Raft日志#
日志存储#
Raft日志在存储上分为两部分,一部分为新写入或者新生成的日志,暂时存储于内存当中,还未来得及进行稳定存储。而另一部分则是目前已经进行稳定存储的。
在Log接口中可以看到,分为对应于Storage和unstable
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| type raftLog struct {
// storage contains all stable entries since the last snapshot.
storage Storage
// unstable contains all unstable entries and snapshot.
// they will be saved into storage.
unstable unstable
// committed is the highest log position that is known to be in
// stable storage on a quorum of nodes.
committed uint64
// applied is the highest log position that the application has
// been instructed to apply to its state machine.
// Invariant: applied <= committed
applied uint64
logger Logger
// maxNextEntsSize is the maximum number aggregate byte size of the messages
// returned from calls to nextEnts.
maxNextEntsSize uint64
}
|
由于etcd/raft的底层只负责raft逻辑处理,而存储与通信交给了上层,因此在这个过程当中产生的日志和快照均通过unstable进行暂时性的存储,之后通过Ready()函数,以批处理的方式,一次性的将一段时间内的msg、log、hardState、Snapshot全部返回给上层,进行节点间的通信与存储。可以在raft-example当中看到相关的逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| for {
select {
case <-ticker.C:
rc.node.Tick()
// store raft entries to wal, then publish over commit channel
case rd := <-rc.node.Ready():
rc.wal.Save(rd.HardState, rd.Entries)
if !raft.IsEmptySnap(rd.Snapshot) {
rc.saveSnap(rd.Snapshot)
rc.raftStorage.ApplySnapshot(rd.Snapshot)
rc.publishSnapshot(rd.Snapshot)
}
rc.raftStorage.Append(rd.Entries)
rc.transport.Send(rd.Messages)
applyDoneC, ok := rc.publishEntries(rc.entriesToApply(rd.CommittedEntries))
if !ok {
rc.stop()
return
}
rc.maybeTriggerSnapshot(applyDoneC)
rc.node.Advance()
case err := <-rc.transport.ErrorC:
rc.writeError(err)
return
case <-rc.stopc:
rc.stop()
return
}
}
|
unstable#
unstable的结构体定义如下:
1
2
3
4
5
6
7
8
9
| type unstable struct {
// the incoming unstable snapshot, if any.
snapshot *pb.Snapshot
// all entries that have not yet been written to storage.
entries []pb.Entry
offset uint64
logger Logger
}
|
其中,offset用于将unstable当中的下标转换为全局下标
部分相关函数:
| 函数 | 功能 |
|---|
| maybeFirstIndex | 求出日志当中第一个Entry的Index |
| maybeLastIndex | 求出日志当中最后一个Entry的Index |
| maybeTerm | 求出给定Index对应的Term |
| stableTo | 已经通过Ready将部分日志持久化,对状态进行更新,通过Advance调用 |
| stableSnap | 快照持久化 |
| shrinkEntriesArray | 根据底层切片的size与cap的大小情况,适当缩小切片,释放内存 |
| truncateAppend | 向原有的日志当中添加新的日志,产生冲突的则将旧的覆盖 |
| slice | 检查范围后返回一段的日志 |
- 其中,maybeFirstIndex maybeLastIndex maybeTerm都是根据Snapshot进行判断, 如果当前存在不稳定的Snapshot,就可以根据Snapshot当中的元数据推断出相对整个raftlog的数据,如果不存在Snapshot则无法推断从而返回一个false
- stableTo、stableSnap反映了整个存储模块的交互逻辑,当部分日志通过Ready()交给上层进行持久化存储之后,就可以调用Advance来推进整个流程,之后Advance会调用到stableTo和stableSnap将已经持久化的日志从内存当中释放(这里的持久化是指交给Storage进行存储,Storage的具体存储逻辑之后进行分析)
Storage#
Storage定义为接口的形式,而官方给出实现为MemoryStorage,将全部的数据全部存放于内存当中,但是通过WAL的形式保证能够稳定存储,结构体定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // MemoryStorage implements the Storage interface backed by an
// in-memory array.
type MemoryStorage struct {
// Protects access to all fields. Most methods of MemoryStorage are
// run on the raft goroutine, but Append() is run on an application
// goroutine.
sync.Mutex
// hardState即为Raft当中需要持久化保存的字段,Term、Vote、Commit
// 对应的有SoftState,即无需持久化保存,可以通过节点之间相互通信恢复
hardState pb.HardState
snapshot pb.Snapshot
// ents[i] has raft log position i+snapshot.Metadata.Index
ents []pb.Entry
}
|
相关的WAL逻辑可以在上层的raft server(raft example)当中实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| case rd := <-rc.node.Ready():
rc.wal.Save(rd.HardState, rd.Entries)
if !raft.IsEmptySnap(rd.Snapshot) {
rc.saveSnap(rd.Snapshot)
rc.raftStorage.ApplySnapshot(rd.Snapshot)
rc.publishSnapshot(rd.Snapshot)
}
rc.raftStorage.Append(rd.Entries)
rc.transport.Send(rd.Messages)
applyDoneC, ok := rc.publishEntries(rc.entriesToApply(rd.CommittedEntries))
if !ok {
rc.stop()
return
}
rc.maybeTriggerSnapshot(applyDoneC)
rc.node.Advance()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| func (w *WAL) Save(st raftpb.HardState, ents []raftpb.Entry) error {
w.mu.Lock()
defer w.mu.Unlock()
// short cut, do not call sync
if raft.IsEmptyHardState(st) && len(ents) == 0 {
return nil
}
mustSync := raft.MustSync(st, w.state, len(ents))
// TODO(xiangli): no more reference operator
for i := range ents {
if err := w.saveEntry(&ents[i]); err != nil {
return err
}
}
if err := w.saveState(&st); err != nil {
return err
}
curOff, err := w.tail().Seek(0, io.SeekCurrent)
if err != nil {
return err
}
if curOff < SegmentSizeBytes {
if mustSync {
// gofail: var walBeforeSync struct{}
err = w.sync()
// gofail: var walAfterSync struct{}
return err
}
return nil
}
return w.cut()
}
|
MemoryStorage中的[]Entry采用了dummy head的实现方式,当无快照时,第一个存储一个Index、Term均为0的Entry,而当有快照时,第一个日志存储lastInclduedIndex和lastIncludedTerm。
除此之外,剩余的逻辑都比较简单,大多都是做一些对齐、截断和越界的相关处理
raftLog#
raftLog的结构体定义如下,其中封装了Storage和unstable:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| type raftLog struct {
// storage contains all stable entries since the last snapshot.
storage Storage
// unstable contains all unstable entries and snapshot.
// they will be saved into storage.
unstable unstable
// committed is the highest log position that is known to be in
// stable storage on a quorum of nodes.
committed uint64
// applied is the highest log position that the application has
// been instructed to apply to its state machine.
// Invariant: applied <= committed
applied uint64
logger Logger
// maxNextEntsSize is the maximum number aggregate byte size of the messages
// returned from calls to nextEnts.
maxNextEntsSize uint64
}
|
相关函数
| 函数 | 功能 |
|---|
| maybeAppend | 匹配Term并解决冲突之后将新的日志追加到unstable当中 |
| findConflict | 根据给定的[]Entry找到冲突的位置 |
| findConflictByTerm | 根据给定的Term找到冲突的位置,用于进行快速回退 |
| nextEnts | [committed + 1,applied]即形成了共识但是还未交给上层去执行的,将这些进行返回 |
| hasPendingSnapshot | 即unstable、新产生的Snapshot |
| commitTo | commit之后更新状态 |
| appliedTo | apply之后更新状态 |
| isUpToDate | 检查Term与Index,在Leader选举时进行安全性检查 |
| matchTerm\term | 对于不冲突且饱含、不冲突但不包含、冲突且饱含的三种形式进行区分 |
term冲突校验
主要通过一下三个函数进行实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| func (l *raftLog) findConflict(ents []pb.Entry) uint64 {
for _, ne := range ents {
if !l.matchTerm(ne.Index, ne.Term) {
if ne.Index <= l.lastIndex() {
l.logger.Infof("found conflict at index %d [existing term: %d, conflicting term: %d]",
ne.Index, l.zeroTermOnErrCompacted(l.term(ne.Index)), ne.Term)
}
// 如果不存在冲突,但是存在新的内容,无需进行覆盖,将新的内容追加到原本的日志之后
// 新的内容在term()当中会因为超范围返回0,因此matchTerm会返回false,但是本质上不存在冲突
// 如果存在冲突,则返回冲突的第一条日志,之后进行覆盖。
return ne.Index
}
}
// 新旧日志不存在冲突,并且旧日志当中包含了所有给定的日志,无需进行添加,返回0
return 0
}
|
快速回退
快速回退分为两部分,一部分为在follower端进行冲突的查询,找到产生冲突的位置之后返回给Leader,另一部分则是Leader根据follower的hint进行重新发送,这里只看一下日志层面的实现findConflictByTerm,follower和Leader均会调用该函数,而整个流程留到之后再进行分析
- 如果发送来的Index,超出了follower的范围,无法根据Term进行搜索,warning
- follower\leader包含Index,之后进行term的匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| func (l *raftLog) findConflictByTerm(index uint64, term uint64) uint64 {
if li := l.lastIndex(); index > li {
// follower的进度过旧,完全不包含Leader发送而来的日志
// NB: such calls should not exist, but since there is a straightfoward
// way to recover, do it.
//
// It is tempting to also check something about the first index, but
// there is odd behavior with peers that have no log, in which case
// lastIndex will return zero and firstIndex will return one, which
// leads to calls with an index of zero into this method.
l.logger.Warningf("index(%d) is out of range [0, lastIndex(%d)] in findConflictByTerm",
index, li)
return index
}
for {
logTerm, err := l.term(index)
if logTerm <= term || err != nil {
break
}
index--
}
return index
}
|
日志追加
通过maybeAppend和append两个函数进行实现,append不做Term冲突校验,只是简单的检查commit情况,并将日志追加到unstable当中,作为底层被maybeAppend调用。
maybeAppend则会根据传入的index与Term进行匹配,并通过findConflict找到冲突的位置:
- 如果没有冲突也不存在新日志,则不进行任何的处理
- 如果在已经commit的日志范围内产生冲突,出现异常,Panic
- 而如果是一般情况的冲突,即在未commit的地方产生冲突,或者只是传入的Entry当中有需要追加的部分,偏移之后调用append进行追加
maybeAppend由follower的handAppendEntries进行调用,其中会携带目前Leader的commit进度,follower对其进行更新。follower最新的commit为min(committed,lastnewi)
为什么取min?
- 当前的follower为一个较为落后的follower,Leader已经和其他的follower形成了共识,得到了一个committed的进度,但是这个进度还未发送给该follower,此时leader给follower复制日志时,如果复制的日志条目超过了单个消息的上限,则可能出现leader传给follower的committed值大于该follower复制完这条消息中的日志后的最大index,此时,该follower的新committed值为lastnewi。
- follower能够跟上leader,leader传给follower的日志中有未确认被法定数量节点稳定存储的日志,此时传入的committed比lastnewi小,该follower的新committed值为传入的committed值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| func (l *raftLog) maybeAppend(index, logTerm, committed uint64, ents ...pb.Entry) (lastnewi uint64, ok bool) {
if l.matchTerm(index, logTerm) {
lastnewi = index + uint64(len(ents))
ci := l.findConflict(ents)
switch {
case ci == 0:
// 没有冲突也没有新日志,不处理
case ci <= l.committed:
l.logger.Panicf("entry %d conflict with committed entry [committed(%d)]", ci, l.committed)
default:
offset := index + 1
// 从产生冲突的新日志处开始进行覆盖
l.append(ents[ci-offset:]...)
}
//为什么取min?
// 1. leader给follower复制日志时,如果复制的日志条目超过了单个消息的上限,
//则可能出现leader传给follower的committed值大于该follower复制完这条消息中的日志后的最大index
// 此时,该follower的新committed值为lastnewi。
// 2. follower能够跟上leader,leader传给follower的日志中有未确认被法定数量节点稳定存储的日志,
//此时传入的committed比lastnewi小,该follower的新committed值为传入的committed值。
l.commitTo(min(committed, lastnewi))
return lastnewi, true
}
return 0, false
}
|
进度跟踪#
Raft原文当中使用nextIndex[] matchIndex[]进行追踪follower的日志进度。
1
2
3
4
5
6
7
8
9
10
11
12
| if args.Term == rf.currentTerm {
if reply.Success {
// 发送成功则为发送的所有日志条目全部匹配,match直接加上len(Entries)
// next 永远等于match + 1
match := args.PrevLogIndex + len(args.LogEntries)
next := match + 1
rf.commitIndex = rf.lastIncludedIndex
rf.matchIndex[server] = match
rf.nextIndex[server] = next
Debug(dLog2, "S%d update server is %d nextIndex:%d lastIncludedIndex is:%d preLogIndex is %d lenLog is %d", rf.me, server, next, rf.lastIncludedIndex, args.PrevLogIndex, len(args.LogEntries))
}
|
在etcd/raft当中,为了实现节藕,单独封装了一个Progress结构体用于记录在Leader的视角下,follower处于何种进度。最终在Leader处维护一个 []progress数组来表示当前所有的follower的进度,progress结构体的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| type Progress struct {
Match, Next uint64
// State defines how the leader should interact with the follower.
//
// When in StateProbe, leader sends at most one replication message
// per heartbeat interval. It also probes actual progress of the follower.
//
// When in StateReplicate, leader optimistically increases next
// to the latest entry sent after sending replication message. This is
// an optimized state for fast replicating log entries to the follower.
//
// When in StateSnapshot, leader should have sent out snapshot
// before and stops sending any replication message.
State StateType
// PendingSnapshot is used in StateSnapshot.
// If there is a pending snapshot, the pendingSnapshot will be set to the
// index of the snapshot. If pendingSnapshot is set, the replication process of
// this Progress will be paused. raft will not resend snapshot until the pending one
// is reported to be failed.
PendingSnapshot uint64
// RecentActive is true if the progress is recently active. Receiving any messages
// from the corresponding follower indicates the progress is active.
// RecentActive can be reset to false after an election timeout.
//
// TODO(tbg): the leader should always have this set to true.
RecentActive bool
// ProbeSent is used while this follower is in StateProbe. When ProbeSent is
// true, raft should pause sending replication message to this peer until
// ProbeSent is reset. See ProbeAcked() and IsPaused().
ProbeSent bool
// Inflights is a sliding window for the inflight messages.
// Each inflight message contains one or more log entries.
// The max number of entries per message is defined in raft config as MaxSizePerMsg.
// Thus inflight effectively limits both the number of inflight messages
// and the bandwidth each Progress can use.
// When inflights is Full, no more message should be sent.
// When a leader sends out a message, the index of the last
// entry should be added to inflights. The index MUST be added
// into inflights in order.
// When a leader receives a reply, the previous inflights should
// be freed by calling inflights.FreeLE with the index of the last
// received entry.
Inflights *Inflights
// IsLearner is true if this progress is tracked for a learner.
IsLearner bool
}
|
| 字段 | 作用 |
|---|
| Match、Next | 对应原本Raft论文当中的MatchIndex[]与NextIndex[],表示follower当前的进度 |
| State | 当前follower的状态,决定Leader以何种方式与follower进行通讯 |
| PendingSnapshot | 对应在raftlog当中的PendingSnapshot,在StateSnapshot阶段下使用 |
| RecentActive | Check Quorum时使用的字段,表示当前的follower是否处于活跃状态 |
| ProbeSent | StateProbe状态下用于阻塞发送 |
| learner | 表示当前节点是否处于learner状态 |
主要来看一下State与PendingSnapshot,对于State,在etcd的注视当中描述的也非常明确:
- Probe所表示的为Leader,对于当前follower的最后一条日志的Index并不知晓,可能是follower宕机许久之后重启。此时在Leader方面,将其视为Probe状态,在这种状态下,leader每次心跳期间仅为follower发送一条
MsgApp消息,之后边立即陷入阻塞状态,等待follower的回应之后才会重新从阻塞当中恢复 - StateReplicate表示当前的follower能够正确的跟随住Leader的进度,此时可以按照流水线的形式不断的给Follower发送消息,可以采取比较激进的优化方式直接对Leader的信息进行更新
- StateSnapshot表示当前的follower已经落后Leader过多,所需的日志已经被快照化,此时所需要的就是发送快照。
状态转换#
初始状态
接下来讨论一下Progress当中的State如何进行状态转换
当一个节点发生状态转换时,(这里的状态转换指的是Leader、Follower、Candidate)会调用Reset函数,在其中遍历所有的节点,对其进行初始化,而由于StateType定义为uint64类型的字段,因此初始化为0,即StateProbe,这样的做法也说得通,当一个Leader刚通过选举上线时,他对其他节点的状态是不清楚的,先将其他的所有的follower的状态设置为StateProbe因此在发送时先探测follower的LastIndex。而之后会在``becomeLeader 当中将自身的状态设置为StateReplicate
1
2
3
4
5
6
7
8
9
10
11
| r.prs.Visit(func(id uint64, pr *tracker.Progress) {
*pr = tracker.Progress{
Match: 0,
Next: r.raftLog.lastIndex() + 1,
Inflights: tracker.NewInflights(r.prs.MaxInflight),
IsLearner: pr.IsLearner,
}
if id == r.id {
pr.Match = r.raftLog.lastIndex()
}
})
|
1
2
3
4
5
| func(r *raft) becomeLeader() {
// ...
r.prs.Progress[r.id].BecomeReplicate()
// ...
}
|
StateProbe ->StateReplicate
而当follower能够正确的跟随Leader的进度时,就可以从SateProbe转向StateReplicate进行快速的跟随复制,因此在Leader接收到MsgAppResp时,并且当中的reject为false时,并且该条消息为一个非过失的消息时,调用becomeReplicate进行状态转换:
1
2
3
4
5
6
7
8
9
10
11
12
| if (m.reject) {
// ...
} else {
if pr.MaybeUpdate(m.Index) {
switch {
case pr.State == tracker.StateProbe:
// 在Probe状态下,follower成功接收到Leader发送的RPC并且成功给予回应
// 此时Leader可以确认follower可以跟上进度,因此取消阻塞,并且转变为流水线
// 模式优化发送速度
pr.BecomeReplicate()
}
}
|
其中MaybeUpdate用于判断当前的消息是否为一条过时的消息,并更新状态。即已经返回的Index已经是Match之后了的,对于过期的消息,对其进行忽略
1
2
3
4
5
6
7
8
9
10
| func (pr *Progress) MaybeUpdate(n uint64) bool {
var updated bool
if pr.Match < n {
pr.Match = n
updated = true
pr.ProbeAcked()
}
pr.Next = max(pr.Next, n+1)
return updated
}
|
StateReplicate -> StateProbe
即原本Follower能够紧随Leader的进度,之后如果存在网络故障或者消息在网络中乱序发送,Follower无法与Leader的进度进行对齐,会返回Leader一个reject和rejectHint,用于进行fast backup,此时就代表Follower已经无法紧随Leader的日志进度了,需要从Replicate向Probe进行转换:
1
2
3
4
5
6
7
8
9
10
11
| if (m.reject) {
// 如果回退失败则说明为一条过期的日志,不做处理
// 如果回退成功,并且对方原本为StateReplicate,转换为Probe进行探测,并且再向其发送一次MsgApp
if pr.MaybeDecrTo(m.Index, nextProbeIdx) {
r.logger.Debugf("%x decreased progress of %x to [%s]", r.id, m.From, pr)
if pr.State == tracker.StateReplicate {
pr.BecomeProbe()
}
r.sendAppend(m.From)
}
}
|
除此之外, 还在处理MsgUnreachable当中从StateReplicate转换为Probe,暂时没太弄明白调用的时机,不过个人猜测是当follower长时间未响应Leader的调用,就会添加一条MsgUnreachable的消息,来表示Follower长期收不到Leader的消息,转换到Probe状态
StateProbe -> StateSnapshot & StateReplicate -> StateSnapshot
进入到StateSnapshot当中的情况非常简单,不区分状态,只要在Leader要发送AppendEntries时发现自己应当发送给对方的日志已经被快照化,此时就转变为StateSnapshot 开始发送快照,这个情况在StateProbe与StateReplicate的状态下均有可能发生,尤其是StateProbe 状态下,更容易出现Leader与Follower之间的差距过大,从而要发送给Follower的日志被快照化的情况。
StateSnapshot -> StateReplicate
在StateSnapshot的状态下,如果如果需要发送的Snapshot在Follower的进度已经匹配上,此时就可以转换为StateReplicate进行快速发送
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| if pr.MaybeUpdate(m.Index) {
switch {
case pr.State == tracker.StateProbe:
// 在Probe状态下,follower成功接收到Leader发送的RPC并且成功给予回应
// 此时Leader可以确认follower可以跟上进度,因此取消阻塞,并且转变为流水线
// 模式优化发送速度
pr.BecomeReplicate()
case pr.State == tracker.StateSnapshot && pr.Match >= pr.PendingSnapshot:
// TODO(tbg): we should also enter this branch if a snapshot is
// received that is below pr.PendingSnapshot but which makes it
// possible to use the log again.
r.logger.Debugf("%x recovered from needing snapshot, resumed sending replication messages to %x [%s]", r.id, m.From, pr)
// Transition back to replicating state via probing state
// (which takes the snapshot into account). If we didn't
// move to replicating state, that would only happen with
// the next round of appends (but there may not be a next
// round for a while, exposing an inconsistent RaftStatus).
pr.BecomeProbe()
pr.BecomeReplicate()
|
StateSnapshot -> StateProbe
在Leader处理SnapshotStatus消息时,如果当前的状态为StateSnapshot,则会转换为StateProbe,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| case pb.MsgSnapStatus:
if pr.State != tracker.StateSnapshot {
return nil
}
// TODO(tbg): this code is very similar to the snapshot handling in
// MsgAppResp above. In fact, the code there is more correct than the
// code here and should likely be updated to match (or even better, the
// logic pulled into a newly created Progress state machine handler).
if !m.Reject {
pr.BecomeProbe()
r.logger.Debugf("%x snapshot succeeded, resumed sending replication messages to %x [%s]", r.id, m.From, pr)
} else {
// NB: the order here matters or we'll be probing erroneously from
// the snapshot index, but the snapshot never applied.
pr.PendingSnapshot = 0
pr.BecomeProbe()
r.logger.Debugf("%x snapshot failed, resumed sending replication messages to %x [%s]", r.id, m.From, pr)
}
|
而该消息是由Node当中的ReportSnapshot方法进行封装的,不过该方法在raft-example当中并没有调用,真正的调用位于etcd/server当中,用法为:leader节点的使用者还需要主动调用Node的ReportSnapshot方法告知leader节点快照的应用状态,leader会将该follower的状态转移到StateProbe状态,暂时不进行展开
以上就是涉及到的所有的状态切换问题,可以总结如下:
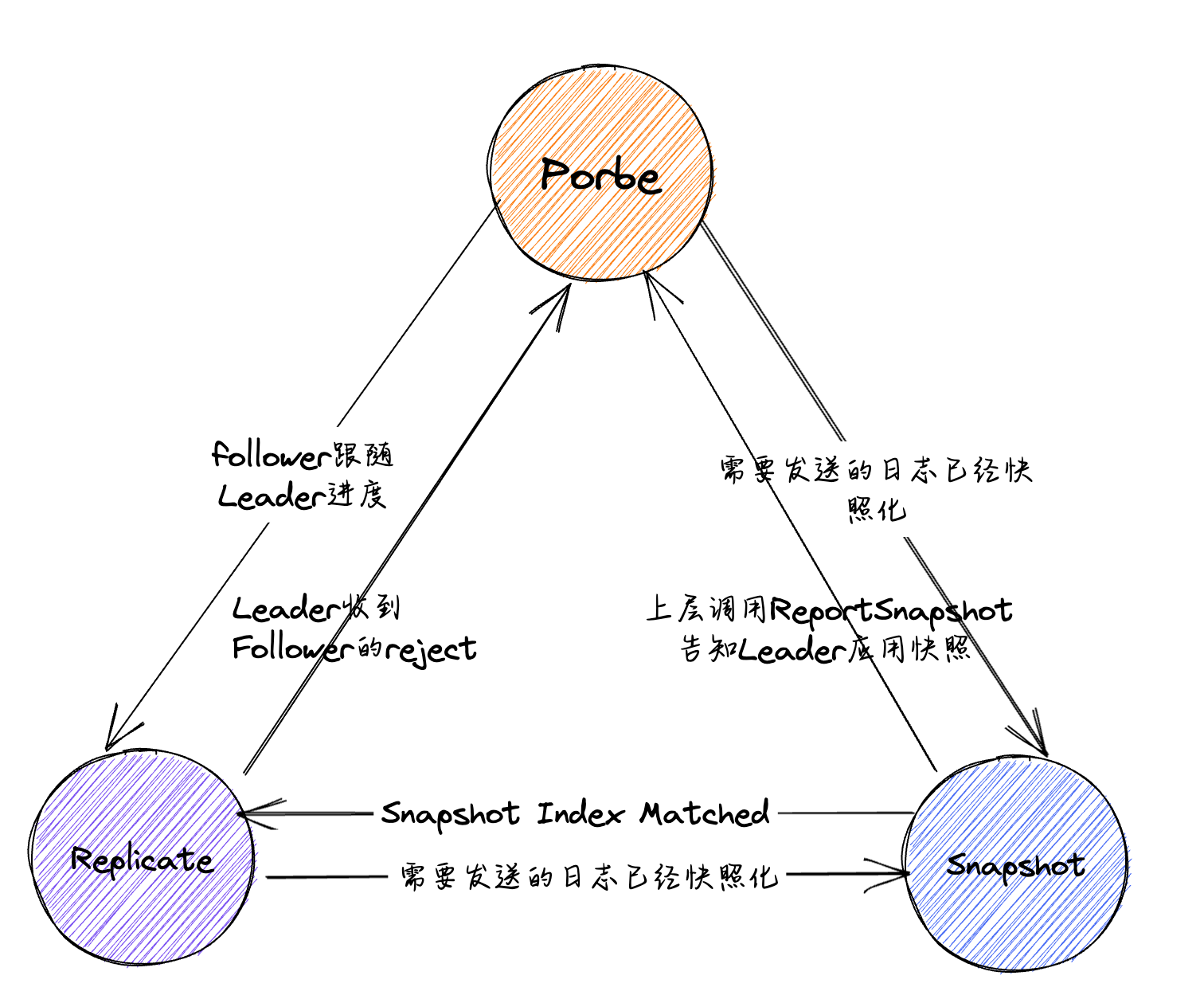 最后再列一下各个状态转移的函数:
最后再列一下各个状态转移的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| // BecomeProbe transitions into StateProbe. Next is reset to Match+1 or,
// optionally and if larger, the index of the pending snapshot.
func (pr *Progress) BecomeProbe() {
// If the original state is StateSnapshot, progress knows that
// the pending snapshot has been sent to this peer successfully, then
// probes from pendingSnapshot + 1.
if pr.State == StateSnapshot {
pendingSnapshot := pr.PendingSnapshot
pr.ResetState(StateProbe)
pr.Next = max(pr.Match+1, pendingSnapshot+1)
} else {
pr.ResetState(StateProbe)
pr.Next = pr.Match + 1
}
}
// BecomeReplicate transitions into StateReplicate, resetting Next to Match+1.
func (pr *Progress) BecomeReplicate() {
pr.ResetState(StateReplicate)
pr.Next = pr.Match + 1
}
// BecomeSnapshot moves the Progress to StateSnapshot with the specified pending
// snapshot index.
func (pr *Progress) BecomeSnapshot(snapshoti uint64) {
pr.ResetState(StateSnapshot)
pr.PendingSnapshot = snapshoti
}
|
Progress函数#
现在回到主线继续分析Progress的相关函数:
IsPaused:
对于三种状态,均存在不同的阻塞条件:
- StateProbe下,发送完一条日志之后手动设置
Probe = true,之后如果检测到true之后就会在IsPaused当中阻塞 - StateReplicate下,如果当前的滑动窗口,或者说消息队列已满的话,则阻塞
- StateSnapshot下,对于相同的快照,只应向对方发送一次,而对方如果收到之后就会脱离StateSnapshot(调用Node.ReportSnapshot),因此在StateSanpshot下应当无条件阻塞
1
2
3
4
5
6
7
8
9
10
11
12
| func (pr *Progress) IsPaused() bool {
switch pr.State {
case StateProbe:
return pr.ProbeSent
case StateReplicate:
return pr.Inflights.Full()
case StateSnapshot:
return true
default:
panic("unexpected state")
}
}
|
ProbeAcked:
StateProbe状态下确认回应,脱离阻塞
1
2
3
4
5
6
| // ProbeAcked is called when this peer has accepted an append. It resets
// ProbeSent to signal that additional append messages should be sent without
// further delay.
func (pr *Progress) ProbeAcked() {
pr.ProbeSent = false
}
|
MaybeUpdate:
在收到AppMsgResp之后调用,对日志Match的进度进行更新,并且调用ProbeAcked表示接收到响应解除阻塞。此外,在AppendEntries当中也会进行调用,对Leader自身对match进行更新
1
2
3
4
5
6
7
8
9
10
11
12
13
| // MaybeUpdate is called when an MsgAppResp arrives from the follower, with the
// index acked by it. The method returns false if the given n index comes from
// an outdated message. Otherwise it updates the progress and returns true.
func (pr *Progress) MaybeUpdate(n uint64) bool {
var updated bool
if pr.Match < n {
pr.Match = n
updated = true
pr.ProbeAcked()
}
pr.Next = max(pr.Next, n+1)
return updated
}
|
MaybeDecrTo:
在收到Follower发来的MsgAppResp之后,如果当中的reject为true,那么就根据返回的rejectHint进行快速回退
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| // MaybeDecrTo adjusts the Progress to the receipt of a MsgApp rejection. The
// arguments are the index of the append message rejected by the follower, and
// the hint that we want to decrease to.
//
// Rejections can happen spuriously as messages are sent out of order or
// duplicated. In such cases, the rejection pertains to an index that the
// Progress already knows were previously acknowledged, and false is returned
// without changing the Progress.
//
// If the rejection is genuine, Next is lowered sensibly, and the Progress is
// cleared for sending log entries.
func (pr *Progress) MaybeDecrTo(rejected, matchHint uint64) bool {
if pr.State == StateReplicate {
// The rejection must be stale if the progress has matched and "rejected"
// is smaller than "match".
if rejected <= pr.Match {
return false
}
// Directly decrease next to match + 1.
//
// TODO(tbg): why not use matchHint if it's larger?
pr.Next = pr.Match + 1
return true
}
// 探测模式一个心跳周期只能发送一次Entry,如果pr.Next - 1 != rejected则证明发送的时候
// 出现错误,则证明其不是这个心跳周期发送出去的信息
// The rejection must be stale if "rejected" does not match next - 1. This
// is because non-replicating followers are probed one entry at a time.
if pr.Next-1 != rejected {
return false
}
pr.Next = max(min(rejected, matchHint+1), 1)
pr.ProbeSent = false
return true
}
|
Tracker#
在Progress结构体之上,还封装了一个PorgressTracker,定义在tracker.go当中,封装了一些对于ProgressMap的集体操作,记录当前所有节点的状态与进度,和当前集群正在使用的配置信息。并且关于投票的相关信息也在这其中进行更新与记录,其中的操作并不复杂,暂时不做展开
1
2
3
4
5
6
7
8
9
10
11
12
| // ProgressTracker tracks the currently active configuration and the information
// known about the nodes and learners in it. In particular, it tracks the match
// index for each peer which in turn allows reasoning about the committed index.
type ProgressTracker struct {
Config
Progress ProgressMap
Votes map[uint64]bool
MaxInflight int
}
|
ectd/raft日志复制#
节点身份确认#
在一个集群启动之后,首先会通过becomeFollower全部初始化为follower,之后超时通过becomeCandidate开始选举,最后becomeLeader当选。在这个三个函数当中均使用reset对自身状态进行重置,之后Leader再将自身的设置为StateReplicate,但是这个设置并不是很重要,Leader主要根据Follower的State去进行相关的逻辑操作,这里更像是让其在逻辑上通顺,而没有什么实质性作用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| func (r *raft) reset(term uint64) {
// ...
r.prs.ResetVotes()
r.prs.Visit(func(id uint64, pr *tracker.Progress) {
*pr = tracker.Progress{
Match: 0,
Next: r.raftLog.lastIndex() + 1,
Inflights: tracker.NewInflights(r.prs.MaxInflight),
IsLearner: pr.IsLearner,
}
if id == r.id {
pr.Match = r.raftLog.lastIndex()
}
})
}
func (r *raft) becomeLeader() {
// ...
r.prs.Progress[r.id].BecomeReplicate()
// ...
}
|
之后所有的逻辑依旧像选举那样都在Step当中处理,首先Step进行通用处理之后再调用对应Stepxxx,在这个过程当中触发了日志复制的各种操作,不过在这个过程当中由于对于日志的操作在各个角色稻种不尽相同,因此Step当中没有涉及到日志相关的操作,直接看stepxxx,这里如果分step进行讨论难免会有些割裂,因此不如从某个Step入手,去分析发送和接收的整个过程。
心跳相关消息处理#
通过Leader的tickHeartbeat触发调用,处理的逻辑也比较的简单,只需要生成一条MsgHeartbeat广播给所有的follower,当中携带了一条commited字段,并且取了min(pr.match,leader.committed),在Raft论文或者对应的实现MIT6.824当中,Heartbeat只要求了令follower去重置超时时间,跟随Leader。
而在ectd/raft当中,可以顺带更新follower的committed进度,取min也是为了防止follower的进度落后于leader,还未获取到leader最新的日志,如果发送的为match,则代表将follower当前所有的日志全部设置为committed。并且follower并不需要维护progress,因此只需要更新日志当中的committed进度即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| func (r *raft) bcastHeartbeat() {
lastCtx := r.readOnly.lastPendingRequestCtx()
if len(lastCtx) == 0 {
r.bcastHeartbeatWithCtx(nil)
} else {
r.bcastHeartbeatWithCtx([]byte(lastCtx))
}
}
// sendHeartbeat sends a heartbeat RPC to the given peer.
func (r *raft) sendHeartbeat(to uint64, ctx []byte) {
// Attach the commit as min(to.matched, r.committed).
// When the leader sends out heartbeat message,
// the receiver(follower) might not be matched with the leader
// or it might not have all the committed entries.
// The leader MUST NOT forward the follower's commit to
// an unmatched index.
commit := min(r.prs.Progress[to].Match, r.raftLog.committed)
m := pb.Message{
To: to,
Type: pb.MsgHeartbeat,
Commit: commit,
Context: ctx,
}
r.send(m)
}
// 在candidate和follower状态均会调用,转变为follower
func (r *raft) handleHeartbeat(m pb.Message) {
r.raftLog.commitTo(m.Commit)
r.send(pb.Message{To: m.From, Type: pb.MsgHeartbeatResp, Context: m.Context})
}
|
MsgHeartbeatResp
在Leader接收到了Follower的MsgHeartbeatResp之后,主要做一下的相关处理:
- 如果当前为Probe模式并且处于阻塞模式,ProbeSent设置为false解除阻塞
- RecentActive设置为True,用于进行Check Quorum
- 如果消息队列已满,可以从头释放
- 根据Tracker当中的Match进度和当前的日志情况,考虑是否需要向follower发送新的日志
- 做一些线性一致性的相关处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| case pb.MsgHeartbeatResp:
pr.RecentActive = true
pr.ProbeSent = false
// free one slot for the full inflights window to allow progress.
if pr.State == tracker.StateReplicate && pr.Inflights.Full() {
pr.Inflights.FreeFirstOne()
}
if pr.Match < r.raftLog.lastIndex() {
r.sendAppend(m.From)
}
if r.readOnly.option != ReadOnlySafe || len(m.Context) == 0 {
return nil
}
if r.prs.Voters.VoteResult(r.readOnly.recvAck(m.From, m.Context)) != quorum.VoteWon {
return nil
}
rss := r.readOnly.advance(m)
for _, rs := range rss {
if resp := r.responseToReadIndexReq(rs.req, rs.index); resp.To != None {
r.send(resp)
}
}
|
日志提议#
Leader发送#
上层通过调用Node接口的Propose函数向Raft发起一条提议,将一个操作封装成一条日志,之后用于达成共识,该方法会封装成一条MsgProp的消息,作为添加新日志的起始点。
这里上层所调用的为stepWait函数,并且传下来的为一个Entry数组,为批处理的形式,上层写的channel并发编程暂时没太看懂,先搁置一下。
这里所进行的大部分操作都是遍历当前新的提议日志组当中是否有配置更改的消息,除此之外,涉及到的逻辑并不多:
- 首先检测是否为空日志
- 检测当前的Leader是否在当前配置所规定的集群当中
- 之后首先把日志追加到自身的unstable当中,之后在广播发送给其他的follower
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| case pb.MsgProp:
if len(m.Entries) == 0 {
r.logger.Panicf("%x stepped empty MsgProp", r.id)
}
if r.prs.Progress[r.id] == nil {
// If we are not currently a member of the range (i.e. this node
// was removed from the configuration while serving as leader),
// drop any new proposals.
return ErrProposalDropped
}
if r.leadTransferee != None {
r.logger.Debugf("%x [term %d] transfer leadership to %x is in progress; dropping proposal", r.id, r.Term, r.leadTransferee)
return ErrProposalDropped
}
// 对于上方propose的先处理配置问题,之后将Entries添加并向follower广播发送
// 对于其中包含confChange到信息,进行特殊处理
for i := range m.Entries {
e := &m.Entries[i]
var cc pb.ConfChangeI
if e.Type == pb.EntryConfChange {
var ccc pb.ConfChange
if err := ccc.Unmarshal(e.Data); err != nil {
panic(err)
}
cc = ccc
} else if e.Type == pb.EntryConfChangeV2 {
var ccc pb.ConfChangeV2
if err := ccc.Unmarshal(e.Data); err != nil {
panic(err)
}
cc = ccc
}
if cc != nil {
alreadyPending := r.pendingConfIndex > r.raftLog.applied
alreadyJoint := len(r.prs.Config.Voters[1]) > 0
wantsLeaveJoint := len(cc.AsV2().Changes) == 0
var refused string
if alreadyPending {
refused = fmt.Sprintf("possible unapplied conf change at index %d (applied to %d)", r.pendingConfIndex, r.raftLog.applied)
} else if alreadyJoint && !wantsLeaveJoint {
refused = "must transition out of joint config first"
} else if !alreadyJoint && wantsLeaveJoint {
refused = "not in joint state; refusing empty conf change"
}
if refused != "" {
r.logger.Infof("%x ignoring conf change %v at config %s: %s", r.id, cc, r.prs.Config, refused)
m.Entries[i] = pb.Entry{Type: pb.EntryNormal}
} else {
r.pendingConfIndex = r.raftLog.lastIndex() + uint64(i) + 1
}
}
}
if !r.appendEntry(m.Entries...) {
return ErrProposalDropped
}
r.bcastAppend()
return nil
|
appendEntry
在appendEntry当中,首先对上层传来的日志进行初始化,判断当前Leader与Follower的进度差距,即Leader目前还有多少未commit的日志,如果当前未commit的日志过多,则证明Leader与Follower的差距过大,此时如果继续进行提议,那么就会进一步拉大Leader与Follower成差距,因此拒绝继续提议。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| func (r *raft) increaseUncommittedSize(ents []pb.Entry) bool {
var s uint64
for _, e := range ents {
s += uint64(PayloadSize(e))
}
// 如果当前未提交的日志过多,则证明Follower难以跟上Leader的发送速度
// 因此返回false,之后会拒绝新的提议,防止Leader与Follower之间的差距更大
if r.uncommittedSize > 0 && s > 0 && r.uncommittedSize+s > r.maxUncommittedSize {
// If the uncommitted tail of the Raft log is empty, allow any size
// proposal. Otherwise, limit the size of the uncommitted tail of the
// log and drop any proposal that would push the size over the limit.
// Note the added requirement s>0 which is used to make sure that
// appending single empty entries to the log always succeeds, used both
// for replicating a new leader's initial empty entry, and for
// auto-leaving joint configurations.
return false
}
r.uncommittedSize += s
return true
}
|
之后通过将日志追加到Leader自身的日志当中,并通过MaybeUpdate对自身的Match进行更新,对于自身,写入了自然能够Match,之后再通过maybeCommit去统计当前能够通过投票的日志的进度如何,对自身的commited进度进行更新
1
2
3
4
5
6
7
| // maybeCommit attempts to advance the commit index. Returns true if
// the commit index changed (in which case the caller should call
// r.bcastAppend).
func (r *raft) maybeCommit() bool {
mci := r.prs.Committed()
return r.raftLog.maybeCommit(mci, r.Term)
}
|
1
2
3
4
5
| // Committed returns the largest log index known to be committed based on what
// the voting members of the group have acknowledged.
func (p *ProgressTracker) Committed() uint64 {
return uint64(p.Voters.CommittedIndex(matchAckIndexer(p.Progress)))
}
|
appendEntry的完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| func (r *raft) appendEntry(es ...pb.Entry) (accepted bool) {
li := r.raftLog.lastIndex()
// 上层传入的日志当中不清楚下层的Term和Index情况,因此在此处进行封装
for i := range es {
es[i].Term = r.Term
es[i].Index = li + 1 + uint64(i)
}
// Track the size of this uncommitted proposal.
if !r.increaseUncommittedSize(es) {
r.logger.Debugf(
"%x appending new entries to log would exceed uncommitted entry size limit; dropping proposal",
r.id,
)
// Drop the proposal.
return false
}
// use latest "last" index after truncate/append
li = r.raftLog.append(es...)
r.prs.Progress[r.id].MaybeUpdate(li)
// Regardless of maybeCommit's return, our caller will call bcastAppend.
r.maybeCommit()
return true
}
|
bcastAppend
通过progress遍历所有的节点,尝试发送AppendEntries,这两段的逻辑都比较简单,重点在于封装的maybeSendAppend
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // bcastAppend sends RPC, with entries to all peers that are not up-to-date
// according to the progress recorded in r.prs.
// 封装一个发送AppendEntries的函数作为参数传递给Visit,之后Visit遍历并调用该函数
func (r *raft) bcastAppend() {
r.prs.Visit(func(id uint64, _ *tracker.Progress) {
if id == r.id {
return
}
r.sendAppend(id)
})
}
// sendAppend sends an append RPC with new entries (if any) and the
// current commit index to the given peer.
func (r *raft) sendAppend(to uint64) {
r.maybeSendAppend(to, true)
}
|
maybeSendAppend
对于日志与快照的发送均通过该函数进行,大致步骤如下:
首先通过progress检查对方是否处于阻塞状态,如果阻塞,则拒绝发送
尝试获取到需要发送给对方的日志和对应的Term,并在这过过程判断需要发送的日志是否过旧已经被快照化
在上一步当中如果判断出了已经被快照化,那么就转变为发送快照:
如果发送对方并没有通过RecentActive的检查的话,再加上对方目前已经长时间落后于Leader,可以认定为其已经宕机或者产生网络分区,无法和leader进行通信,因此拒绝发送
封装MsgSnap,准备发送日志,并将对方的状态转换为StateSnaphot
如之前所讨论的:在follower转为StateSnapshot后,只有两种跳出StateSnapshot的方法:
- follower节点应用快照后会发送MsgAppResp消息,该消息会报告当前follower的last index。如果follower应用了快照后last index就追赶上了其match index,那么leader会直接将follower的状态转移到StateRelicate状态,为其继续复制日志。
- leader节点的使用者还需要主动调用Node的ReportSnapshot方法告知leader节点快照的应用状态,
leader会将该follower的状态转移到StateProbe状态(与方法1重复的消息会被忽略)。
否则,发送日志,在完成MsgApp的封装之后,根据当前的状态去更新状态
最后的最后,调用send封装一条Msg交给上层进行发送
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| func (r *raft) maybeSendAppend(to uint64, sendIfEmpty bool) bool {
pr := r.prs.Progress[to]
// 对方由于某些原因处于阻塞状态,拒绝发送
if pr.IsPaused() {
return false
}
m := pb.Message{}
m.To = to
term, errt := r.raftLog.term(pr.Next - 1)
ents, erre := r.raftLog.entries(pr.Next, r.maxMsgSize)
if len(ents) == 0 && !sendIfEmpty {
return false
}
// 可能由于对方进度过慢导致日志内容已经被快照化,此时尝试发送快照
if errt != nil || erre != nil { // send snapshot if we failed to get term or entries
if !pr.RecentActive {
r.logger.Debugf("ignore sending snapshot to %x since it is not recently active", to)
return false
}
m.Type = pb.MsgSnap
snapshot, err := r.raftLog.snapshot()
if err != nil {
if err == ErrSnapshotTemporarilyUnavailable {
r.logger.Debugf("%x failed to send snapshot to %x because snapshot is temporarily unavailable", r.id, to)
return false
}
panic(err) // TODO(bdarnell)
}
if IsEmptySnap(snapshot) {
panic("need non-empty snapshot")
}
m.Snapshot = snapshot
sindex, sterm := snapshot.Metadata.Index, snapshot.Metadata.Term
r.logger.Debugf("%x [firstindex: %d, commit: %d] sent snapshot[index: %d, term: %d] to %x [%s]",
r.id, r.raftLog.firstIndex(), r.raftLog.committed, sindex, sterm, to, pr)
pr.BecomeSnapshot(sindex)
r.logger.Debugf("%x paused sending replication messages to %x [%s]", r.id, to, pr)
} else {
m.Type = pb.MsgApp
m.Index = pr.Next - 1
m.LogTerm = term
m.Entries = ents
m.Commit = r.raftLog.committed
if n := len(m.Entries); n != 0 {
switch pr.State {
// optimistically increase the next when in StateReplicate
case tracker.StateReplicate:
// 当前正以流水线的方法优化日志的复制速度,即follower可以确保跟上leader的进度
// 因此可以直接设置nest
last := m.Entries[n-1].Index
pr.OptimisticUpdate(last)
pr.Inflights.Add(last)
case tracker.StateProbe:
// 在Probe模式下,一次只能发送一条日志,并且需要等待对方的回应之后才能继续发送
// 在此处设置为true用于在IsPaused()当中进行阻塞,直到收到follower的确认
pr.ProbeSent = true
default:
r.logger.Panicf("%x is sending append in unhandled state %s", r.id, pr.State)
}
}
}
r.send(m)
return true
}
|
Follower处理与响应#
在Candidate和Follower状态下都会接收并处理MsgApp,如果是Candidate,就多了一步转换为follower的步骤,之后调用handleAppendEntries进行处理:
- 如果发送来的日志已经committed,那么则为一条陈旧消息,返回给Leader自己当前的进度即可
- 之后调用raftLog的maybeAppend,在其中处理冲突并且返回是否添加成功,最终更新commit的进度,关于commit,在上面讲述raftlog时已经说明过为什么要min(lastnewi,committed),如果能够成功添加就可以直接向Leader发送MsgAppResp了,返回当前的最新的日志的Index表明进度
- 如果添加失败,则代表存在冲突,在follower端按照快速回退的方式根据Term找到冲突的位置,即第一个Term <= Msg.Term并且Index <= Msg.Index的位置之后将Reject字段设置为true,设置HintIndex、HintTerm返回给Leader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| func (r *raft) handleAppendEntries(m pb.Message) {
if m.Index < r.raftLog.committed {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.committed})
return
}
if mlastIndex, ok := r.raftLog.maybeAppend(m.Index, m.LogTerm, m.Commit, m.Entries...); ok {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: mlastIndex})
} else {
r.logger.Debugf("%x [logterm: %d, index: %d] rejected MsgApp [logterm: %d, index: %d] from %x",
r.id, r.raftLog.zeroTermOnErrCompacted(r.raftLog.term(m.Index)), m.Index, m.LogTerm, m.Index, m.From)
// Return a hint to the leader about the maximum index and term that the
// two logs could be divergent at. Do this by searching through the
// follower's log for the maximum (index, term) pair with a term <= the
// MsgApp's LogTerm and an index <= the MsgApp's Index. This can help
// skip all indexes in the follower's uncommitted tail with terms
// greater than the MsgApp's LogTerm.
//
// See the other caller for findConflictByTerm (in stepLeader) for a much
// more detailed explanation of this mechanism.
hintIndex := min(m.Index, r.raftLog.lastIndex())
hintIndex = r.raftLog.findConflictByTerm(hintIndex, m.LogTerm)
hintTerm, err := r.raftLog.term(hintIndex)
if err != nil {
panic(fmt.Sprintf("term(%d) must be valid, but got %v", hintIndex, err))
}
r.send(pb.Message{
To: m.From,
Type: pb.MsgAppResp,
Index: m.Index,
Reject: true,
RejectHint: hintIndex,
LogTerm: hintTerm,
})
}
}
|
Leader接收MsgAppResp#
到这里也是日志复制的最后一步,Leader根据Follower的响应来决定后续的行为,接收到消息首先可以将该follower标记为RecentActive,之后先来说存在冲突的情况:
存在冲突:
存在冲突,即MsgAppResp当中的Reject为true,对应的还会有Follower返回的HintIndex(RejectHint)与HintTerm(Logterm),在follower的handAppendEntries当中,如果follower的进度过旧,导致index out of range的话,Term就会设置为0,因此首先判断Term是否为0,如果不为0的话就证明在follower当中找到了对应的冲突位置,可以根据返回的HintIndex、HintTerm在Leader当中找到对应的位置,设置为Next,用于下一次发送。
之后尝试对Leader的Next记录进行回退,如果回退失败则说明为一条过期的日志,不处理,否则将follower的状态记录为StateProbe,进行探测发送,理想的情况下可以一轮探测就让follower和Leader正确跟随对齐进度,再重新转换为StateReplicate。
不存在冲突
先尝试根据返回的Index对match进行更新,如果更新失败,则证明Leader的Match进度快于Follower返回的,证明:
- 该消息为一条过期的消息,不进行处理
- 该MsgAppResp由快照应用快照后产生的消息,此时follower仍未跟上其MatchIndex,无法完成匹配
- 该消息为StateProbe状态发送的确认消息,由于StateProbe状态只进行探测,一次性只在一次心跳周期当中发送一条日志,无法进行日志复制跟随状态,所以此时仍没有Match上,不做处理,等到之后收到下一个周期的HeartbeatResp再解除阻塞
如果能够更新成功:
- 如果当前为StateProbe,那么则证明通过探测对齐了进度,此时就可以转换为StateReplicate去快速发送日志更新状态
- 如果当前为StateSnapshot,并且Match的进度超过了Snapshot,此时同样可以转换为StateReplicate
- 而StateReplicate下只需释放部分消息队列的容量即可
处理完状态转换之后,Leader可以尝试通过检测各个follower的复制进度来决定commit,这个动作为异步的,由于引入了ProgressTracker,则可以根据当前记录的信息时不时的触发maybeCommit来推进commit进度,无需向MIT-6.824那样发送完AppendEntries RPC之后在这里等待响应以确定commit,如果commit的进度得到推进,就可以额在广播一次AppendEntries将commit进度携带于其中,发送给follower
如果commit index没有更新,还需要进一步判断该follower之前是否是阻塞的,如果是那么为该follower发送一条日志复制消息以更新其committed索引,因为在该节点阻塞时可能错过了committed索引的更新消息。
之后尝试通过for循环去不断的发送AppendEntries。因为日志复制部分有流控逻辑,因此这里的循环不会成为死循环。这样做可以尽可能多地为节点复制日志,以提高日志复制效率。
1
2
3
4
5
6
7
| func (r *raft) maybeSendAppend(to uint64, sendIfEmpty bool) bool {
// ...
if len(ents) == 0 && !sendIfEmpty {
return false
}
// ...
}
|
至此,所有关于MsgAppResp的处理全部完成,这一部分尤其是reject进行快速回退的过程当中etcd给出了大量的样例用于说明不同情况下的对齐进度和对齐方式,个人认为非常有必要一读,以更好的理解整个回退的过程。
除此之外,在发送过程当中,快照发送的过程与响应的过程夹杂在日志的处理过程打红中顺便给说明了,但是对于follower应当如何应用快照还未涉及到,因此再来看一下快照应用的过程,这个过程也比较简单,贴一下代码即可
1
2
3
4
5
6
7
8
9
10
11
12
13
| func (r *raft) handleSnapshot(m pb.Message) {
sindex, sterm := m.Snapshot.Metadata.Index, m.Snapshot.Metadata.Term
if r.restore(m.Snapshot) {
r.logger.Infof("%x [commit: %d] restored snapshot [index: %d, term: %d]",
r.id, r.raftLog.committed, sindex, sterm)
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.lastIndex()})
} else {
// 自身的进度快于发送的Snaoshot,将自己commit的最后一条日志发送给Leader,便于其更新Match与Next
r.logger.Infof("%x [commit: %d] ignored snapshot [index: %d, term: %d]",
r.id, r.raftLog.committed, sindex, sterm)
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.committed})
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| func (r *raft) restore(s pb.Snapshot) bool {
if s.Metadata.Index <= r.raftLog.committed {
return false
}
if r.state != StateFollower {
// This is defense-in-depth: if the leader somehow ended up applying a
// snapshot, it could move into a new term without moving into a
// follower state. This should never fire, but if it did, we'd have
// prevented damage by returning early, so log only a loud warning.
//
// At the time of writing, the instance is guaranteed to be in follower
// state when this method is called.
r.logger.Warningf("%x attempted to restore snapshot as leader; should never happen", r.id)
r.becomeFollower(r.Term+1, None)
return false
}
// More defense-in-depth: throw away snapshot if recipient is not in the
// config. This shouldn't ever happen (at the time of writing) but lots of
// code here and there assumes that r.id is in the progress tracker.
found := false
cs := s.Metadata.ConfState
for _, set := range [][]uint64{
cs.Voters,
cs.Learners,
cs.VotersOutgoing,
// `LearnersNext` doesn't need to be checked. According to the rules, if a peer in
// `LearnersNext`, it has to be in `VotersOutgoing`.
} {
for _, id := range set {
if id == r.id {
found = true
break
}
}
if found {
break
}
}
if !found {
r.logger.Warningf(
"%x attempted to restore snapshot but it is not in the ConfState %v; should never happen",
r.id, cs,
)
return false
}
// Now go ahead and actually restore.
// 在自身的日志当中可以找到Snapshot当中最后的Index和Term,对该Snapshot进行忽略
if r.raftLog.matchTerm(s.Metadata.Index, s.Metadata.Term) {
r.logger.Infof("%x [commit: %d, lastindex: %d, lastterm: %d] fast-forwarded commit to snapshot [index: %d, term: %d]",
r.id, r.raftLog.committed, r.raftLog.lastIndex(), r.raftLog.lastTerm(), s.Metadata.Index, s.Metadata.Term)
// 快照当中的为已经提交的日志,因此可能需要对本地的commit进度进行更新
r.raftLog.commitTo(s.Metadata.Index)
return false
}
r.raftLog.restore(s)
// Reset the configuration and add the (potentially updated) peers in anew.
r.prs = tracker.MakeProgressTracker(r.prs.MaxInflight)
cfg, prs, err := confchange.Restore(confchange.Changer{
Tracker: r.prs,
LastIndex: r.raftLog.lastIndex(),
}, cs)
if err != nil {
// This should never happen. Either there's a bug in our config change
// handling or the client corrupted the conf change.
panic(fmt.Sprintf("unable to restore config %+v: %s", cs, err))
}
assertConfStatesEquivalent(r.logger, cs, r.switchToConfig(cfg, prs))
pr := r.prs.Progress[r.id]
pr.MaybeUpdate(pr.Next - 1) // TODO(tbg): this is untested and likely unneeded
r.logger.Infof("%x [commit: %d, lastindex: %d, lastterm: %d] restored snapshot [index: %d, term: %d]",
r.id, r.raftLog.committed, r.raftLog.lastIndex(), r.raftLog.lastTerm(), s.Metadata.Index, s.Metadata.Term)
return true
}
|
相关优化#
引用:etcd/raft
快速回退#
快速回退在Raft原本论文和MIT6.824的课上都做出了相关说明,在上文中也分析了整个过程,即通过follower去找到和自身冲突的位置,之后返回给Leader,不过在Raft原文当中,采用的是XTerm + XLen + XIndex的组合方式来解决问题:
- XTerm:冲突的term号
- XIndex:XTerm的第一个Index
- Xlen:follower的日志的长度
case:
- 对于第一个case:s2第一次发送AppendEntry后接收到的XTerm为5,XIndex为2(index从1开始),leader当中并没有term = 5,因此后续的AppendEntry可以直接跳转到Index = 2开始发送
- 对于第二个case:leader当中含有XTerm = 4,因此leader就从XTerm的最后一个Entry开始进行同步
- 对于第三个case:follower当中不存在leader的entry,通过XLen来找到最后一个Entry进行同步
MIT6.824当中的实现:
follower
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| // figure 2 AppendEntries RPC Receiver implementation 2
// log is too short
if rf.getLastIndex() < args.PrevLogIndex {
reply.Success = false
reply.Conflict = true
reply.XTerm = -1
reply.XIndex = -1
reply.XLen = rf.getLastIndex()
Debug(dLog, "S%d follower's log is to short,index:%d,prevLogIndex%d", rf.me, rf.getLastIndex(), args.PrevLogIndex)
Debug(dLog, "S%d Conflict Xterm %d,XIndex %d,XLen %d", rf.me, reply.XTerm, reply.XIndex, reply.XLen)
return
}
Debug(dLog, "S%d log is %s", rf.me, rf.log.String())
// figure 2 AppendEntries RPC Receiver implementation 2
if rf.restoreLogTerm(args.PrevLogIndex) != args.PrevLogTerm {
reply.Success = false
reply.Conflict = true
// set XTerm XLen XIndex
reply.XTerm = rf.restoreLogTerm(args.PrevLogIndex)
for idx := args.PrevLogIndex; idx > rf.lastIncludedIndex; idx-- {
// the first index of the conflict term
if rf.restoreLogTerm(idx-1) != reply.XTerm {
reply.XIndex = idx
break
}
}
reply.XLen = len(rf.log.Entries)
Debug(dLog, "S%d Conflict Xterm %d, XIndex %d,XLen %d", rf.me, reply.XTerm, reply.XIndex, reply.XLen)
return
}
|
leader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| } else if reply.Conflict {
// 如果存在冲突则通过XTerm XLen XIndex进行快速定位
// XTerm == -1则证明 follower当中日志过短,不存在和发送的同term的entry,直接按长度从最末尾进行重写
if reply.XTerm == -1 {
rf.nextIndex[server] = reply.XLen
} else {
// xIndex为0则证明 follower当中没找到,即只有一个term的情况,需要leader进行定位
// follower : 4 4 4
// leader : 4 4 5 5 5
if reply.XIndex == 0 {
last := rf.findLastLogByTerm(reply.XTerm)
rf.nextIndex[server] = last
} else {
// XIndex找到了则直接使用XIndex的即可
// 也有可能是follower的日志已经快照化,让leader重新探查
rf.nextIndex[server] = reply.XIndex
}
}
}
|
在etcd/raft当中,考虑到故障并不会经常发生,将follower的最后一条日志作为该字段的值,因此回退到follower的最后一条日志之后由Leader去一条条检查日志。
并行写入#
在原本的Raft当中,对于新提议的日志,首先需要将新日志首先写入到本地存储之后再为follower复制日志,发送网络请求的过程被写入持久化的操作阻塞,造成延迟。
通过并行写入的方式,leader可以在为follower复制日志的同时将日志写入到本地的稳定存储之中,leader自己的match index表示其写入到了稳定存储的最后一条日志的索引。当当前term的某日志被大多数的match index覆盖时,leader便可以使commit index前进到该节点处。
批处理#
批处理的操作主要体现在以下几个方面:
- propose时stepWait,积攒一批propose,最后通过Step向下提交的为一个[]Entry
- 通过Ready所向上层返回的也是一批数据,一段时间内需要进行持久化的HardState、Entry、Snapshot、需要发送给其他节点的[]Messages
- leader在为follower进行日志复制时也会成组发送,这个在6.824当中也有,算是基本实现
流水线#
和体系机构当中的概念相同,在StateReplicate的状态下,Leader认为Follower可以稳定跟随Leader的进度,因此在不收到响应之前,立即对Leader所匹配的NextIndex进行更新,之后继续处理下一条,在同一时间,Leader所在发送的还未结束的指令不止一条。
在正常且稳定的情况下,消息应恰好一次且有序到达。但是在异常情况下,可能出现消息丢失、消息乱序。当follower收到过期的日志复制请求时,会拒绝该请求,随后follower会回退其nextIndex以重传之后的日志。
Summary#
相比于Raft选举的过程当中,日志复制的整个流程和要考虑的东西也就复杂的多,再引入了Step、ProgressTracker、以及存储与通信单独处理,将存储、通信、状态跟踪与确认和整个复制流程解藕之后架构上还是比较清晰的。不过由于分布式的不确定性,整个实现上基本遵循了防御性编程的理念,以确保系统处于预期的状态。