More Than Capacity: Performance-oriented Evolution of Pangu in Alibaba
Introduction
本文主要讲述了盘古分布式存储十年来的一个演变历程,主要分为了三个阶段,分别是1.0,2.0的阶段一和2.0的阶段二。
- 在盘古1.0,此时的盘古主要是提供面向卷的存储服务(volume-oriented storage service provision),在这个阶段在硬件上使用的是传统的hdd,操作系统上使用的是内核空间的文件系统,最终主要的性能瓶颈时HDD和网络带宽。这个阶段有点像google的GFS
- 在盘古2.0的第一阶段,主要工作就是通过拥抱新硬件来解决1.0时期的性能瓶颈问题,通过引入SSD和RDMA技术,以提供高性能低延迟的存储服务。在这个阶段,
- 存储架构上采用通用的追加型持久层,并且将chunk的设计为独立类型。
- 在os层面将原本的内核空间文件系统转换为用户空间(user-space storage operatiing system USSOS),使用run-to-completion线程模型
- 提供SLA保证
- 在盘古2.0的第二阶段,将业务模式更新为性能导向,并且尝试打破网络,内存,CPU上的性能瓶颈,采用的解决方式分别为:
- 减少流量放大率
- 使用RDCA(remote direct cache access)
- 减少序列化和反序列化过程的计算负担,将部分cpu的计算职能移动到FPGA上,引入 CPU 等待指令来同步超线程
Background
Overview of Pangu
作为大规模的分布式存储系统,主要由三部分组成:Pangu Core,Pangu Service,Pangu Monitoring,而核心就是盘古Core,架构图如下,乍眼一看和GFS差不多:
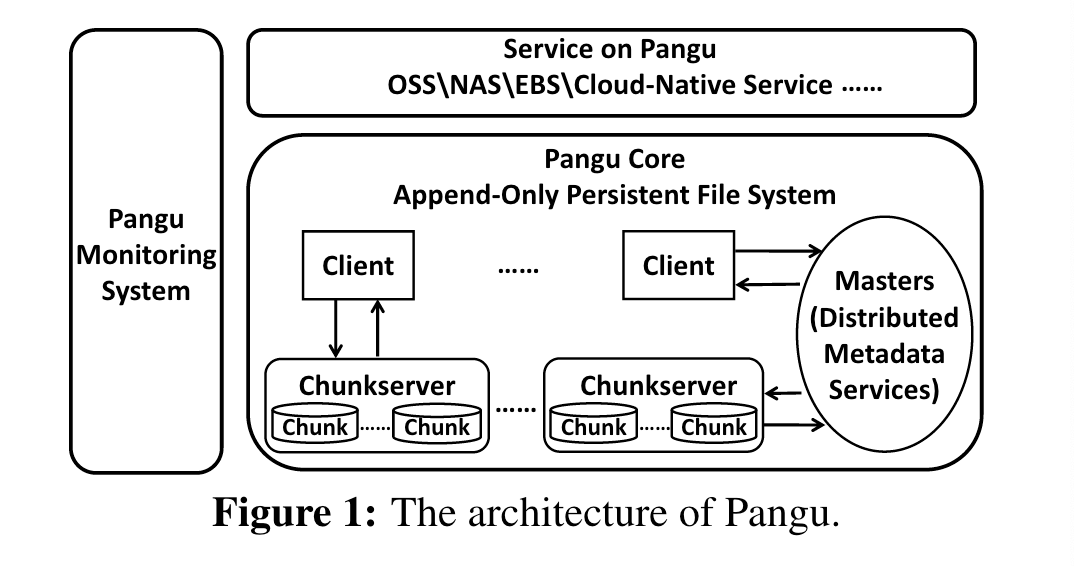
- client主要负责和上层的服务,如OSS,NAS进行对接,接受请求并和master与chunkserver之间进行通信,来完成请求。并且在备份管理,SLA保证,数据一致性上都起到了重要作用
- master和GPS当中的master一样,主要是管理元数据的,分为两部分,namespace service和stream meta service,namespace负责文件的信息,目录树和namespace,stream则是负责文件到chunk的一个映射。stream是一组chunk的抽象,在同一个stream当中的chunk属于同一个文件,通过这种方式来完成文件到chunk的一个映射。不过在这片文中并没有具体展开master的实现细节,盘古发过很多篇paper,可能在别的中有所提及
- Chunkserver 作为真正存储文件的服务器,使用了 user-space storage file system,和追加类型的存储引擎 (类 bitcask 或者 LSM-Tree 类型,其中会有 gc 的过程)。在备份上,最初使用 3 备份的方式,不过在 2.0 的设计过程当中,逐步使用纠删码来代替掉 3 备份以缩小流量放大率
设计目标
- 低延迟
- 高吞吐
- 对所有业务提供统一的高性能支持
Phase One: Embracing SSD and RDMA
Append-only File System
- 在持久化存储上,盘古提供统一的,只追加的持久层,原本对于不同的服务,盘古提供不同的接口,这样额外增加了系统的复杂性。如今,盘古引入了统一的文件类型 FlatLogFile,提供了只追加的语义,对于上层服务来说,提供的是一个key-value类型的接口。并且会有gc机制来处理历史数据。
- 重量级客户端:如上面所说的,客户端负责和 chunkserver 和 master 之间进行通信来提供服务,除此之外,还会负责复制和备份的相关操作,(3 备份或者纠删码)
chunkserver
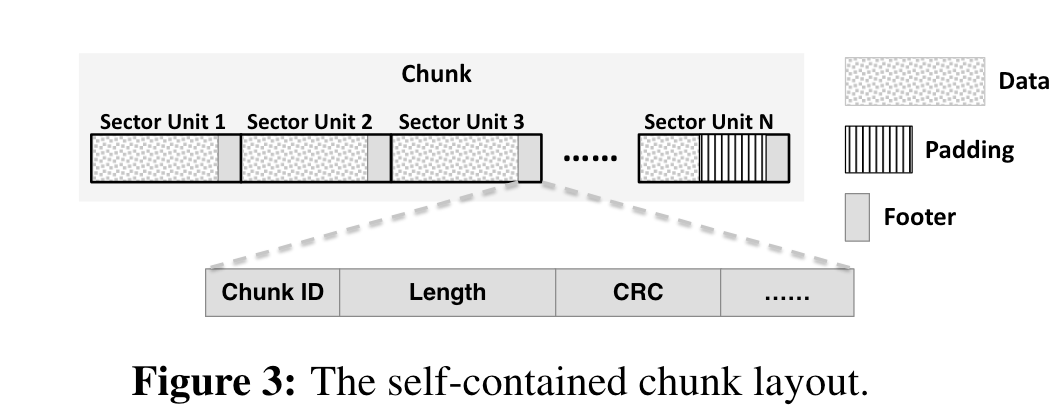
实现了独立的(self-contained)chunk布局,即chunk存储数据和元数据,而不是像经典的文件系统如linux ext4那样分为block和inode,这样做的好处是可以一次写入所有的数据,而不是原本的两次。
一个chunk当中含有多个基础单位,每个基础单位包含了数据,padding填充,和footer三部分,而footer当中存储chunk的元数据,如chunk id,chunk length CRC校验码,布局如下:
 Metadata Operation Optimization
Metadata Operation Optimization
主要提出了六个方向:
- 并行元数据处理,如客户端可以进行并行的路径解析
- 变长的大型chunk,有三个好处:减少元数据的数量,降低由于client频繁访问chunks带来的IO延迟,提升SSD的寿命。而过大的chunk则会导致碎片化的空间浪费,因此采用了变长的方式(1MB-2GB),但实际上95%的chunk大小都为64MB(和GFS直接设定为64MB差不多)
- 在client缓存chunk信息,在client端建立一个关于metadata的缓冲池,当缓存未命中或者缓存了陈旧数据时(chunkserver给予回复时一并告知),和master进行通信来获取最新的metadata
- 批处理的形式来处理chunk信息:client将一小段时间内的多个chunk的请求进行聚合然后批量发给master
- 预测性提前获取:获取一个chunk内容时,预测性的获取相关的chunk,存储在客户端,从而减少对chunk server发起请求
- 数据搭载以减少 1 个 RTT,将 chunk 创建请求和要写入的数据合并为一个请求并将其发送到 chunkserver。
Chunkserver USSOS
文中指出,传统的kernel-space文件系统会存在频繁的系统中断导致消耗CPU资源的情况,和某些数据在user space和kernel space当中存储了两份。为解决这类问题,通过绕过内核(kernel-bypassing)的方式设计了USSOS
user-level的内存管理: 建立一块使用huge-page的空间作为网络栈和存储栈之间的共享内存,从而减少拷贝的开销
任务调度:
- 由于采用了run-to-completion的线程模型,对于长时间运行会阻塞后面其他任务的,移动至后台线程运行
- 优先级调度:建立不同的优先级队列,根据QoS目标将不同的任务放到对应的队列当中
- NAPI:借鉴 Linux 的 NAPI,采用 polling(轮询) + event-driven(事件驱动) 相结合的方式,网卡对应了一个文件描述符,当有任务到达时通过文件描述符触发中断唤醒网卡,即事件驱动,网卡处理任务,并进入轮询模式,不断询问是否还有后续任务,如果有则可以快速处理,无需进行中断处理;如果一段时间没有后续任务,就回到事件驱动模式,等待中断
Append-Only USSFS
对Append-Only进行一个总结:
- 充分利用self-contained(自包含?独立?)的chunk来减少数据操作次数
- 不存在如inode和文件目录之间的关系,所有的操作都需要记录在log files当中,而相关的metadata可以通过重做日志来重建
- 使用轮询模式代替Ext4等中断通知机制,最大限度发挥SSD的性能
High Performance SLA Guarantee
chasing
当2 x MinCopy > MaxCopy时,允许MaxCopy副本中的MinCopy成功写入chunkservers时,它允许客户端向应用程序返回成功,即三个副本的情况下,可以两个chunkserver完成写入就允许返回success,此时client会将chunk在内存当中保留时间段t(ms级):
- 如果在这个时间段内能够成功得到响应,即可将chunk从内存当中移除,结束此次请求
- 如果无法得到响应,取决于未完成写入的部分的大小k:
- 如果 > k,则封存这个chunk,之后不对这个chunk进行写入操作,从另外两个server当中复制数据到一个新的chunkserver当中
- 如果 < k,则尝试对 chunk 3 进行重试
chasing设计的出发点并不是容错,而是为了在保证数据不丢失的情况下,尽可能的降低响应的延迟,使用chasing这个词来进行描述,指的就是前两个chunkserver已经完成了写入,而第三个server还在补齐进度的这样一个过程,而在这个补齐的过程当中,是存在第三个备份在client的,在chasing的过程当中,之后client chunkserver1 chunkserver2全部挂掉之后,数据才会彻底丢失。
Non-stop write
这一部分补充了容错机制,和chasing组成了完整的写入规则。如果只是单纯的写入失败,服务器仍可正常读取的话,那么就封存当前的chunk,分配一个新的chunk来写入未完成的部分,而如果是chunk当中的数据损坏,或者说chunkserver宕机,那么就从已成功写入的chunk当中使用后台流量去拷贝一份到新的chunk当中
Backup Read
client在收到响应之前,会向其他的chunkserver发送读请求,以防止原本的chunkserver宕机,从而减少读请求的延迟
Blacklisting
为提高服务质量,设置了黑名单制度,分两种情况:
- 无法提供服务的添加到确定性黑名单当中,如果可以提供服务则移除
- 延迟过高的则加入到非确定性黑名单当中,基于延迟确定是否移除
Phase Two: Adapting to PerformanceOriented Business Model
这个阶段主要考虑如何解决性能的瓶颈问题,分别是网络瓶颈,内存瓶颈和CPU瓶颈
NetWork Bottleneck
除了简单的扩大网络带宽以外,这一部分主要对流量放大率进行优化,减少需要传输的数据量:
- 通过纠删码(EC)来替代原本的三备份形式,EC(4,2)配置指的是使用将数据分为四个分片,使用其中两个分片就可以恢复原本的数据 允许在只存储相当于原始数据1.5倍的总数据量的情况下,容忍任意两个分片的丢失
- 对FlatLogFile进行压缩:LZ4算法
- 动态分配带宽:如接受请求和后台带宽,晚上进行GC任务较多时就给后台分配较大的带宽
Memory Bottleneck
- 使用多块较小容量的内存以充分利用内存通道的带宽,来代替一整块内存
- 将背景流量也使用RDMA,提高传输效率
- RDCA
CPU Bottleneck
- 混合RPC:以往使用protobuf进行序列化和反序列化这个过程需要耗费30%的CPU开销,而这种情况只会出现在少量的rpc类型当中,因此采用混合rpc,部分情况直接传输原始结构,不进行序列化
- 使用cpu wait以支持超线程
- 软硬件协同设计,即将一部分的计算工作转移至FPGA来完成,以减少CPU的负载。