Raft选举流程#
引用:http://blog.mrcroxx.com/posts/code-reading/etcdraft-made-simple/3-election/
Raft选举流程优化#
对于Raft的基本实现,呈现在Diego Ongaro的《In Search of an Understandable Consensus Algorithm (Extended Version)》一文当中。实现了Raft的基本功能。而又在Ongaro的博士论文当中,对于Raft的选举流程提出了三种优化,分别是Pre-Vote,Check Quorum、Leader Lease。
PreVote#
想象这样的一种场景,在一个五个节点的Raft集群当中发生了网络分区, 分为了一个三个节点的分区和一个两个节点的分区。
三个节点的分区当中如果不发生宕机的话,由于满足Quorum数,Leader可以一直维持他的任期,因此Term一直不变。但是两个当中的节点数不足,因此一直会尝试Leader Election的过程, 又因为节点数不足,选举一直不会成功,而在这个过程当中,节点每次进行选举都会自增自身的Term号。
当网络分区恢复之后,两个分区又能够互通,此时3个节点的分区当中的Leader会收到来自二节点的RequestVote,并且Term高于自身的Term,从而会导致Leader转换为Follower,之后在重新进行一轮选举。
在这种情况下,会导致系统的Term无意义的增大,并且在网络分区恢复时会额外进行一次选举。
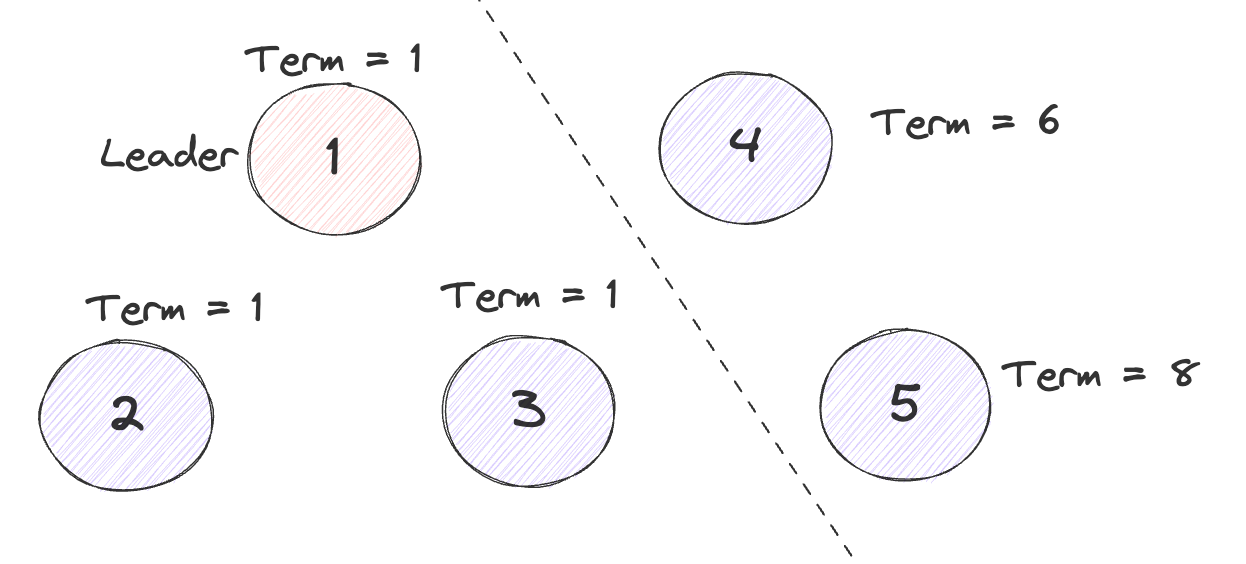
通过PreVote的机制,可以解决以上问题,在正式投票之前,先进行一轮遇投票,在预投票阶段不对自己的Term进行自增,如果在预投票当中能够选出Leader,即超过1/2的节点给出赞成投票,那么就可以对自己的Term进行自增,进行正式的选举过程。此时就可以保证在上面的例子当中右边的分区由于一直无法选举出Leader,从而不会对Term进行自增,之后网络分区恢复之后,Term也一定 <=主分区的Term,从而可以很自然的加入到主分区当中,不会引起当前Leader的退位。
Check Quorum#
还是以刚才的例子,但是这次在出现网络分区前Leader位于右边的分区当中,虽然此时新的请求再也无法达成共识,但是由于Raft的节点不会主动的检测当前集群的状态,因此此时的Leader仍认为自己为Leader,还会不断的接受新的请求和发送心跳信息。
如果像MIT6.824当中那样通过Raft日志来保证强一致性,即每条请求无论读写都将其写入到Raft日志当中形成共识,当达成共识之后再给予客户端响应。此时在少数分区当中的Leader接受了请求也无法达成共识,从而会超时向客户端报错。之后客户端就可以判断当前的Leader为不可用状态。此时没有出现任何问题。
但是用于网络应用通常为读多写少的类型,此时使用Log Read会导致读的性能很差,因此可以采用在Leader进行本地读的方式,提高读取性能。
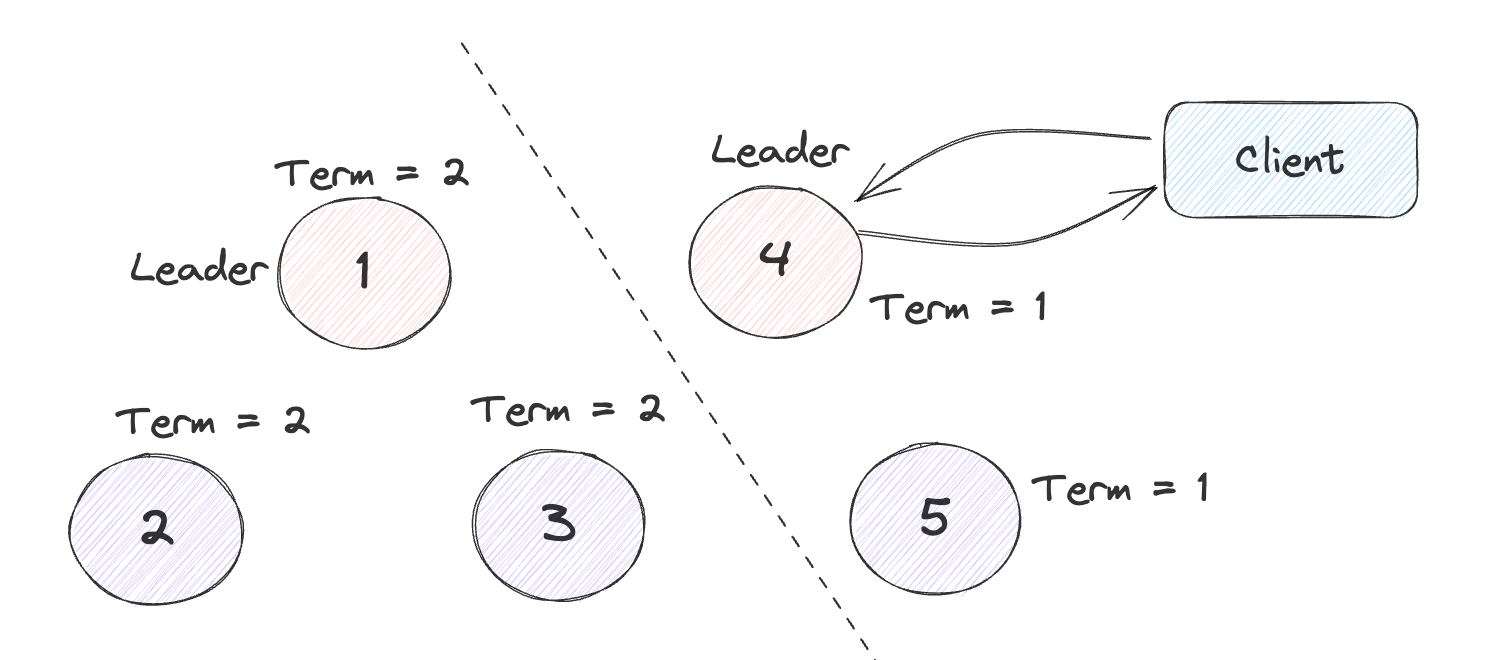
但是此时如果发生上述的网络分区问题时,就会读取到旧的数据,违反线性一致性。
在开启Check Quorum后,Leader会周期性的向Follower去发送一条信息,去确认当前集群当中的存活的Follower数量,是否满足Quorum,如果不满足,则证明此时发生了网络分区,并且当前的Leader处于节点数少的那个分区,此时Leader就应当退位变为Follower。通过Check Quorum机制可以尽早的发现网络分区的问题,但是依旧不能完全解决stale read的问题,需要其他的手段来保证强一致性。
Leader Lease#
在分布式环境下,可能会出现部分网络分区的问题,即A-B B-C之前都能相互通信,但是A-C之间不通。
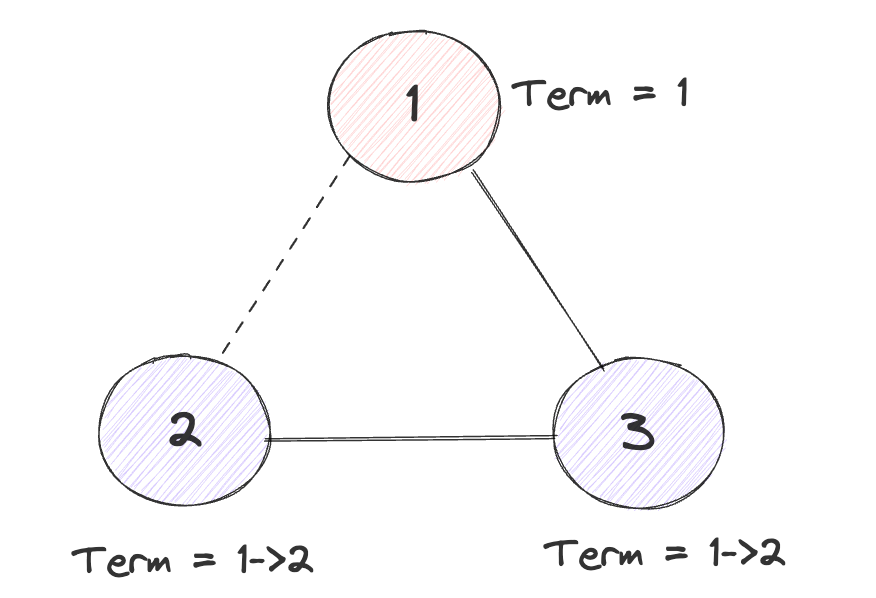
此时节点2会因为收不到节点1的消息而尝试重新进行选举,而在节点2和节点1发生网络部分分区到节点2超时重新选举这段时间内如果1 3没有写入新的Log,节点2就可以拿到自身和节点3的选票,从而成为Leader。由于选举导致的节点Term增加就会从2 传到 3,之后1再向3发送消息就会因为Term低于节点3而变为Follower,最终节点2会成为整个集群新的Node,但是集群的状态也原本并没有什么差异,可以视为一个无意义的选举。
通过Leader Lease可以解决该问题:当节点在Election Timeout超时之前,如果收到了Leader的消息,那么他就不会再去响应其他节点发起的RequestVote的投票和预投票的消息。即阻止正常工作的节点给其他节点进行投票。
Leader Lease机制需要和Check Quorum配合使用,一种可能的局部网络分区如下:
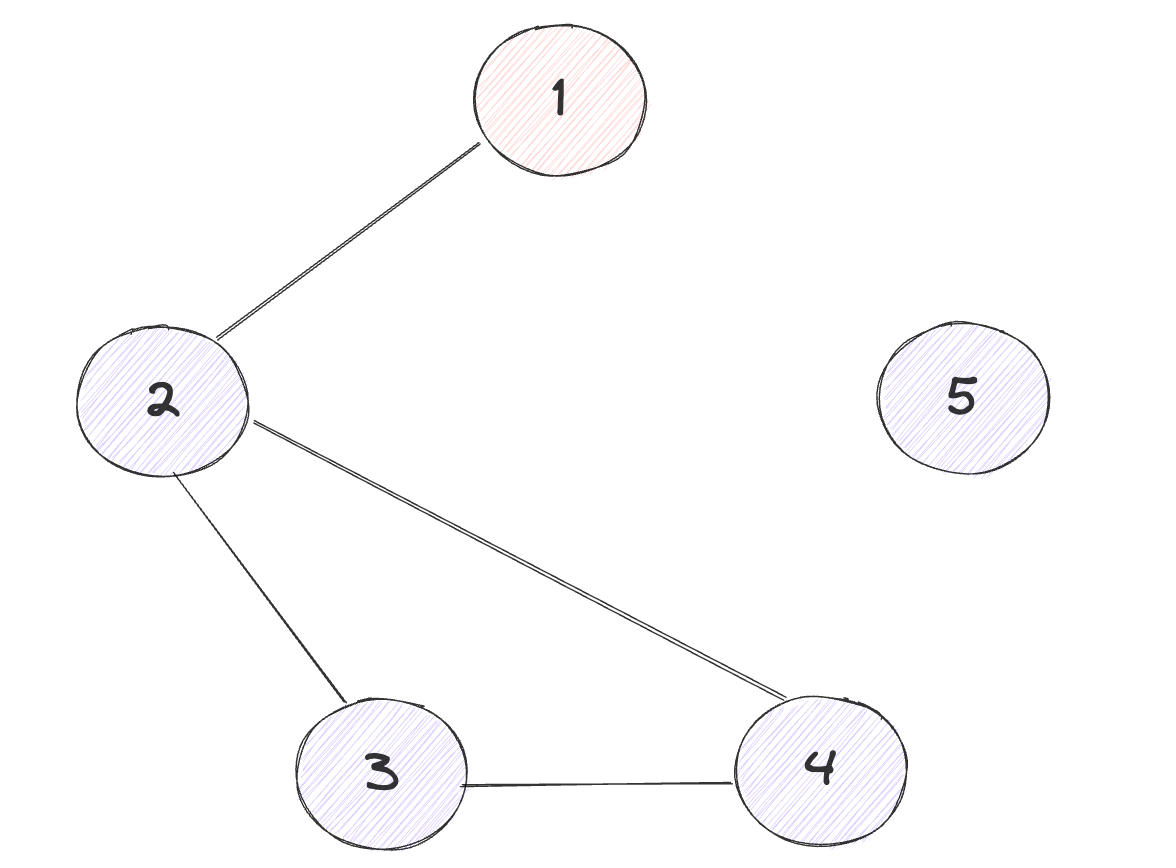
此时理想状态为3 4 发起选举,产生新的集群[2 3 4],如果只引入了Leader Lease机制,此时只有2可以与Leader1进行正常通信,因此此时的2不会开启选举也不会为其他人投票,3 4 最多只能得到两票从而无法选举出Leader,而如果引入Check Quorum机制之后,Leader最多只能检测到一个节点,因此就会退位,从而不会因为Leader Lease干扰正常的选举流程,2 3 4形成新的可用集群。
优化引入的问题#
在引入Leader Lease并顺带开启Check Quorum之后,无论是否开启PreVote,都会引入新的问题,假设不开启PreVote,在发生网络分区之后,节点3就会不断的自增自己的Term,而如果开启了Leader Lease,节点1 2就会忽略节点3的投票信息,或节点1 2写入了新的日志,由于日志的安全性问题忽略3的RequestVote,而节点1 2向节点3发送的消息也会因为Term过低而导致被忽略。
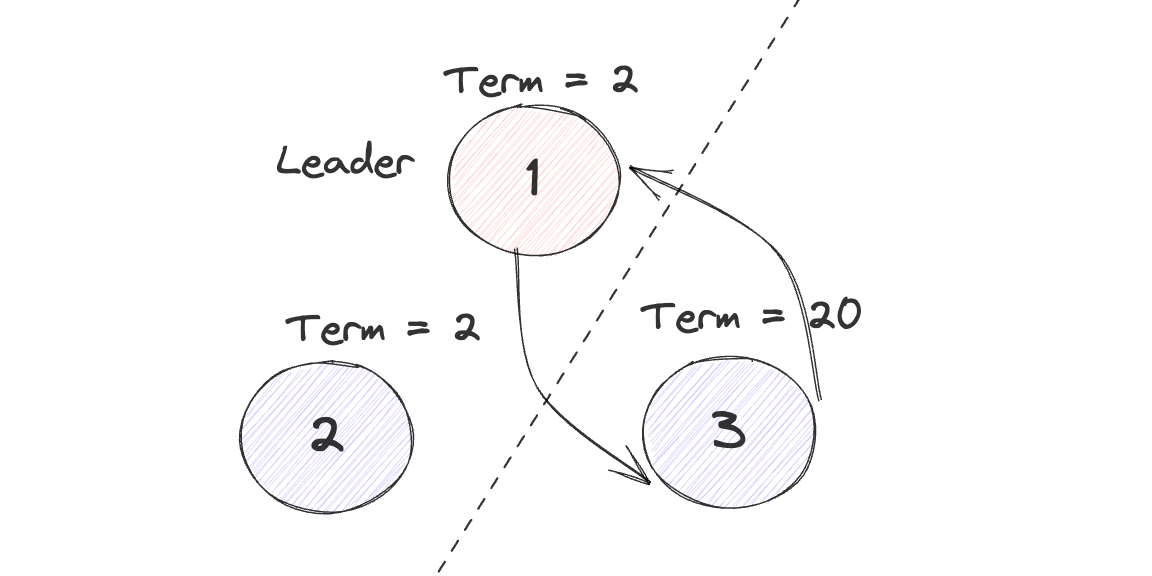
而如果引入了PreVote之后也会产生类似的情况,网络分区恢复之后节点3发起一轮PreVote,并得到了节点1 2 的回应,又产生了节点3的Term比1 2高的问题
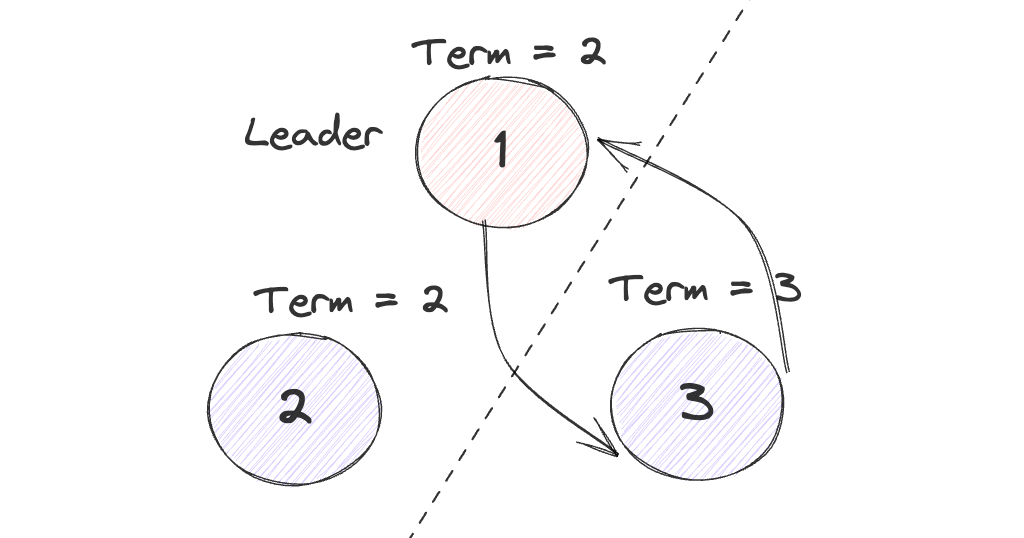
在原本的Raft当中,节点1 2收到了3的RequestVote,由于3的Term更高,从而会令1退位并更新Term,2更新Term,之后即可在相同的Term下进行新一轮的选举,从而避免了上述的情况。
处理方法也很简单,按照和原本差不多的思路进行处理,原本会自动处理跟随高Term,此处就手动发送一次高Term强制跟随:如果收到了term比当前节点term低的leader的消息,且集群开启了Check Quorum / Leader Lease或Pre-Vote,那么发送一条term为当前term的消息,令term低的节点成为follower
配置更新
在更复杂的情况中,比如,在变更配置时,开启了原本没有开启的Pre-Vote机制。此时可能会出现与上一条类似的情况,即可能因term更高但是log更旧的节点的存在导致整个集群的死锁,所有节点都无法预投票成功。这种情况比上一种情况更危险,上一种情况只有之前分区的节点无法加入集群,在这种情况下,整个集群都会不可用
处理方法为对于term比当前节点低的Term的PreVote,无论是否开启了Check Quorum Leader Lease,都通过发送一条为当前Term的信息,迫使其转换为Follower并更新Term。
选举流程#
RaftNode/Campaign#
在Node接口当中,对外提供了一个Campaign函数,调用该函数即可以MsgHup为参数调用step(此处调用的为stepFollower),从而开启选举的过程
1
2
3
| func (n *node) Campaign(ctx context.Context) error {
return n.step(ctx, pb.Message{Type: pb.MsgHup})
}
|
但是更为常见的为通过Tick()函数进行触发,经过在上一章当中分析的Tick流程,最终调用到了follower或者candidate的tickEelction,之后在调用Step,在其中触发选举
1
2
3
4
5
6
7
8
9
| // tickElection is run by followers and candidates after r.electionTimeout.
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
|
hup/campaign#
最终的选举逻辑是在hup/campaign函数当中进行处理的,先看一看当中的逻辑,之后再研究这两个函数的调用时机
hup#
hup函数经过一定的检查之后开启选举过程:
- 当前如果为Leader,那么则不能够进行选举
- 通过
promotable查看当前节点是否能够提升为Leader - 查看当前是否有还有提交的日志。
- 当前的节点已提交的日志中,是否有还未被应用的集群配置变更
ConfChange消息,如果有,依旧不能进行选举 - 如果上述检查全部通过,那么即可尝试进行选举
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| func (r *raft) hup(t CampaignType) {
if r.state == StateLeader {
r.logger.Debugf("%x ignoring MsgHup because already leader", r.id)
return
}
if !r.promotable() {
r.logger.Warningf("%x is unpromotable and can not campaign", r.id)
return
}
ents, err := r.raftLog.slice(r.raftLog.applied+1, r.raftLog.committed+1, noLimit)
if err != nil {
r.logger.Panicf("unexpected error getting unapplied entries (%v)", err)
}
if n := numOfPendingConf(ents); n != 0 && r.raftLog.committed > r.raftLog.applied {
r.logger.Warningf("%x cannot campaign at term %d since there are still %d pending configuration changes to apply", r.id, r.Term, n)
return
}
r.logger.Infof("%x is starting a new election at term %d", r.id, r.Term)
r.campaign(t)
}
|
promoptable:
在该函数当中主要检查三条:
- 当前节点是否为新加入集群当中追赶进度的Learner
- 当前节点是否属于当前的集群
- 是否还有未应用的Snapshot
1
2
3
4
5
6
| // promotable indicates whether state machine can be promoted to leader,
// which is true when its own id is in progress list.
func (r *raft) promotable() bool {
pr := r.prs.Progress[r.id]
return pr != nil && !pr.IsLearner && !r.raftLog.hasPendingSnapshot()
}
|
之后,即可调用campaign尝试进行选举
campaign#
由于调用campagin的位置并不只hup当中,因此最初首先也需要检查promotable。
调用campaign时,传入一个参数表示当前为预选举还是正式选举。之后根据该参数对当前节点的状态进行更新
1
2
3
4
5
6
7
8
9
10
| if t == campaignPreElection {
r.becomePreCandidate()
voteMsg = pb.MsgPreVote
// PreVote RPCs are sent for the next term before we've incremented r.Term.
term = r.Term + 1
} else {
r.becomeCandidate()
voteMsg = pb.MsgVote
term = r.Term
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| func (r *raft) becomeCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> candidate]")
}
r.step = stepCandidate
r.reset(r.Term + 1)
r.tick = r.tickElection
r.Vote = r.id
r.state = StateCandidate
r.logger.Infof("%x became candidate at term %d", r.id, r.Term)
}
func (r *raft) becomePreCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> pre-candidate]")
}
// Becoming a pre-candidate changes our step functions and state,
// but doesn't change anything else. In particular it does not increase
// r.Term or change r.Vote.
r.step = stepCandidate
r.prs.ResetVotes()
r.tick = r.tickElection
r.lead = None
r.state = StatePreCandidate
r.logger.Infof("%x became pre-candidate at term %d", r.id, r.Term)
}
|
在完成了状态更新之后,当前节点首先投自己一票,这个操作是通过poll函数完成的,这个过程并不涉及到任何的rpc,只是单纯的投自己一票并进行记录,之后在根据配置文件来统计是否赢得选票,如果能够赢得选票,则证明当前的raft是以单节点的状态启动的,集群当中只有这一个节点。直接结束当前的选举流程,成为Leader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| func (r *raft) poll(id uint64, t pb.MessageType, v bool) (granted int, rejected int, result quorum.VoteResult) {
if v {
r.logger.Infof("%x received %s from %x at term %d", r.id, t, id, r.Term)
} else {
r.logger.Infof("%x received %s rejection from %x at term %d", r.id, t, id, r.Term)
}
r.prs.RecordVote(id, v)
return r.prs.TallyVotes()
}
func (p *ProgressTracker) RecordVote(id uint64, v bool) {
_, ok := p.Votes[id]
if !ok {
p.Votes[id] = v
}
}
|
1
2
3
4
5
6
7
8
9
10
| if _, _, res := r.poll(r.id, voteRespMsgType(voteMsg), true); res == quorum.VoteWon {
// We won the election after voting for ourselves (which must mean that
// this is a single-node cluster). Advance to the next state.
if t == campaignPreElection {
r.campaign(campaignElection)
} else {
r.becomeLeader()
}
return
}
|
而如果只靠自己给自己投票无法赢得选举的话,就需要借助发送rpc来请求其他的节点给自己投一票,这个发送的过程通过send添加到自身的[]Messages当中,交给上层的raft server去完成网络通信,等待对方投票完成后调用Step并向其中传入一个MsgHupResp的消息类型进行处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| var ids []uint64
{
idMap := r.prs.Voters.IDs()
ids = make([]uint64, 0, len(idMap))
for id := range idMap {
ids = append(ids, id)
}
sort.Slice(ids, func(i, j int) bool { return ids[i] < ids[j] })
}
for _, id := range ids {
if id == r.id {
continue
}
r.logger.Infof("%x [logterm: %d, index: %d] sent %s request to %x at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), voteMsg, id, r.Term)
var ctx []byte
if t == campaignTransfer {
ctx = []byte(t)
}
r.send(pb.Message{Term: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
|
只是简单的将msg添加到[]Messages当中,之后通过Ready()交给上层进行发送
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| func (r *raft) send(m pb.Message) {
if m.From == None {
m.From = r.id
}
if m.Type == pb.MsgVote || m.Type == pb.MsgVoteResp || m.Type == pb.MsgPreVote || m.Type == pb.MsgPreVoteResp {
if m.Term == 0 {
// All {pre-,}campaign messages need to have the term set when
// sending.
// - MsgVote: m.Term is the term the node is campaigning for,
// non-zero as we increment the term when campaigning.
// - MsgVoteResp: m.Term is the new r.Term if the MsgVote was
// granted, non-zero for the same reason MsgVote is
// - MsgPreVote: m.Term is the term the node will campaign,
// non-zero as we use m.Term to indicate the next term we'll be
// campaigning for
// - MsgPreVoteResp: m.Term is the term received in the original
// MsgPreVote if the pre-vote was granted, non-zero for the
// same reasons MsgPreVote is
panic(fmt.Sprintf("term should be set when sending %s", m.Type))
}
} else {
if m.Term != 0 {
panic(fmt.Sprintf("term should not be set when sending %s (was %d)", m.Type, m.Term))
}
// do not attach term to MsgProp, MsgReadIndex
// proposals are a way to forward to the leader and
// should be treated as local message.
// MsgReadIndex is also forwarded to leader.
if m.Type != pb.MsgProp && m.Type != pb.MsgReadIndex {
m.Term = r.Term
}
}
r.msgs = append(r.msgs, m)
}
|
Step预处理#
Step函数包含了所有对状态机进行更改的操作,但是通过stepxxx + 通用处理的拆分之后逻辑上相当的清晰,主要负责一下四种操作,其他的全部交给stepxxx去单独处理:
- 处理比当前节点Term高的消息
- 处理比当前节点Term低的消息
- 通过hup进行选举
- 处理Vote PreVote授予投票
比当前Term高的消息:#
如果收到了一个更高的Term,并且如果为PreVote或者Vote类型的消息,如果Check Quorum通过,并且当前节点持有(暂时这么形容)Leader Lease,那么就对其忽略,直接返回。
此外还有一个force变量,用于表明针对优化当中的场景一二的解决方案,如果Context当中的内容为"campaignTransfer"的话,即为通过强制令转移Leader来解决节点无法加入到集群当中的问题。
1
2
| // campaignTransfer represents the type of leader transfer
campaignTransfer CampaignType = "CampaignTransfer"
|
之后,对于MsgPreVote和对方不拒绝的MsgPreVoteResp,忽略即可,不需要进行任何操作。除此之外,对于其他高于自身的消息类型当中,MsgApp、MsgHeartBeat、MsgSnap,这三种信息只能由Leader发送,均代表当前存在一个明确的Leader,对其进行跟随。
而对于其他情况,比如当前节点为Leader,对一个follower发送了一条Heartbeat,但是收到了一个比自己Term要高的HeartbeatResp,则证明当前的集群当中存在某个未知的Leader,因此同样将自身转换为follower,但是Leader的id却未知。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| case m.Term > r.Term:
// 接收到一个更高的Term,但是当前checkQuorum校验通过,即在租期内,因此没必要对其进行投票,不处理
if m.Type == pb.MsgVote || m.Type == pb.MsgPreVote {
force := bytes.Equal(m.Context, []byte(campaignTransfer))
inLease := r.checkQuorum && r.lead != None && r.electionElapsed < r.electionTimeout
if !force && inLease {
// If a server receives a RequestVote request within the minimum election timeout
// of hearing from a current leader, it does not update its term or grant its vote
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] ignored %s from %x [logterm: %d, index: %d] at term %d: lease is not expired (remaining ticks: %d)",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term, r.electionTimeout-r.electionElapsed)
return nil
}
}
switch {
case m.Type == pb.MsgPreVote:
// Never change our term in response to a PreVote
case m.Type == pb.MsgPreVoteResp && !m.Reject:
// We send pre-vote requests with a term in our future. If the
// pre-vote is granted, we will increment our term when we get a
// quorum. If it is not, the term comes from the node that
// rejected our vote so we should become a follower at the new
// term.
default:
// 除此之外按照raft的正常逻辑进行处理,遇到更高Term的对其进行跟随
r.logger.Infof("%x [term: %d] received a %s message with higher term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
if m.Type == pb.MsgApp || m.Type == pb.MsgHeartbeat || m.Type == pb.MsgSnap {
// 这三种消息只能由leader发送,且发送者等term更高,因此收到消息后变为follower
r.becomeFollower(m.Term, m.From)
} else {
// 不知道leader是谁,但是收到了更高term的消息依旧需要转变为follower
r.becomeFollower(m.Term, None)
}
}
|
比当前节点Term更低的消息#
最后,如果消息的Term比当前Term小,因存在优化引入的额外问题,除了忽略消息外,还要做额外的处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| case m.Term < r.Term:
// 接收到了一个来自更小的Term的心跳信息或者AppendEntry,如果不进行处理,假设产生分区,
// 如果没开启preVote,被分区的节点的Term就会大于主分区,而由于checkQuorum,导致主分区的节点不会给
// 次分区的节点投票,次分区的无法成功选举,而次分区的Term大于主分区,主分区发送的会被起统统拒绝,因此就无法再
// 重新加入到集群当中
// 而对于开启preVote时,当一个节点进行preVote之后准备发起正式投票时被分区至分区2,脱离主分区1,其term会高于主分区
// 会发生和上述同样的情况,即该节点再也无法加入到集群当中
// 通过发送一个自身的Term让对方下台,就等于没采取checkQuorum 和Leader lease优化时的处理方法
if (r.checkQuorum || r.preVote) && (m.Type == pb.MsgHeartbeat || m.Type == pb.MsgApp) {
// We have received messages from a leader at a lower term. It is possible
// that these messages were simply delayed in the network, but this could
// also mean that this node has advanced its term number during a network
// partition, and it is now unable to either win an election or to rejoin
// the majority on the old term. If checkQuorum is false, this will be
// handled by incrementing term numbers in response to MsgVote with a
// higher term, but if checkQuorum is true we may not advance the term on
// MsgVote and must generate other messages to advance the term. The net
// result of these two features is to minimize the disruption caused by
// nodes that have been removed from the cluster's configuration: a
// removed node will send MsgVotes (or MsgPreVotes) which will be ignored,
// but it will not receive MsgApp or MsgHeartbeat, so it will not create
// disruptive term increases, by notifying leader of this node's activeness.
// The above comments also true for Pre-Vote
//
// When follower gets isolated, it soon starts an election ending
// up with a higher term than leader, although it won't receive enough
// votes to win the election. When it regains connectivity, this response
// with "pb.MsgAppResp" of higher term would force leader to step down.
// However, this disruption is inevitable to free this stuck node with
// fresh election. This can be prevented with Pre-Vote phase.
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp})
} else if m.Type == pb.MsgPreVote {
// Before Pre-Vote enable, there may have candidate with higher term,
// but less log. After update to Pre-Vote, the cluster may deadlock if
// we drop messages with a lower term.
//在更复杂的情况中,比如,在变更配置时,开启了原本没有开启的Pre-Vote机制。
// 此时可能会出现与上一条类似的情况,即可能因Term更高但是Log更旧的节点的存在导致整个集群的死锁,
// 所有节点都无法预投票成功
// 对于Term比当前节点Term低的预投票请求,无论是否开启了Check Quorum / Leader Lease或Pre-Vote,
// 都要通过一条Term为当前Term的消息,迫使其转为Follower并更新Term
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] rejected %s from %x [logterm: %d, index: %d] at term %d",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
r.send(pb.Message{To: m.From, Term: r.Term, Type: pb.MsgPreVoteResp, Reject: true})
} else {
// ignore other cases
r.logger.Infof("%x [term: %d] ignored a %s message with lower term from %x [term: %d]",
r.id, r.Term, m.Type, m.From, m.Term)
}
return nil
}
|
最终,终于轮到进行选举了,根据是否为preVote向其中传入不同的选举类型即可
1
2
3
4
5
6
7
| switch m.Type {
case pb.MsgHup:
if r.preVote {
r.hup(campaignPreElection)
} else {
r.hup(campaignElection)
}
|
在投票上进行安全性校验:
- 如果当前Term之前对该节点投过票,允许投票
- 如果当前Term未投过票,并且自身也没有Leader,允许投票
- 接收到一个Term高于自己的PreVote,允许投票
此外还需要校验自身的Log,防止Log覆盖。
否则,投出拒绝票。
1
2
3
4
5
6
7
8
9
10
11
| case pb.MsgVote, pb.MsgPreVote:
// We can vote if this is a repeat of a vote we've already cast...
canVote := r.Vote == m.From ||
// ...we haven't voted and we don't think there's a leader yet in this term...
(r.Vote == None && r.lead == None) ||
// ...or this is a PreVote for a future term...
(m.Type == pb.MsgPreVote && m.Term > r.Term)
// ...and we believe the candidate is up to date.
// raft当中通过日志Term进行的最基础的安全性校验
if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) {
// Note: it turns out that that learners must be allowed
|
1
2
3
| func (l *raftLog) isUpToDate(lasti, term uint64) bool {
return term > l.lastTerm() || (term == l.lastTerm() && lasti >= l.lastIndex())
}
|
角色相关step#
step#
当所有的预处理均处理完之后,如果还有后续工作,就交给stepxxx来完成,分别为stepLeader、stepFollower、stepCandidate
1
2
3
4
5
6
| type stepFunc func(r *raft, m pb.Message) error
type raft struct {
// ...
step stepFunc
// ...
}
|
1
2
3
4
5
| default:
err := r.step(r, m)
if err != nil {
return err
}
|
stepLeader#
stepLeader当中涉及到的逻辑较为复杂,包含了选举、日志复制、快照处理等多方面,这里先仅分析选举相关的内容。
首先如果Step传来的消息为MsgCheckQuorum类型,那么就执行Check Quorum操作,检查当前集群当中活跃的节点数量,如果活跃数量达不到Quorum的要求,当前的Leader就退位成为Follower。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| case pb.MsgCheckQuorum:
// The leader should always see itself as active. As a precaution, handle
// the case in which the leader isn't in the configuration any more (for
// example if it just removed itself).
//
// TODO(tbg): I added a TODO in removeNode, it doesn't seem that the
// leader steps down when removing itself. I might be missing something.
if pr := r.prs.Progress[r.id]; pr != nil {
pr.RecentActive = true
}
if !r.prs.QuorumActive() {
r.logger.Warningf("%x stepped down to follower since quorum is not active", r.id)
r.becomeFollower(r.Term, None)
}
// Mark everyone (but ourselves) as inactive in preparation for the next
// CheckQuorum.
r.prs.Visit(func(id uint64, pr *tracker.Progress) {
if id != r.id {
pr.RecentActive = false
}
})
return nil
|
stepCandidate#
在stepCandidate当中,如果接收到了Leader发送来的消息,如MsgApp MsgHeartbeat MsgSnap,那么就放弃选举,自动转换为follower,而如果接收到了MsgProp,propose消息只有Leader才能够处理,因此返回一个Err,拒绝处理。
stepCandidate当中的选举的相关逻辑主要为处理选举的结果,同样通过poll函数进行检查,但是此时已经有其他的节点通过票了,会记录在Tracker.progress当中,如果能够拿到足够多的选票,在根据当前选举的状态判断,如果是预选举,那么就开启正式选举,而如果是正式选举,那么就成为Leader,并且上线之后立刻广播一次AppendEntries。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| // stepCandidate is shared by StateCandidate and StatePreCandidate; the difference is
// whether they respond to MsgVoteResp or MsgPreVoteResp.
func stepCandidate(r *raft, m pb.Message) error {
// Only handle vote responses corresponding to our candidacy (while in
// StateCandidate, we may get stale MsgPreVoteResp messages in this term from
// our pre-candidate state).
var myVoteRespType pb.MessageType
if r.state == StatePreCandidate {
myVoteRespType = pb.MsgPreVoteResp
} else {
myVoteRespType = pb.MsgVoteResp
}
switch m.Type {
case pb.MsgProp:
r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term)
return ErrProposalDropped
case pb.MsgApp:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleAppendEntries(m)
case pb.MsgHeartbeat:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleHeartbeat(m)
case pb.MsgSnap:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleSnapshot(m)
case myVoteRespType:
gr, rj, res := r.poll(m.From, m.Type, !m.Reject)
r.logger.Infof("%x has received %d %s votes and %d vote rejections", r.id, gr, m.Type, rj)
switch res {
case quorum.VoteWon:
if r.state == StatePreCandidate {
r.campaign(campaignElection)
} else {
r.becomeLeader()
r.bcastAppend()
}
case quorum.VoteLost:
// pb.MsgPreVoteResp contains future term of pre-candidate
// m.Term > r.Term; reuse r.Term
r.becomeFollower(r.Term, None)
}
}
return nil
}
|
stepFollower#
follower当中和选举相关的内容不是很多,只有一条超时进行选举,其他的都是对Leader状态的跟随,即处理AppendEntries、Heartbeat、Snapshot。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgProp:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping proposal", r.id, r.Term)
return ErrProposalDropped
} else if r.disableProposalForwarding {
r.logger.Infof("%x not forwarding to leader %x at term %d; dropping proposal", r.id, r.lead, r.Term)
return ErrProposalDropped
}
m.To = r.lead
r.send(m)
case pb.MsgApp:
r.electionElapsed = 0
r.lead = m.From
r.handleAppendEntries(m)
case pb.MsgHeartbeat:
r.electionElapsed = 0
r.lead = m.From
r.handleHeartbeat(m)
case pb.MsgSnap:
r.electionElapsed = 0
r.lead = m.From
r.handleSnapshot(m)
case pb.MsgTransferLeader:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping leader transfer msg", r.id, r.Term)
return nil
}
m.To = r.lead
r.send(m)
case pb.MsgTimeoutNow:
r.logger.Infof("%x [term %d] received MsgTimeoutNow from %x and starts an election to get leadership.", r.id, r.Term, m.From)
// Leadership transfers never use pre-vote even if r.preVote is true; we
// know we are not recovering from a partition so there is no need for the
// extra round trip.
r.hup(campaignTransfer)
case pb.MsgReadIndex:
if r.lead == None {
r.logger.Infof("%x no leader at term %d; dropping index reading msg", r.id, r.Term)
return nil
}
m.To = r.lead
r.send(m)
case pb.MsgReadIndexResp:
if len(m.Entries) != 1 {
r.logger.Errorf("%x invalid format of MsgReadIndexResp from %x, entries count: %d", r.id, m.From, len(m.Entries))
return nil
}
r.readStates = append(r.readStates, ReadState{Index: m.Index, RequestCtx: m.Entries[0].Data})
}
return nil
}
|
状态切换#
当进行状态切换时, 均会调用一个reset函数,对自身的状态进行重置:
- 将自己的term设置为预期的Term
- 清除自身的Leader
- 重置定时器
- 清除选票
- 遍历tracker.Progress重置状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| func (r *raft) reset(term uint64) {
if r.Term != term {
r.Term = term
r.Vote = None
}
r.lead = None
r.electionElapsed = 0
r.heartbeatElapsed = 0
r.resetRandomizedElectionTimeout()
r.abortLeaderTransfer()
r.prs.ResetVotes()
r.prs.Visit(func(id uint64, pr *tracker.Progress) {
*pr = tracker.Progress{
Match: 0,
Next: r.raftLog.lastIndex() + 1,
Inflights: tracker.NewInflights(r.prs.MaxInflight),
IsLearner: pr.IsLearner,
}
if id == r.id {
pr.Match = r.raftLog.lastIndex()
}
})
r.pendingConfIndex = 0
r.uncommittedSize = 0
r.readOnly = newReadOnly(r.readOnly.option)
}
|
follower#
1
2
3
4
5
6
7
8
| func (r *raft) becomeFollower(term uint64, lead uint64) {
r.step = stepFollower
r.reset(term)
r.tick = r.tickElection
r.lead = lead
r.state = StateFollower
r.logger.Infof("%x became follower at term %d", r.id, r.Term)
}
|
| 字段 | 作用 |
|---|
| step | 角色对应的step,在上面已经分析过 |
| tick | 角色对应的tick函数,对于follower为tickElection,用于进行超时选举 |
| lead | 当前的Leader |
| state | 角色状态 |
candidate#
1
2
3
4
5
6
7
8
9
10
11
12
| func (r *raft) becomeCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> candidate]")
}
r.step = stepCandidate
r.reset(r.Term + 1)
r.tick = r.tickElection
r.Vote = r.id
r.state = StateCandidate
r.logger.Infof("%x became candidate at term %d", r.id, r.Term)
}
|
| 字段 | 作用 |
|---|
| step | 角色对应的step,在上面已经分析过 |
| tick | 角色对应的tick函数,对于candidate为tickElection,用于进行超时选举 |
| Vote | 当前Term下投出的票,candidate会为自己投票 |
| state | 角色状态 |
PreCandidate#
对于PreCVandidate,严格意义上其并非状态切换,即本质上还是为follower,只不过为了对外发起PreVote设置了一个单独的StatePreCandidate的状态,因此在becomePreCandidate当中不会调用reset进行状态重置,只有当其确认会进行正式投票时,才会转换为Candidate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| func (r *raft) becomePreCandidate() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateLeader {
panic("invalid transition [leader -> pre-candidate]")
}
// Becoming a pre-candidate changes our step functions and state,
// but doesn't change anything else. In particular it does not increase
// r.Term or change r.Vote.
r.step = stepCandidate
r.prs.ResetVotes()
r.tick = r.tickElection
r.lead = None
r.state = StatePreCandidate
r.logger.Infof("%x became pre-candidate at term %d", r.id, r.Term)
}
|
| 字段 | 作用 |
|---|
| step | 角色对应的step,和Candidate公用相同的逻辑 |
| tick | 角色对应的tick函数,对于candidate为tickElection,用于进行超时选举 |
| lead | 进行预投票时即为认定当前集群当中无Leader,因此设置为None |
| Vote | 当前Term下投出的票,candidate会为自己投票 |
| state | 角色状态 |
Leader#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| func (r *raft) becomeLeader() {
// TODO(xiangli) remove the panic when the raft implementation is stable
if r.state == StateFollower {
panic("invalid transition [follower -> leader]")
}
r.step = stepLeader
r.reset(r.Term)
r.tick = r.tickHeartbeat
r.lead = r.id
r.state = StateLeader
// Followers enter replicate mode when they've been successfully probed
// (perhaps after having received a snapshot as a result). The leader is
// trivially in this state. Note that r.reset() has initialized this
// progress with the last index already.
r.prs.Progress[r.id].BecomeReplicate()
// Conservatively set the pendingConfIndex to the last index in the
// log. There may or may not be a pending config change, but it's
// safe to delay any future proposals until we commit all our
// pending log entries, and scanning the entire tail of the log
// could be expensive.
r.pendingConfIndex = r.raftLog.lastIndex()
emptyEnt := pb.Entry{Data: nil}
if !r.appendEntry(emptyEnt) {
// This won't happen because we just called reset() above.
r.logger.Panic("empty entry was dropped")
}
// As a special case, don't count the initial empty entry towards the
// uncommitted log quota. This is because we want to preserve the
// behavior of allowing one entry larger than quota if the current
// usage is zero.
r.reduceUncommittedSize([]pb.Entry{emptyEnt})
r.logger.Infof("%x became leader at term %d", r.id, r.Term)
}
|
| 字段 | 作用 |
|---|
| step | 角色对应的step,stepLeader |
| tick | 角色对应的tick函数,对于Leader为tickHeartbeat,发送心跳信息 |
| lead | lead设置为自身 |
| state | 角色状态 |