在etcd中,raft作为一个单独的模块被拆分出来,位于etcd的目录下,在新版本当中, etcd/raft被拆分出来,处于一个单独的仓库被etcd引用:GitHub - etcd-io/raft: Raft library for maintaining a replicated state machine
etcd/raft作为一个投入生产环境的raft package,ectd/raft在架构上的最大的魅力就是将整个系统视为一个状态机,并且将各部分进行解耦:
在基础结构上,etcd/raft将raft视为一个状态机,上层给予Raft一些输入,如tick或者message,Raft就会根据输入作出一些响应,更改自身状态,最后提供一些输出,上层处理完输出之后再调用Advance来继续推进Raft去更新状态。
在etcd当中,raft package仅提供raft的逻辑,如如何进行选举和发送日志,但是如持久化存储,网络通信都由上层应用负责,raft package通过 Ready 将需要存储的日志,快照,以及需要发送的消息交给上层。
在结构上,etcd/raft以Message为主体和驱动,整个Raft的执行流程就是在tick的驱动下,不断的执行和发送Message的过程,并不会像MIT6.824 当中那样在一个函数当中能看到完整的rpc调用和处理流程,每个Message只会负责整体逻辑的一部分,执行完自己的内容就生成一个新的Message发送,其他拿到这条Message的来完成这个事件的剩余逻辑,举个例子,在进行选举时:
- candidate首先会向其他节点发送一个请求投票的Message,此时candidate目前负责的逻辑已经执行结束,candidate可以去执行其他内容
- follower受到candidate发送的Message就会进行处理,投票或者忽略,同样将结果封装成一条Message再发送给candidate
- Candidate 再收到 Message 之后继续完成剩余的逻辑,统计投票,决定是否当选
整个执行过程是松散、非连续的。但是主体逻辑全部使用 Message 来承载的话,整体结构就会非常清晰,raft 只需要不断的处理 Message 即可,并在适当的时候产生新的 Message,这也符合状态机的定义,即Message和Command作为系统的输入,调用Ready产生的Log, Message, Snapshot作为系统的输出。
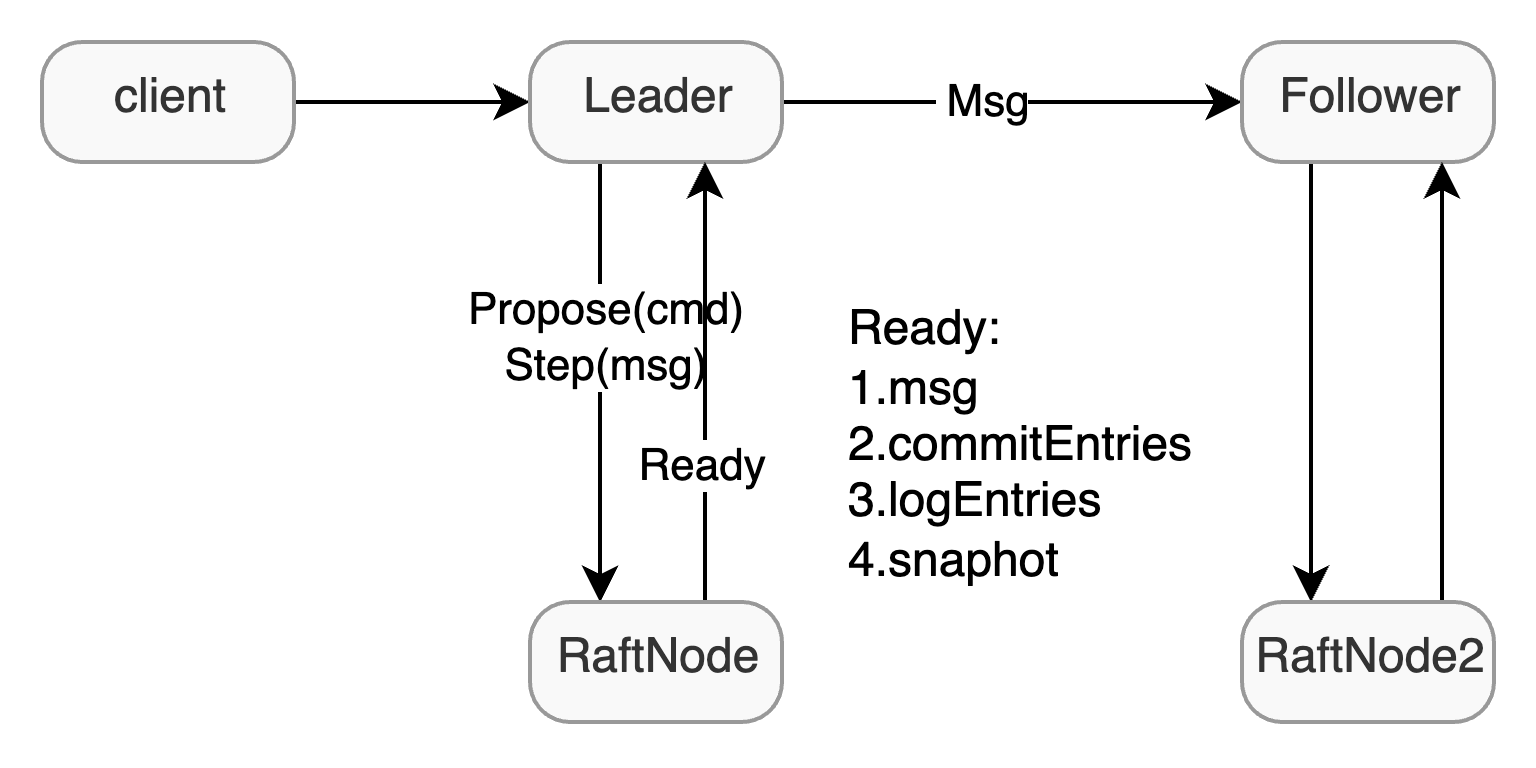
正如上面所说,单独的etcd/raft是无法运行的,需要补充额外的逻辑,用于调用驱etcd/raft,这一部分在etcd当中也有实现,位于raftexample目录下。提供了一个使用raft来提供http kv存储的最小实现。因此,在本文中,笔者也会分为raft example 和 raft package两部分介绍etcd/raft。后续为了便于区分,笔者会将上层驱动性质的称为 RaftNode ,而下层则称为Raft package或者底层Raft,而最上层接收请求的部分则称为状态机。
Raft example#
这一部分代码位于 contrib/raftexample 当中,除去http封装,剩下的逻辑可以分为两部分:
- KVStore:充当状态机,接收http层传来的请求,将请求封装,通过propose向下传递,同时读取commit的日志,应用到自身
- RaftNode:驱动底层Raft,完成通信,存储等额外功能
State machine#
kvstore,即状态机,实现的非常简单,结构体定义如下:
1
2
3
4
5
6
| type kvstore struct {
proposeC chan<- string // channel for proposing updates
mu sync.RWMutex
kvStore map[string]string // current committed key-value pairs
snapshotter *snap.Snapshotter
}
|
在初始化时,通过传入的参数,建立起了状态机和RaftNode的连接:
- snapshotter:用于通知,加载日志,通过日志完成系统的恢复
- proposeC:channel发送方,将接收到的请求进行封装,通过该channel发送给raft
- commitC:接收下层raft确认提交的内容,应用到状态机
- errorC:处理error
在状态机初始化完成后,开启一个协程,用于从下层读取提交的日志,状态机本身提供propose和lookup来处理读写请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| func newKVStore(snapshotter *snap.Snapshotter, proposeC chan<- string, commitC <-chan *commit, errorC <-chan error) *kvstore {
s := &kvstore{proposeC: proposeC, kvStore: make(map[string]string), snapshotter: snapshotter}
snapshot, err := s.loadSnapshot()
if err != nil {
log.Panic(err)
}
if snapshot != nil {
log.Printf("loading snapshot at term %d and index %d", snapshot.Metadata.Term, snapshot.Metadata.Index)
if err := s.recoverFromSnapshot(snapshot.Data); err != nil {
log.Panic(err)
}
}
// read commits from raft into kvStore map until error
go s.readCommits(commitC, errorC)
return s
}
|
不过,在raft example当中,仅仅只是做了简单的演示,并没有提供线性一致性读的保证,lookup仅仅会直接搜索当前已经commit的内容,对于在此次读取前发送,但还没有应用的内容无法读取。如果想满足线性一致性也很简单,可以直接使用log read,对于读请求也封装成日志去共识,或者使用readIndex/lease read来完成优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| func (s *kvstore) Lookup(key string) (string, bool) {
s.mu.RLock()
defer s.mu.RUnlock()
v, ok := s.kvStore[key]
return v, ok
}
func (s *kvstore) Propose(k string, v string) {
var buf strings.Builder
if err := gob.NewEncoder(&buf).Encode(kv{k, v}); err != nil {
log.Fatal(err)
}
s.proposeC <- buf.String()
}
|
RaftNode#
在raft example中,通过RaftNode完成对Raft Package的调用,驱动下层Raft运行,并且处理掉存储,消息发送,提交日志应用等操作。
为了研究RaftNode如何驱动底层Raft的运行,我们不妨先看看下层提供或者说暴露了什么接口,这里封装成了一个interface的形式,。对于RaftNode而言,只需要通过配置信息来初始化该Interface的实现,然后在合适的时机调用对应的方法即可。:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
| // Node represents a node in a raft cluster.
type Node interface {
// Tick increments the internal logical clock for the Node by a single tick. Election
// timeouts and heartbeat timeouts are in units of ticks.
Tick()
// Campaign causes the Node to transition to candidate state and start campaigning to become leader.
Campaign(ctx context.Context) error
// Propose proposes that data be appended to the log. Note that proposals can be lost without
// notice, therefore it is user's job to ensure proposal retries.
Propose(ctx context.Context, data []byte) error
// ProposeConfChange proposes a configuration change. Like any proposal, the
// configuration change may be dropped with or without an error being
// returned. In particular, configuration changes are dropped unless the
// leader has certainty that there is no prior unapplied configuration
// change in its log.
//
// The method accepts either a pb.ConfChange (deprecated) or pb.ConfChangeV2
// message. The latter allows arbitrary configuration changes via joint
// consensus, notably including replacing a voter. Passing a ConfChangeV2
// message is only allowed if all Nodes participating in the cluster run a
// version of this library aware of the V2 API. See pb.ConfChangeV2 for
// usage details and semantics.
ProposeConfChange(ctx context.Context, cc pb.ConfChangeI) error
// Step advances the state machine using the given message. ctx.Err() will be returned, if any.
Step(ctx context.Context, msg pb.Message) error
// Ready returns a channel that returns the current point-in-time state.
// Users of the Node must call Advance after retrieving the state returned by Ready (unless
// async storage writes is enabled, in which case it should never be called).
//
// NOTE: No committed entries from the next Ready may be applied until all committed entries
// and snapshots from the previous one have finished.
Ready() <-chan Ready
// Advance notifies the Node that the application has saved progress up to the last Ready.
// It prepares the node to return the next available Ready.
//
// The application should generally call Advance after it applies the entries in last Ready.
//
// However, as an optimization, the application may call Advance while it is applying the
// commands. For example. when the last Ready contains a snapshot, the application might take
// a long time to apply the snapshot data. To continue receiving Ready without blocking raft
// progress, it can call Advance before finishing applying the last ready.
//
// NOTE: Advance must not be called when using AsyncStorageWrites. Response messages from the
// local append and apply threads take its place.
Advance()
// ApplyConfChange applies a config change (previously passed to
// ProposeConfChange) to the node. This must be called whenever a config
// change is observed in Ready.CommittedEntries, except when the app decides
// to reject the configuration change (i.e. treats it as a noop instead), in
// which case it must not be called.
//
// Returns an opaque non-nil ConfState protobuf which must be recorded in
// snapshots.
ApplyConfChange(cc pb.ConfChangeI) *pb.ConfState
// TransferLeadership attempts to transfer leadership to the given transferee.
TransferLeadership(ctx context.Context, lead, transferee uint64)
// ForgetLeader forgets a follower's current leader, changing it to None. It
// remains a leaderless follower in the current term, without campaigning.
//
// This is useful with PreVote+CheckQuorum, where followers will normally not
// grant pre-votes if they've heard from the leader in the past election
// timeout interval. Leaderless followers can grant pre-votes immediately, so
// if a quorum of followers have strong reason to believe the leader is dead
// (for example via a side-channel or external failure detector) and forget it
// then they can elect a new leader immediately, without waiting out the
// election timeout. They will also revert to normal followers if they hear
// from the leader again, or transition to candidates on an election timeout.
//
// For example, consider a three-node cluster where 1 is the leader and 2+3
// have just received a heartbeat from it. If 2 and 3 believe the leader has
// now died (maybe they know that an orchestration system shut down 1's VM),
// we can instruct 2 to forget the leader and 3 to campaign. 2 will then be
// able to grant 3's pre-vote and elect 3 as leader immediately (normally 2
// would reject the vote until an election timeout passes because it has heard
// from the leader recently). However, 3 can not campaign unilaterally, a
// quorum have to agree that the leader is dead, which avoids disrupting the
// leader if individual nodes are wrong about it being dead.
//
// This does nothing with ReadOnlyLeaseBased, since it would allow a new
// leader to be elected without the old leader knowing.
ForgetLeader(ctx context.Context) error
// ReadIndex request a read state. The read state will be set in the ready.
// Read state has a read index. Once the application advances further than the read
// index, any linearizable read requests issued before the read request can be
// processed safely. The read state will have the same rctx attached.
// Note that request can be lost without notice, therefore it is user's job
// to ensure read index retries.
ReadIndex(ctx context.Context, rctx []byte) error
// Status returns the current status of the raft state machine.
Status() Status
// ReportUnreachable reports the given node is not reachable for the last send.
ReportUnreachable(id uint64)
// ReportSnapshot reports the status of the sent snapshot. The id is the raft ID of the follower
// who is meant to receive the snapshot, and the status is SnapshotFinish or SnapshotFailure.
// Calling ReportSnapshot with SnapshotFinish is a no-op. But, any failure in applying a
// snapshot (for e.g., while streaming it from leader to follower), should be reported to the
// leader with SnapshotFailure. When leader sends a snapshot to a follower, it pauses any raft
// log probes until the follower can apply the snapshot and advance its state. If the follower
// can't do that, for e.g., due to a crash, it could end up in a limbo, never getting any
// updates from the leader. Therefore, it is crucial that the application ensures that any
// failure in snapshot sending is caught and reported back to the leader; so it can resume raft
// log probing in the follower.
ReportSnapshot(id uint64, status SnapshotStatus)
// Stop performs any necessary termination of the Node.
Stop()
}
|
启动流程#
在 newRaftNode 当中,逻辑分为三部分:
- 初始化底层raft节点,并建立起各个节点间的通信
- 开启一个channel,驱动底层Raft,并从底层Raft获取已经处理好的信息
- 配置channel,完成RaftNode和状态机之间的双向连通
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| // newRaftNode initiates a raft instance and returns a committed log entry
// channel and error channel. Proposals for log updates are sent over the
// provided the proposal channel. All log entries are replayed over the
// commit channel, followed by a nil message (to indicate the channel is
// current), then new log entries. To shutdown, close proposeC and read errorC.
func newRaftNode(id int, peers []string, join bool, getSnapshot func() ([]byte, error), proposeC <-chan string,
confChangeC <-chan raftpb.ConfChange) (<-chan *commit, <-chan error, <-chan *snap.Snapshotter) {
commitC := make(chan *commit)
errorC := make(chan error)
rc := &raftNode{
proposeC: proposeC,
confChangeC: confChangeC,
commitC: commitC,
errorC: errorC,
id: id,
peers: peers,
join: join,
waldir: fmt.Sprintf("raftexample-%d", id),
snapdir: fmt.Sprintf("raftexample-%d-snap", id),
getSnapshot: getSnapshot,
snapCount: defaultSnapshotCount,
stopc: make(chan struct{}),
httpstopc: make(chan struct{}),
httpdonec: make(chan struct{}),
logger: zap.NewExample(),
snapshotterReady: make(chan *snap.Snapshotter, 1),
// rest of structure populated after WAL replay
}
go rc.startRaft()
return commitC, errorC, rc.snapshotterReady
}
|
Raft Package初始化#
Raft package的初始化封装在 startRaft() 当中,主要逻辑为:
- 读取原本的持久化文件,获取snapshot和wal中的内容,恢复状态。这里的wal是log entry的wal,因为raft package并不会对log进行持久化存储,因此在raft example当中提供了一个wal + memory的存储方式,对应结构体为MemoryStorage
- 生成一份配置,初始化下层的Raft package中的节点
- 初始化网络,连通各个节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| func (rc *raftNode) startRaft() {
if !fileutil.Exist(rc.snapdir) {
if err := os.Mkdir(rc.snapdir, 0750); err != nil {
log.Fatalf("raftexample: cannot create dir for snapshot (%v)", err)
}
}
rc.snapshotter = snap.New(zap.NewExample(), rc.snapdir)
oldwal := wal.Exist(rc.waldir)
rc.wal = rc.replayWAL()
// signal replay has finished
rc.snapshotterReady <- rc.snapshotter
rpeers := make([]raft.Peer, len(rc.peers))
for i := range rpeers {
rpeers[i] = raft.Peer{ID: uint64(i + 1)}
}
c := &raft.Config{
ID: uint64(rc.id),
ElectionTick: 10,
HeartbeatTick: 1,
Storage: rc.raftStorage,
MaxSizePerMsg: 1024 * 1024,
MaxInflightMsgs: 256,
MaxUncommittedEntriesSize: 1 << 30,
}
if oldwal || rc.join {
rc.node = raft.RestartNode(c)
} else {
rc.node = raft.StartNode(c, rpeers)
}
rc.transport = &rafthttp.Transport{
Logger: rc.logger,
ID: types.ID(rc.id),
ClusterID: 0x1000,
Raft: rc,
ServerStats: stats.NewServerStats("", ""),
LeaderStats: stats.NewLeaderStats(zap.NewExample(), strconv.Itoa(rc.id)),
ErrorC: make(chan error),
}
rc.transport.Start()
for i := range rc.peers {
if i+1 != rc.id {
rc.transport.AddPeer(types.ID(i+1), []string{rc.peers[i]})
}
}
go rc.serveRaft()
go rc.serveChannels()
}
|
serveChannels#
完成Raft Package的初始化之后,通过 serveChannls (在startRaft当中被调用)会建立raft node和raft package之间的连接,即将propose的请求向下传递,并且从下层获取处理完的内容。
从raft node至 raft package自上向下的过程比较简单,只需要把propose和confChange调用对应的方法就可以传递下去,而这两个请求来自于状态机,即raft node只是通过channel做了一次转发
自下向上通过Ready结构体进行传递,主要内容为:
- SoftState:不需要持久化存储的状态,其中包含的当前节点的身份和Leader Id
- HardState:持久化存储的状态,如Raft论文中所述,其中包含了VoteFor Term和Commit进度
- ReadState:ReadIndex线性一致性读优化
- Entry: Log Entry,交给上层存储
- Snapshot,同,上层进行存储
- CommitEntries:确定提交的日志,可以交给上层来完成Apply
- Message:发送给其他的节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| // Ready encapsulates the entries and messages that are ready to read,
// be saved to stable storage, committed or sent to other peers.
// All fields in Ready are read-only.
type Ready struct {
// The current volatile state of a Node.
// SoftState will be nil if there is no update.
// It is not required to consume or store SoftState.
*SoftState
// The current state of a Node to be saved to stable storage BEFORE
// Messages are sent.
//
// HardState will be equal to empty state if there is no update.
//
// If async storage writes are enabled, this field does not need to be acted
// on immediately. It will be reflected in a MsgStorageAppend message in the
// Messages slice.
pb.HardState
// ReadStates can be used for node to serve linearizable read requests locally
// when its applied index is greater than the index in ReadState.
// Note that the readState will be returned when raft receives msgReadIndex.
// The returned is only valid for the request that requested to read.
ReadStates []ReadState
// Entries specifies entries to be saved to stable storage BEFORE
// Messages are sent.
//
// If async storage writes are enabled, this field does not need to be acted
// on immediately. It will be reflected in a MsgStorageAppend message in the
// Messages slice.
Entries []pb.Entry
// Snapshot specifies the snapshot to be saved to stable storage.
//
// If async storage writes are enabled, this field does not need to be acted
// on immediately. It will be reflected in a MsgStorageAppend message in the
// Messages slice.
Snapshot pb.Snapshot
// CommittedEntries specifies entries to be committed to a
// store/state-machine. These have previously been appended to stable
// storage.
//
// If async storage writes are enabled, this field does not need to be acted
// on immediately. It will be reflected in a MsgStorageApply message in the
// Messages slice.
CommittedEntries []pb.Entry
// Messages specifies outbound messages.
//
// If async storage writes are not enabled, these messages must be sent
// AFTER Entries are appended to stable storage.
//
// If async storage writes are enabled, these messages can be sent
// immediately as the messages that have the completion of the async writes
// as a precondition are attached to the individual MsgStorage{Append,Apply}
// messages instead.
//
// If it contains a MsgSnap message, the application MUST report back to raft
// when the snapshot has been received or has failed by calling ReportSnapshot.
Messages []pb.Message
// MustSync indicates whether the HardState and Entries must be durably
// written to disk or if a non-durable write is permissible.
MustSync bool
}
|
etcd/raft批处理的形式一次性返回一个Ready,其中封装了经Raft package处理好的各类信息,上层拿到之后,该存储的存储,该执行的执行,该发送的发送:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| for {
select {
case <-ticker.C:
rc.node.Tick()
// store raft entries to wal, then publish over commit channel
case rd := <-rc.node.Ready():
// Must save the snapshot file and WAL snapshot entry before saving any other entries
// or hardstate to ensure that recovery after a snapshot restore is possible.
if !raft.IsEmptySnap(rd.Snapshot) {
rc.saveSnap(rd.Snapshot)
}
rc.wal.Save(rd.HardState, rd.Entries)
if !raft.IsEmptySnap(rd.Snapshot) {
rc.raftStorage.ApplySnapshot(rd.Snapshot)
rc.publishSnapshot(rd.Snapshot)
}
rc.raftStorage.Append(rd.Entries)
rc.transport.Send(rc.processMessages(rd.Messages))
applyDoneC, ok := rc.publishEntries(rc.entriesToApply(rd.CommittedEntries))
if !ok {
rc.stop()
return
}
rc.maybeTriggerSnapshot(applyDoneC)
rc.node.Advance()
case err := <-rc.transport.ErrorC:
rc.writeError(err)
return
case <-rc.stopc:
rc.stop()
return
}
}
|
状态机连接#
RaftNode的启动时,调用处会创建好节点id,集群的信息,以及proposeC, confChagneC。
proposeC由状态机和RaftNode共享,状态机那一端持有sender,将请求发送给RaftNode,RaftNode的receiver获取之后就会调用Propose方法将请求转发给下层去完成共识,在 newRaftNode 当中,会创建一个commitC,来从下层获取提交的日志,之后这个channel也会返回给状态机,此时完成了RaftNode和状态机的双向连通。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| func newRaftNode(id int, peers []string, join bool, getSnapshot func() ([]byte, error), proposeC <-chan string,
confChangeC <-chan raftpb.ConfChange) (<-chan *commit, <-chan error, <-chan *snap.Snapshotter) {
commitC := make(chan *commit)
errorC := make(chan error)
rc := &raftNode{
proposeC: proposeC,
confChangeC: confChangeC,
commitC: commitC,
errorC: errorC,
id: id,
peers: peers,
join: join,
waldir: fmt.Sprintf("raftexample-%d", id),
snapdir: fmt.Sprintf("raftexample-%d-snap", id),
getSnapshot: getSnapshot,
snapCount: defaultSnapshotCount,
stopc: make(chan struct{}),
httpstopc: make(chan struct{}),
httpdonec: make(chan struct{}),
logger: zap.NewExample(),
snapshotterReady: make(chan *snap.Snapshotter, 1),
// rest of structure populated after WAL replay
}
go rc.startRaft()
return commitC, errorC, rc.snapshotterReady
}
|
这一部分结合test中的内容会更加清晰:
- 状态机持有proposeC的sender,raftNode中持有proposeC的receiver,建立起了State Machine -> RaftNode的连接
- commitC由raftNode创建,之后传入给状态机,完成了RaftNode -> State Machine的连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| func TestPutAndGetKeyValue(t *testing.T) {
clusters := []string{"http://127.0.0.1:9021"}
proposeC := make(chan string)
defer close(proposeC)
confChangeC := make(chan raftpb.ConfChange)
defer close(confChangeC)
var kvs *kvstore
getSnapshot := func() ([]byte, error) { return kvs.getSnapshot() }
commitC, errorC, snapshotterReady := newRaftNode(1, clusters, false, getSnapshot, proposeC, confChangeC)
kvs = newKVStore(<-snapshotterReady, proposeC, commitC, errorC)
}
|
Summary#
在本章中,笔者介绍了etcd/raft的设计思想和整体架构,大致展现了etcd/raft作为一个提供raft逻辑的库,是如何运行的,但是对于etcd/raft内部的细节并未展开,一方面是关于etcd/raft,已经有了相当优秀的文章:深入浅出etcd/raft —— 0x00 引言 - 叉鸽 MrCroxx 的博客。
另一方面是,笔者写本篇文章主要目的是介绍一下如何基于etcd/raft来实现一个简单的curp算法。不过临近毕业,加上目前还在实习,短时间内大概没有时间完成更新,因此目前文章的题目定为了Etcd/raft整体架构,后续如果更新,大概会改成从《从 0.5 到 1 实现curp-q》
如果想看一个架构上与etcd/raft相同,但稍微简化一点的Raft,也可以看笔者的另一篇文章:
toydb源码阅读03-Raft - 知乎
toydb源码阅读04-Raft State Machine - 知乎