Manu: A Cloud Native Vector Database Management System
Introduction
Manu或者其前身Milvus,定位目标是云原生的向量数据库,需要提供基础的向量存储和检索服务,同时,相比传统的云原生DBMS,主要有以下的特点:
- 无需支持复杂的事务:传统DBMS通常需要支持多表,多行的复杂事务处理逻辑,但是这在VDBMS当中是没有必要的, 因为非结构化数据通常通过AI模型转化为单一的向量,最基本的ACID就足够了
- 提供一个可调节的性能和一致性之间的trade-off
- 提供细粒度的弹性伸缩以避免硬件资源的浪费:VDBMS 涉及到很多硬件加速,如 GPU 或者 FPGA,以及大量的内存。通过将函数层或者逻辑层与硬件层进行解耦,以避免非峰值期的浪费 (参考 snowflake 的设计),弹性和资源应该在函数层进行管理而不是系统层
log as data
Manu的设计准则为日志即数据,整个系统通过一个日志的订阅/发布系统进行管理,通过日志来完成各个层之间的解耦(decoupling of read from write, stateless from stateful, and storage from computing)
日志机制上使用了MVCC和time-tick,后面进行详细介绍
在向量检索上,支持量化、倒排索引、临近图等结构
Background And Motivation
这里前半部分说的还是VDBMS那几个老生常谈的特性。其他的话
- 首先说明了VDBMS目前的架构是不成熟或者会持续发展的,由于目前VDBMS主要是给AI或者数据驱动类型应用服务的,因此随着这些上层应用的发展,VDBMS也会带动着一同革新。
- 无需支持复杂事务,基础ACID即可
- 矢量数据库应用程序需要灵活的性能一致性 trade-off。如在视频推荐的场景下,拿不到最新上传的视频是可以接受的,但是让用户长时间等待是万万不可的。可以通过配置最大的延迟时间来提高系统的吞吐量。这里的设计就有点像搜索引擎了,少检索出那么几条数据又如何呢,这也是早年 GFS 采取弱一致性的原因。
做总结,Manu的设计目标如下:
- 支持长时间的迭代更新
- 一致性可调
- 良好的弹性
- 高可用性
- 高性能
- 强适应性
The Manu System
Schema, Collection, Shard, and Segment
schema:数据类型上支持基本数据类型 + vector,一条记录由user field和sys field两部分组成:
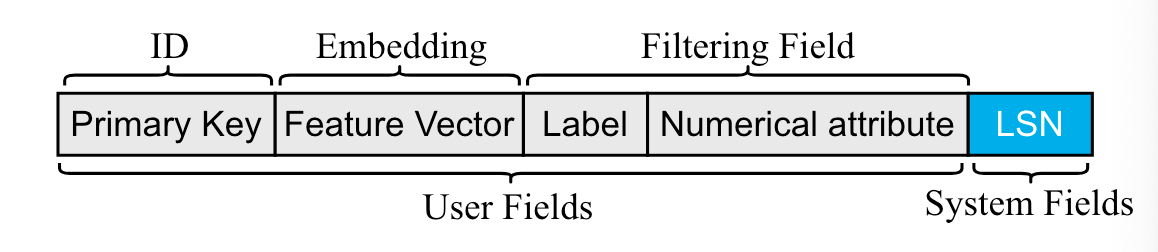 其中,label和numerical attribute组成了过滤字段,label就是传统意义上的标签,如衣服,食物等,numerical attribute即为和该条记录相关的数值属性,如身高,价格等。
其中,label和numerical attribute组成了过滤字段,label就是传统意义上的标签,如衣服,食物等,numerical attribute即为和该条记录相关的数值属性,如身高,价格等。
sys field的LSN对于用户是不可见的,用于系统内部使用
collection: 作为entity的集合,对应DBMS当中的表的角色,但最大的区别是不存在关系的概念,不会和其他的collection之间存在relation,同样也不支持关系代数
shard: 在插入时,entity会根据ID hash到多个shard当中,但是在manu当中,shard并部署数据的存储(placement)单元
segment: 每个shard当中的entity通过segment来进行管理,segment可以有两种状态:
- growing:可以向其中添加新的entity,到达512MB转换为sealed,或者一段时间没有向其中添加新的数据
- Sealed:不接受新的 entity,为只读的状态
小的segment可以进行合并
对于shard和segment,这里说的比较简陋,在后面日志部分有详细描述,shard是一个较大的单位,对应了一个存储节点的概念,记录通过哈希找到自己所属的存储节点,而segment则是数据的存储或者管理单元,有点类似于chunk的这个概念。
System Architecture
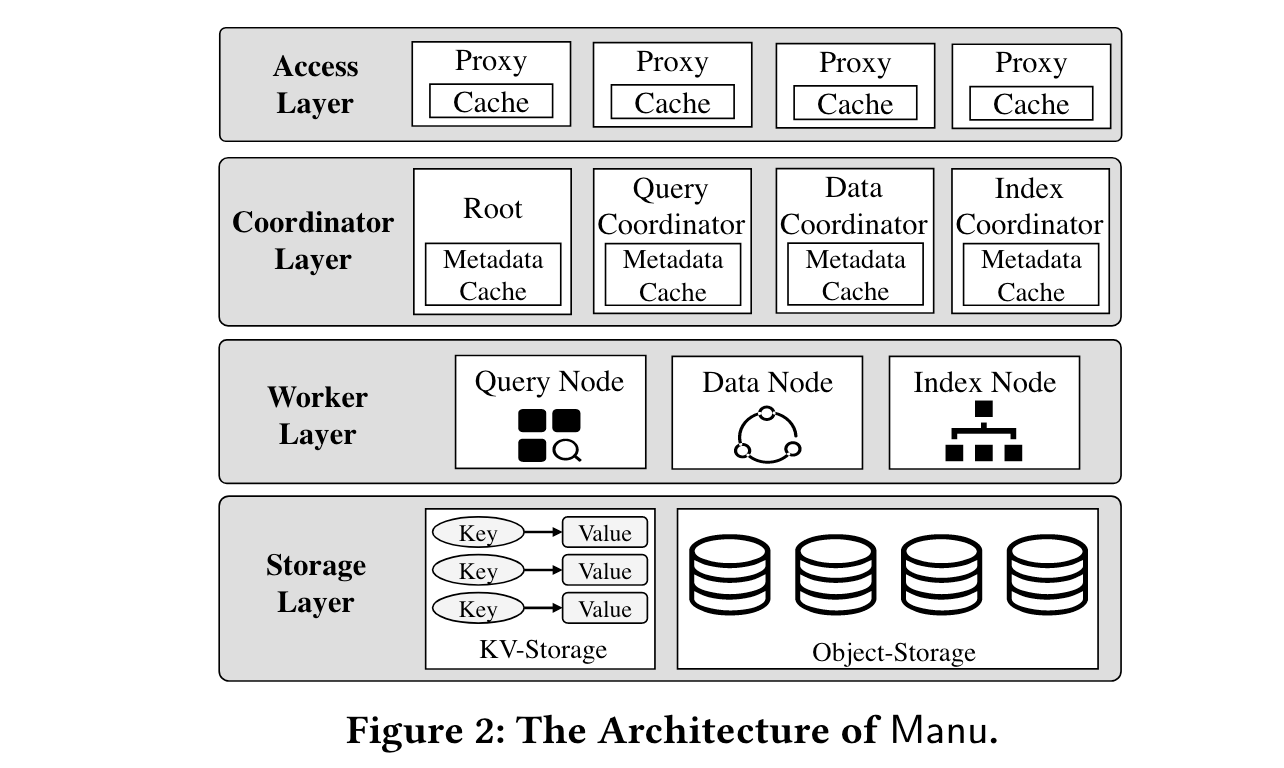
根据上面描述的种种云原生向量数据库的需求,Manu在架构上进行细粒度的解耦,分为了多个层,每层各司其职,这里的解耦比像snowflake那样的存算分离要彻底一些。
Access layer
位于整个系统的最上层,采用无状态(stateless) + 缓存的设计方式,代理客户端的请求,并将其转发到对应的下层节点上。
Coordinator layer
在这一层当中存在四个Coordinator,分别负责不同的工作: Root,Query,Data,Index
- Root主要处理创建/删除collection的操作(对应 sql当中的ddl),并且维护collection的元数据
- Data负责维护一个collection的详细信息,如segment的路由或者路径,并且可以和底层的data node合作将更新的数据转换为binlog
- Index 维护索引的元数据和创建索引工作
- Query 显而易见
Worker layer
负责真实的计算任务,节点为无状态的,只会从存储节点获得一份copy来进行计算,各节点之间不存在交互。为了保证可以根据需求扩充,将节点根据任务类型划分为了query data index三种类型
Storage layer
- 使用etcd来存储系统状态和元数据
- 使用AWS S3作为对象存储,存储segment/shard
Log Backbone
日志作为骨架,将解耦的系统组件连接成一个整体。日志使用wal + binlog的组合,wal作为增量部分,bin作为基础部分,二者相互补充。data node订阅wal,然后将row-based的wal转换为column-based的binlog。
所有会更改系统状态的操作都会记录到日志当中,包括ddl、dml,和一些system coordination的操作(向内存当中加载collecion)。而只读请求不会进入日志。
日志采用的是逻辑日志而非物理日志
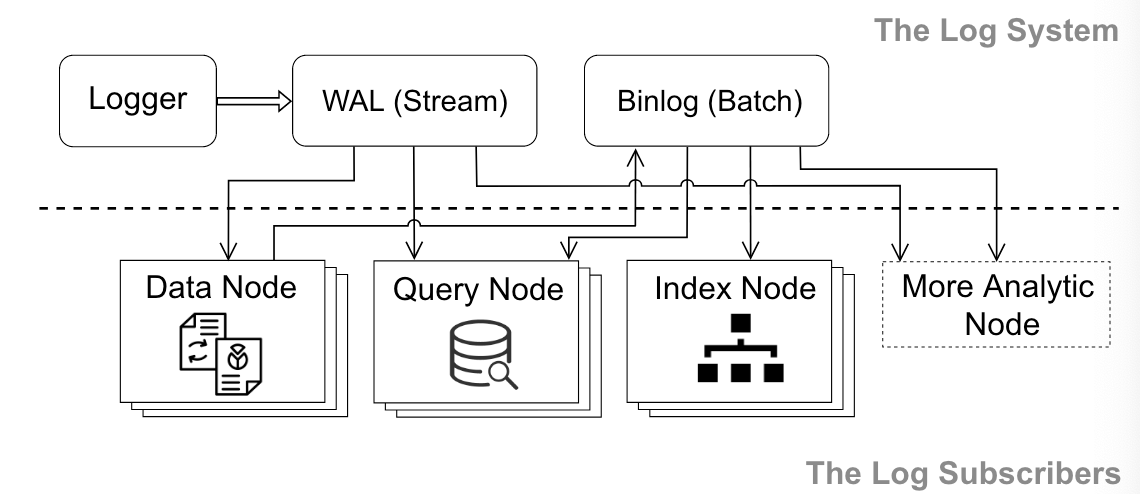
日志系统的架构如下:
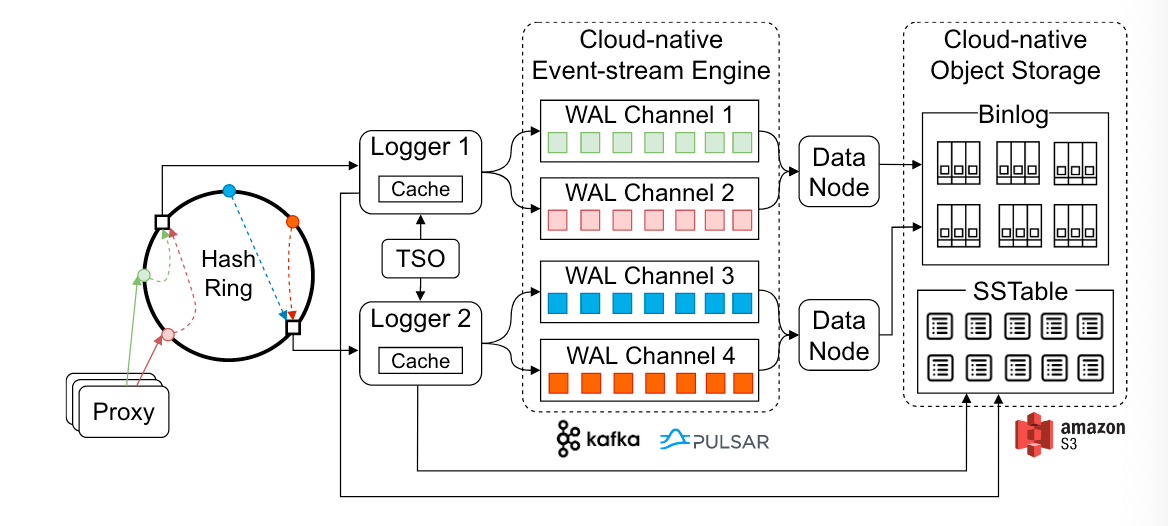
- logger通过一致性哈希进行管理,相比于普通的哈希函数,可以得到一个较好的负载均衡并且在添加或者删除节点时影响到的节点较少。
- 每一个shard对应哈希环上的一个逻辑哈希桶(其中对应多个物理哈希桶),并且和wal channel一一对应
- 对于一次请求,首先根据ID进行哈希到对应的logger,再使用TSO(实现方式为混合时钟)进行分配一个全局的LSN,根据LSN划分到对应的segment当中,然后将其写入到WAL当中,此外还会维护一个entity ID到segment ID的一个映射,使用rocksdb进行存储,并缓存在logger当中。
- WAL channel本身提供一个发布订阅功能,本身相当于一个消息队列,在实现上使用kafka等,logger相当于发布端,data node订阅该channel,将row-based的wal转换为column-based的binlog。而之所以使用column-based的形式,还是VDBMS的检索服务本质上还是有点类似OLAP场景,列式存储可以提供较好的存储和IO性能。
- 组件间的消息也通过日志传递,例如,数据节点宣布何时将段写入存储,索引节点宣布何时构建索引。这是因为日志系统提供了一种简单可靠的机制来广播系统事件
Tunable Consistency
Manu引入了“delta一致性”(delta consistency),这种一致性模型位于强一致性和最终一致性之间。在这种模型下,读操作返回的是最多在delta时间单位之前产生的最后一个值。这里的“delta”是一个可调整的时间参数,可以根据需要设置。值得注意的是,强一致性和最终一致性可以看作是这个模型的特殊情况,其中delta分别为零和无限大
为了实现delta一致性,分为两方面:
- 首先实现TSO来生成全局唯一的LSN,这里使用了混合时钟,物理部分记录物理时间,逻辑部分记录时间顺序。逻辑部分用于确定事件的先后顺序,而物理部分用于和delta配合来设置容忍的延迟。不过这里TSO是单机实现的,有可能成为整个系统的瓶颈。虽然都使用了HLC,到那时和cockroachdb是不同的。
- 二是使用了time-tick的策略,简单来说这个实现有点像机枪的曳光弹,每隔几发就添加一发曳光弹来进行标识
- 作为日志订阅者的query node,需要知道三件事:1)用户设定的delta,2)上次更新的时间,3)查询请求的时间
- 使用time-tick策略,在日志当中会定期的插入带有时间的特殊日志标志,将最后一次的时间记为 $L_s$ ,而请求又会带上$L_r$,只有满足了$L_r - L_s < \delta$ 的情况下查询才会返回,否则一直等待
Index Building
Manu支持的索引类型如下:
 Manu当中并没有提出什么新颖的索引类型,在这一段,主要阐述了两种索引构建场景。分别是批处理和流处理:
Manu当中并没有提出什么新颖的索引类型,在这一段,主要阐述了两种索引构建场景。分别是批处理和流处理:
- 批处理发生在对于整个collection构建索引的情况,在这种情况下,index coordinator知道collection涉及的所有的segment的路径,然后指示index node去创建索引。
- 流处理则是增量情况,索引是在不停止搜索服务的情况下实时异步构建的。当一个Segment积累了足够数量的向量后,其驻留数据节点会密封该Segment并将其作为binlog写入对象存储。然后数据协调器通知索引协调器,索引协调器指示索引节点为该段建立索引 Manu通过bitmap来记录被segment当中删除的向量,而被删除的向量数量达到一定程度后,会重新构建索引
Vector Search
先说几个特性:
- 可以使用距离或者相似度函数进行搜索,如欧几里得距离,内积,角距离等
- 使用cost-based模型来选择执行策略
- 支持多向量检索
查询加速
Collection被分为segment,然后在各个segment上进行并行查询,在每个段上进行top-k查询,之后再使用一个聚合函数处理各个段上的top-k向量,聚合得到一个全局的top-k结果
数据来源
像之前说的那样,Manu使用的是存算分离的架构,计算节点获取一份copy进行计算。因此查询节点共有三个数据来源:WAL,索引,binlog:
- 对于还处于growing持续写入的segment,查询节点可以通过订阅WAL的方式,然后在其中进行暴力扫描得到结果,以求最小延迟。但是暴力扫描的开销依旧很高,给出的对策是将segment划分为切片(slice),一个切片包含1w条vector,一旦一个切片完成了写入,就对其建立临时索引以加速搜索,大约可以提升10x
- 而从growing转换为sealed的segment,就可以对其建立完整的索引,并存储在AWS S3当中,之后通知查询节点去加载完整索引来替换掉临时索引
- 当查询节点之间的segment分布发生变化时,查询节点会访问 binlog 来获取数据,这种情况可能发生在扩展、负载均衡、查询节点故障和恢复期间
- 当查询节点发生故障时,或者节点被移除时(scaling down)其负责的任务对应的segment和索引就会被加载到另外一个正常的节点当中
- 当新节点被添加到其中时,同样也会有类似的操作
原子性
Manu 不确保段重新分配是原子的,并且一个段可以驻留在多个查询节点上。这不会影响正确性,因为代理会删除查询的重复结果向量。
剩余的部分可能大多都是些向量特点并不是那么鲜明的内容和一些用例分析了,这里就不做过多的分析了。
Summary
在我看来《Manu: A Cloud Native Vector Database Management System》这一篇文章工程实践性比较强的文章了,文中并没有对于向量数据库的核心,即向量检索和索引方面提出什么创新性的设计,而是更注重架构方面,从架构方面出发,讲述了向量数据库和云原生架构之间的一个化学反应。同时zilliz也算是比较出名的向量数据库的初创了,还是比较看好其发展的。