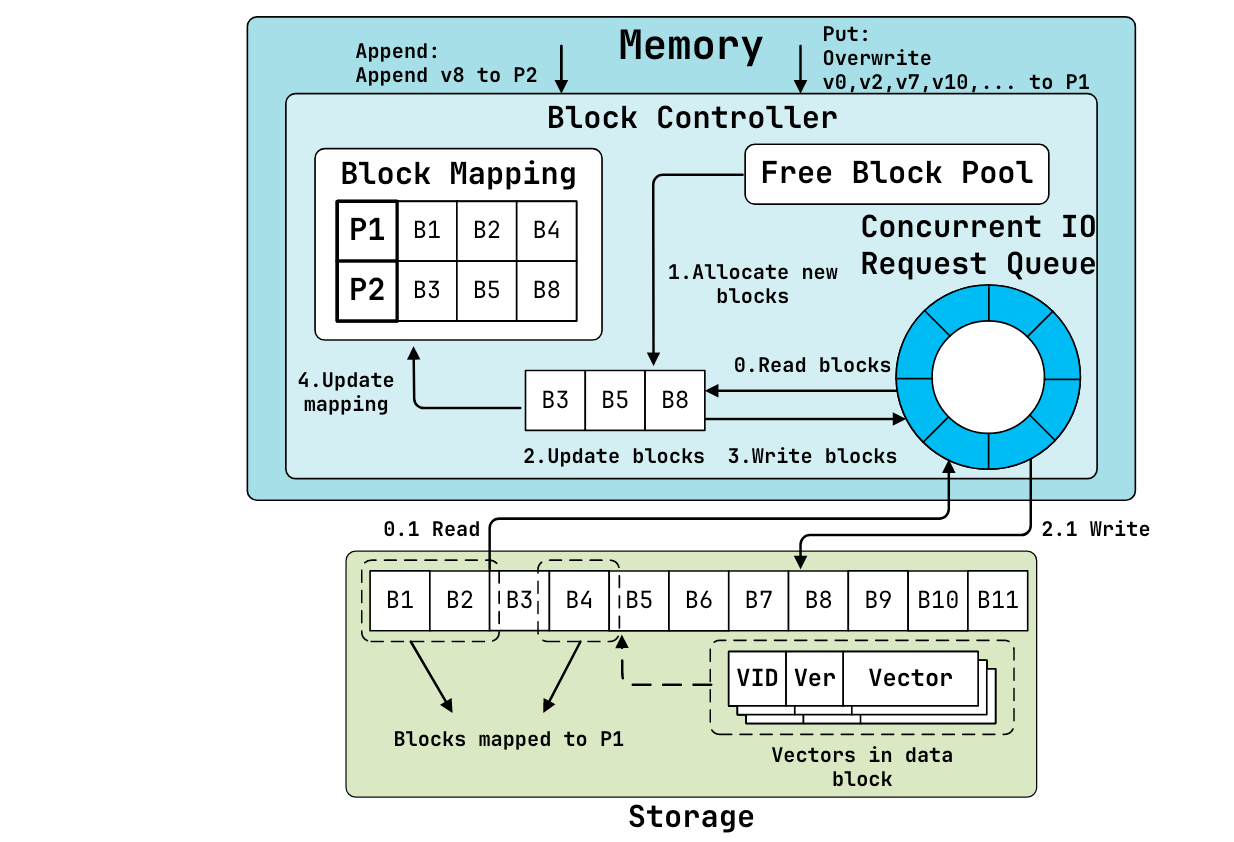
如下图,由三部分组成 Block Mapping、Free Block Pool、Concurrent I/O Request Queue。 Block Mapping存储一个posting ID和SSD block metadata的一个映射,包含偏移量和长度。
posting采用的是一组tuple的形式进行组织,形式为<vector id, version number, raw vector>,大致会占用3-4个block
Concurrent I/O Request Queue 使用 SPDK的循环buffer实现的,发送异步的读写请求来达到高吞吐和低延迟。
对于posting的操作提供了 GET ParallelGET APPEND PUT四个接口。
这里说一说APPEND,APPEND采用的是追加写的方式,只会操作涉及到的最后一个block,以此减少读/写放大的问题。
APPEND首先分配一个新的block,如果posting当中最后一个block不为空就先读进来,然后将新的向量添加到末尾,之后写回到磁盘上,顺带更新内存当中的映射关系
Crash Recovery
这里使用的是snapshot + WAL的形式,快照包含质心索引,updater当中的version map,Block Controller当中的block mapping 和block pool。
Evaluation
这里简单说一下实现的思路和验证的目标。
模拟每天大约 1% 的数据删除和插入,由于各类算法的不同,把更新操作需要满足的 QPS 作为指标,提供不同线程数做后台任务,如merge split rebuild index等,然后提供相同的线程数来做查询,比较查询的 QPS 以及 recall,内存占用等,结果如下。
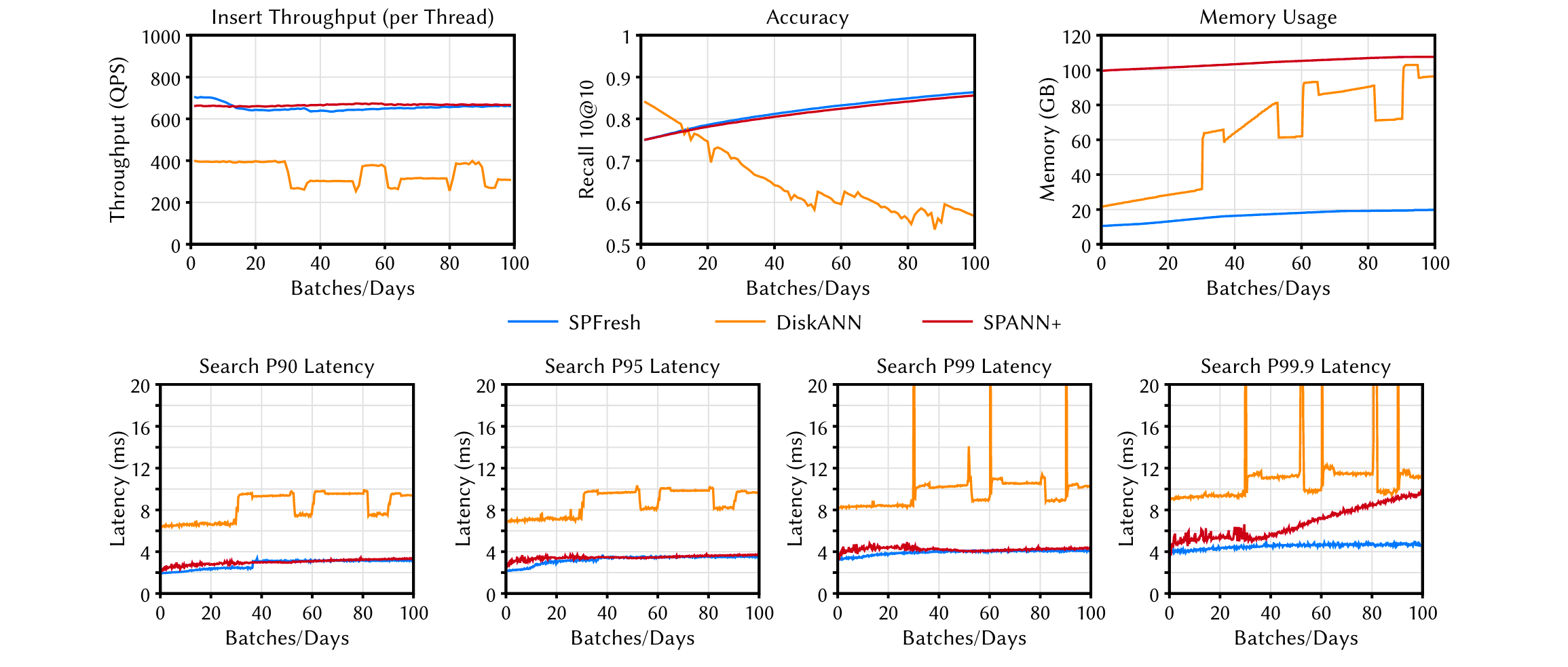 这里花了一部分阐述查询尾延和准确性的问题,SPFresh基于SPANN,在SPANN当中,一段时间的写入会导致数据分区倾斜的问题,因此无论是P99.9的尾延,还是准确率,在一段时间后与SPFresh之间出现了的差距。
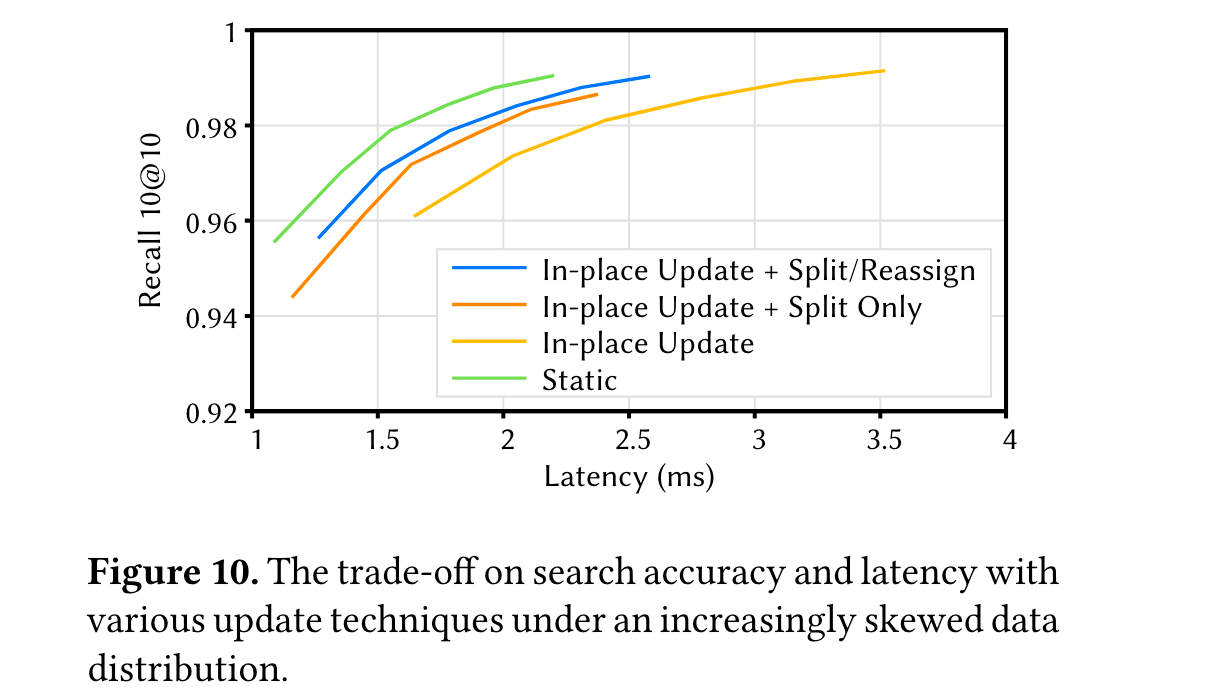
另外一个就是验证了在不同的更新策略下,召回率和延迟之间的一个trade-off,而这一部分出现不同的性能表现同样是因为数据分区倾斜
这里花了一部分阐述查询尾延和准确性的问题,SPFresh基于SPANN,在SPANN当中,一段时间的写入会导致数据分区倾斜的问题,因此无论是P99.9的尾延,还是准确率,在一段时间后与SPFresh之间出现了的差距。
另外一个就是验证了在不同的更新策略下,召回率和延迟之间的一个trade-off,而这一部分出现不同的性能表现同样是因为数据分区倾斜
Reassign Range
在文章的前半部分说明了为了防止在reassign的过程当中造成过大的开销,会限制参与reassign的邻居数量,在实验部分也给出了参数选择的依据,可以看到在64到128时,性能提升微乎其微,因此最终选择64作为参数(不过感觉64也挺大的)