由于Miniob的整体架构并没有做出很大的变化,并且目前知乎上也已经有其他人写的架构分析文章,我在这里就不过多介绍架构相关的了,只说一下我自己的一些实现和遇到的bug以及对应的修复方式。
负责题目
负责题目:
- date
- drop-table
- update
- join-tables
- null
- text
- big write
- big query
- update-mvcc
- 初赛附加题 共计210分
由于队友龙哥太猛了,一个人搞完了所有带嵌套子语句的题,并且做了好几个mid的题,所以留给我实现的内容也不太多,并且由于我未来研究生阶段主要做的是存储方向的,因此这次初赛当中我也主要负责存储相关的内容,如record-manager的相关改造,和新类型的支持。
此外,在实现null和update-mvcc时,发现了Miniob目前存在的两个bug,和来哥沟通之后,也是提了pr把我的解决方案给合并到了主分支当中,也算是做一些开源贡献了。
赛程安排
九月份就把去年ob的代码给拉下来了,当时主要在搞预推免的事,加上懒了,一直在本地吃灰。真正开始搞的时候大概是开赛前一周,当时双开了rcore,最后选择是献祭rcore全力搞ob,rcore写完rustlings之后便没有再推进。
开赛前一周
纯坐牢,配环境就花了一天,sudo执行bash脚本编译出来的需要sudo才能启动,而vscode的调试模式又不支持sudo,(后来发现把bash脚本里面的下载第三方库的部分注释掉可以不sudo执行,呆),无奈换了clion。后面又因为队友的一些语法在Mac支持不是很好,换成了linux作为开发机,之后花了一点时间缕清架构和执行流程,只做了date和drop-table。
第一周
继续坐牢,依旧没写几个题,大多数时间花在了研究lex和bison(本科阶段没学过编译原理),和expression的相关内容,只写完了join tables和接手了队友写了一半的update
第二周
算是熟悉整个系统和sql解析了,进度上快了一些,写完了null,完善了update的多字段支持,和text,顺手搞了附加题
第三周
花了两天时间搞了一下mvcc,通过所有测试,提前收队。
思路分享
drop table
大概是最简单的一个题了,只需要把create table给逆向操作就可以了,官网也给出了详细的指导,大致思路分为三部分:
- 删除
xxx.table表的元数据文件 - 删除
xxx.data数据文件 - 删除
xxx.index索引 除此之外做一些简单的异常处理就可以了,校验一下表名是否存在等。
Date
今年miniob的代码结构相比于22年要优化了不少,但是Date涉及到要改动的地方依旧不少,主要有:
- 在lex和yacc当中添加对 date和日期格式的匹配支持
- 在value当中添加date类型和表示形式
- 考虑Date的具体存储方法
- 为 Date 添加初始化,校验,比较等功能
解析
主要需要添加两个类型的解析,一个是date关键字,一个是yyyy-mm-dd格式的字符串匹配,前者直接定义一个token即可,后者可以采用正则的形式来处理,对于日期字符串的正则匹配,需要注意的是范围需要从0000-00-00到9999-99-99都匹配上,否则如13月这种错误的日志就会匹配到普通字符串上,从而导致后期无法进行校验处理。其他的按照官方手册实现即可
存储与表示
在存储上,我选择了使用一个yyyymmdd的int32来进行存储这样只需要四个字节,比字符串要节省空间。
在内存表示上,我选择了定义一个Date类,并将相关的相关的逻辑操作都封装在这里面,如类型转换,合法性校验,比较,to_string等。
| |
Value
在value当中,添加了一个Date字段来存储一个Date类,并且把转换为int的date存放到num_value_当中,之后.data()用来传输数据和持久化时直接返回这个num_value_即可。
到这date基本就实现完了,似乎今年miniob的代码重构了不少,往年说还需要更改B+树部分的今年都不需要了。
typecast
说Join之前先说一下typecast,今年typecast没有作为一个单独的题目出现,但是也并没有给提供很完善的实现,在实现join时发现了join对typecast强依赖,涉及到很多int和string,float和string之间的join。主要需要为string和其他的类型之间提供转换。
在github的wiki当中给出了标准,照着实现就好
- 如果字符串刚好是一个数字,则转换为对应的数字(如'1’转换为1,‘2.1’转换为2.1);
- 如果字符串的前缀是一个数字,则转换前缀数字部分为数字(如'1a1’转换为1,‘2.1a’转换为2.1);
- 如果字符串前缀不是任何合法的数字,则转换为0(不需要考虑前导符号 ‘+’ ‘-’); 问题:
- 如果转换数字溢出怎么处理?(不考虑)
- 是否考虑十六进制/八进制?(不考虑)
Join Tables
算是mid里面最简单的几个之一了,但是依赖不少其他的相关内容,如typecast和expression,今年的miniob已经实现了select tables,因此只需要再次基础上实现join即可。
先从解析开始说,join主要分为三部分,左表,右表,和条件,通过inner join on来切分即可,并且由于可能存在多张表之间的join,因此这个解析为一个递归的过程,可以先递归的解析inner join 后面的内容,之后再将最初的左表添加到其中。在条件的解析上,队友定义了conditionTree的解析方式,可以很方便的解析多个condition,我这里就直接拿来用了。解析的格式如下:
| |
最终的解析结果可以得到n个table和n-1个conditon_tree,之后在select_stmt的create当中按照和filter_stmt相同的方法来创建一个join_stmt即可。
最后改写一下join_operator当中的逻辑即可,这一部分反而是工作量最小的。 23年的数据量并不大,并不存在前两年的6表join的情况,因此只需要实现最基础的NLJ,甚至我们在重构expression的时候取消了谓词下推依旧可以通过测试。
bug
在调试过程中,发现了一个miniob当前存在的bug,join operator当中在匹配时,每当右表匹配完一轮之后都要调用table_scan的close()和open()函数,而在这其中,open()当中又会调用一个set schema的函数,在这其中,是采用push_back的方式进行初始化的,但是在close()当中又没有清空掉field数组,就导致,每次open,都会向里面重新添加一遍field,从而导致在进行多轮遍历之后,tuple里面会有几十个field之多,不过在物化的过程中,只会根据record去获取value,这样并不会影响正确性,但是会导致平白无故的添加一堆无用的数据,我在print tuple.to_string时都惊了,也可能正是因为不影响正确性,这个bug也没有被发现,正确的做法应该是在set_schema时先重置再添加
| |
Update
update比较简单,先删后增即可,注意在big query和big write当中需要支持update多个字段,其他的参照delete实现即可,应该是最简单operator了,用来熟悉一下整个sql的流程不错。
big write / query
update加上多字段支持之后直接过掉big query和big write,直接+60,恰分恰爽了。
null
参考往年的思路,选择在sys_field后添加一个null_field来表示null(个人感觉单纯用一个magic number表示null也不是不行,单纯想过test应该是可以过的)。
null_field为一个长度为32的bitmap,可以表示后面32个field是否为null,完全足够,在存储的时候直接使用一个4个字节的chars进行存储即可。
null有这么2个问题:
- update时如果从index = 0开始物化value,会读到null,之后再make_record时就会把null又给扔进去当成了一个普通的field,导致record里面有两个null_field,需要给一个sys_field_num + null_field_num的一个offset,另外一种解决方法就是重写cell_at函数,在其中给一个offset,不对外暴露sys_field和null_field
- Null 的设置时机,刚从磁盘当中读取出来的 record 是不具有 null 属性的,需要在一个合适的时机通过 bitmap 来恢复其 null 属性,最开始定义在 project operator 里面,后面发现有很多依赖 null 的 operator 在 project operator 下面,因此把这个设置 null 的过程移动到了 RowTuple 到 set_record 和 cell_at 里面,在 set_record 时,从中解析出 bitmap,之后 cell_at 时根据 bitmap 去判断是否为 null,是否允许为 null 到逻辑也在这里处理,不过既然能正确写入,这里一般是不会出问题的
此外,null还需要Field和Value为其提供支持,添加字段来表示是否允许为null和是否为null,总之null需要改动的部分非常多,当时commit时看了一眼大概修改了20个文件。。麻了 今年null的测试依赖也很多,需要实现了update-select,和unique之后才能过,而unique又依赖multi index。
text
逻辑上比较简单,但是坑不少。
逻辑上采用溢出页的方式处理比较简单,写入时按需额外去申请几个page用来存储text数据,record本身存储page_num,读取时再根据page_num去获取到真实的text内存。 今年的要求变了,text的最大长度变成了和MySQL一致的64KB,但是本身的PAGE_SIZE也从4KB变成了8KB,因此如果算上header的话,需要9个溢出页来进行存储,最长的情况为前8个page全部存满,最后一个page存部分。
因此record当中的field就需要9个int来存储,整个field占36个字节,没有用上的page在存储时就向record里面添加INVALID_PAGE_NUM,读取的时候读取到INVALID_PAGE_NUM就截断即可。 但是实现的时候在长度上有两个问题,一个是obclient无法接受超过4KB的text,超长会截断,这个需要下载readline,之后重新编译,还有一个是发送网络请求时的buffer size为8KB,全文搜索长度,之后在后面加个0就行。
在进行删除和更新上,需要首先删除溢出页当中的内容,之后再删除掉该条record,删除的话可以有两种思路,一是将该page通过init_empty_page进行初始化,之后加入到free_list当中,而是可以使用dispose将其删除,之后用来重新分配。不过我都没实现,谁让不检测呢 :)
Update mvcc
先说说MVCC本身,多版本并发控制,但是严格意义上来说并不是一个完整的并发控制协议,MVCC最大的特点是保证了读写之间不冲突,写请求不会因为正在读而阻塞写入,而读请求可以根据自身版本去读取到对自己可见的版本数据,不会被正在执行的写入阻塞。
之所以说MVCC并不是一个完整的并发控制,是因为MVCC并没有办法解决写写之间的冲突,因此需要其他的手段来加以辅助,常见的手段有基于时间戳或者基于锁的,Miniob当中的实现方式比较粗暴,只要有两个事务在更新同一个record,那么后一个事务在更新时就返回failture。
而MVCC当中的版本是基于tid的,在开启了MVCC模式之后,每一条record会生成两个sys_field,分别存储begin和end,来标识一个事务的可见性,这里似乎并没有一个统一的标准,只要能满足MVCC协议本身的要求即可,在Miniob当中的设置如下:
record通过begin和end 两个id进行状态管理,begin用于表示事务开始的时间,end为事务结束的时间,对于一条record,当一个事务开始时,新的record的begin设置为-trx_id,end为max_int32,表示事务写入但未提交,而删除时则将end设置为-trx_id,表示删除但未提交,写入操作提交时,将begin设置为trx_id,删除操作提交时将end设置为trx_id,最终会产生五种状态:
| begin_xid | end_xid | 自身可见 | 其他事务可见 | 说明 |
|---|---|---|---|---|
| -trx_id | MAX | 可见 | 不可见 | 由当前事务写入,但还未提交,对其他事务不可见 |
| trx_id | MAX | 已提交 | 对新事务可见 | 写入并且已经提交,对之后的新事务可见 |
| 任意正数 | trx_id | 已提交 | 旧事务可见,新事务不可见 | 在当前事务中进行删除,并事务提交 |
| 任意正数 | -trx_id | 不可见 | 可见 | 在当前事务中进行删除,未提交 |
| -trx_id | -trx_id | 不可见 | 不可见 | 由当前事务进行写入,并且又被当前事务删除,并且未提交 |
其中,已提交指的就是当前事务已经结束,自然不存在什么可见不可见的问题。而Miniob当中的隔离级别应当是serializable,因为未提交的事务的 begin < 0,因此是永远无法读取到新写入的record,因此是不存在幻读情况的。
对于record是否可见的判断,在visit_record当中提供了一段代码:
| |
当前存在的问题
简单来说,就是事务提交时,先插入再删除的记录行为没有得到正确的表达,产生了预期之外的表现
- 缺少begin < 0 && end < 0的处理,导致当前事务中写入的记录无法删除
- commit时存在问题,insert之后,delete的记录无法添加到operation里面,operation为一个set,set的逻辑是对于冲突的key拒绝进行添加,会导致即便修复了1, 在commit之后会出现begin = commit_id,end = -trx_id的情况,理论上这种情况不应该出现,因为delete的commit行为没有得到正确执行,如果delete的commit行为得到正确执行,就会变成begin > 0 && end > 0的情况,就可以按照版本去读取了。




对于上面说到的第一点,少了对begin < 0 && end < 0的判断,在这种情况下,为当前事务写入,又被当前事务删除,但是事务还未提交,此时应当对当前事务是不可见的,但是根据目前的条件结构,会返回SUCCESS,这样会导致在当前事务中进行delete但是仍可见的问题,或者当前事务中进行update,但是旧数据还存在的问题。需要补充一条逻辑,在这种情况下返回不可见
如下面的例子:
原本(4,4,‘a’)的record是由上一个事务写入的,并且提交(begin_xid > 0),此时更新就不会出现问题,而(4,761,‘a’)的record是当前事务写入的,还未提交,begin_xid < 0,删除之后end_xid < 0,上面漏了对这种情况的判断,从而导致其又可见。
对于说到的第二点,表现形式就是如果当前的事务commit之后,这条记录就又可见了
 下图是我用初始版的miniob做的测试,可以确认的确存在这个问题
下图是我用初始版的miniob做的测试,可以确认的确存在这个问题

修复方式
描述完产生的问题,再来说一下为什么会有这种问题和解决方式。 产生的原因主要有两个:
- set逻辑错误,原本想的是对于同一条record的操作,后面的覆盖前一条,最后提交时只会执行最后一条,但是c++当中的std::set对于重复key的插入操作会直接拒绝,导致没能够正确的覆盖
- 覆盖逻辑:因为采用覆盖的方式执行,因此对于在当前事务当中插入的数据,在commit时delete会覆盖掉insert的动作,就会导致一个问题:insert的commit动作没有正确得到执行,出现了begin < 0 end > 0的情况,在原本的tid校验当中没有判断,而commit前的begin < 0 end < 0的情况同样也没有判断 大概想了两版修复方式:
第一版比较复杂,逻辑上感觉更符合mvcc的含义:
由当前事务写入的记录无法被删除:
当前事务写入的记录为begin = -trx_id,end = MAX,之后由当前记录进行删除之后,变为begin = -trx_id,end = -trx_id,当前visit_record当中缺少对于这种情况的判断
解决方案:添加对begin < 0 && end < 0的判断,意义是由当前事务写入,并由当前事务删除,状态为对所有事务都不可见
commit动作没有被正常执行
当前事务使用rid作为key,使用std::unordered_set进行存储,保存当前事务的operation,留在提交时进行执行,同一个rid的operation应当后者覆盖前者,但是set对于已经存在了的key无法正确插入,无法正确覆盖。
解决方案: 在进行delete操作时进行特判,如果原本存在对应的key的话(即当前事务进行了一次插入操作),就删除原本的key,重新插入,以达到覆盖的效果
- insert由于即便insert相同的record,rid也不一致,无需处理。
- 其他的事务进行的插入不是同一个set,不会产生影响
- 当前事务插入的其他的记录由于 rid 不一致,无需处理
垃圾回收问题:
如果在当前事务中删除已经提交的事务写入的记录,不会出现任何问题,因为插入操作在进行提交时会将begin设置为commid_tid,从而有了正确的版本信息,之后delete时,只需要修改end = tid即可,而无论进行回滚还是提交,都可以保证一个正确的状态:
- 提交:end = commid_tid,可以根据版本去正确读取
- 回滚:end = MAX,恢复到刚写入的状态
如果是当前事务写入又由当前事务提交,则存在一定问题,由于在同一个事务当中,同一条记录后面会覆盖前面,从而导致如果进行写入又删除的话,begin会保留-tid的状态,此时无论进行commit还是rollback都只会执行delete的operation,从而该条记录的begin会一直保持-tid,给垃圾回收和正确读取带来困扰。
可以考虑:
- 如果是提交操作,那么就将begin = end = tid,意义为当前事务写入又由当前事务删除,不会影响读取
- 如果是回滚操作,那么就调用table→delete_record进行真正的删除,由于该记录从未对外暴露过,因此删除不会影响其他事务的读取,并且在逻辑上也符合回滚的概念。
第二版的实现方式比较的取巧,针对问题出现的源头进行修复:就是在trx.delete_record加个特判,如果是自己写入的进行删除,就直接调用delete_record,并且也不添加到operation_里面,并且删除之前的insert操作的operation,由于是自己创建的record,并且又被自己删除,因此就当作其从来没有存在过。
在这种情况下,既不影响回滚,也不影响gc,最终实现也是采用第二种方式
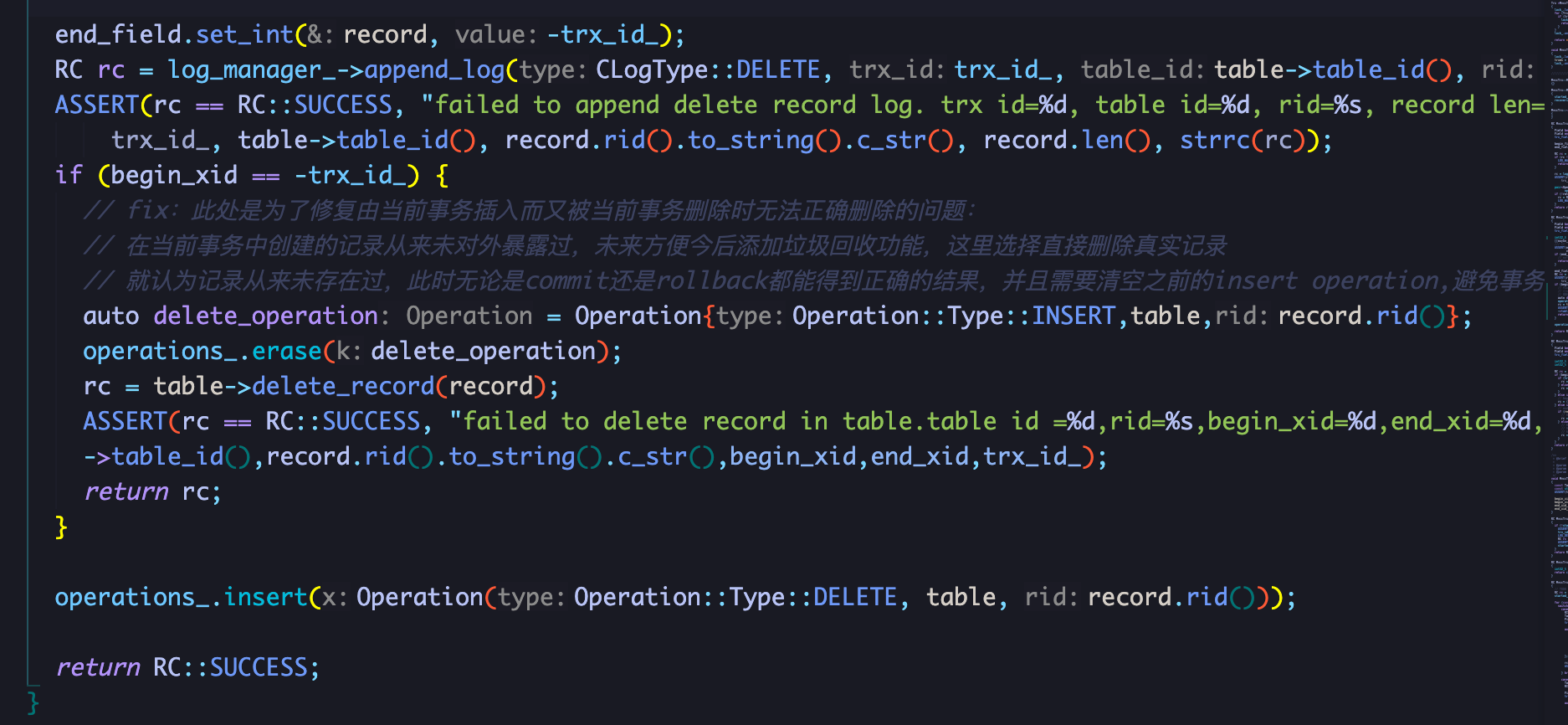
回到正题,update-mvcc这题其实是不怎么需要实现的,大多数人在完成了unique之后,update-mvcc是可以直接通过的,因为目前miniob已经给出了mvcc的insert和delete实现,组合一下即可。不过由于我们队unique index实现的是一个fake版本,在mvcc模式下并没有办法提供唯一性保证,而我又不想去重构,因此我们队分了两条线进行,队友去重构unique index,我特判表名然后实现一个内存当中的mvcc版的unique index,其实就是把visit_record当中的逻辑对着unique_index实现了一遍,不过最后是我先搞出来了hhh。
| |
在完成了unique index之后还存在一个问题,就是mvcc模式下,update时,下层的table_scan会把新写入的record又给读出来,从而导致又insert一遍,再加上我最开始visit_record当中begin < 0 end < 0的bug没修,从而导致其会逃过unique的限制,表现结果就是一个update更新了两次。 问题的源头是table_scan会读取到新写入的record,不过当时没仔细看到底为什么,只是修了visit_record和在update当中加了一层限制,即如果原记录和新记录完全一致的话,就不进行更新,这样勉强算是把窟窿给堵上了,最后也是通过了测试。
| |