背景
动机:目前的一些容错算法或者说共识算法,无论是简单的主从结构还是Raft Paxos等,都需要两个RTT来完成,第一个RTT由Client到Primary (Leader),第二个RTT由Primary到Backup (Follower)。在同一个数据中心中,两个RTT并不会出现什么问题,但是在跨数据中心或者说跨云的情况下,多出的一个RTT就显得有点难以接受。
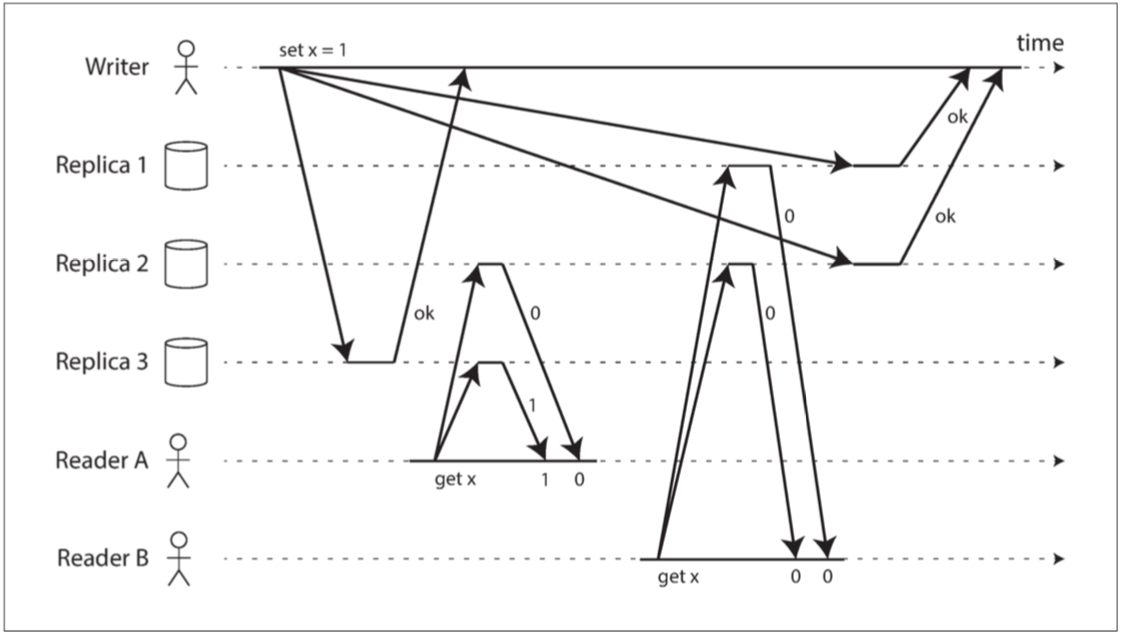
像是CockRoachDB那样面对geo-distributed的情况对Raft的配置做出一些额外的优化,但是本质上依旧逃离不了两个RTT的时间开销,quorom可以在一个RTT来完成共识,但是无法提供线性一致性(在存在不确定网络延迟时就会出现,如下图)。还有一些共识算法需要依靠特殊的网络硬件来加速,但是并不具有普适性。因此提出了CURP来解决这个问题。
先说几个CURP的特性:
CURP是非侵入性的,可以算是在主从备份的架构上外挂了一部分逻辑,因此在文中并没有并没有如何介绍主从这一部分的逻辑
CURP的提出基于这样的一个观点:首先,各个操作之间并不需要一个全局的顺序,我们只需要对存在冲突或者说互不兼容的内容之间建立一个偏序 (这里以kv进行讨论),即 set x =5 和 set x=7 之间是冲突的,这时候就需要建立一个针对该key的执行顺序,其他情况下,各个命令可以以任意顺序执行,像是set x = 5, set y =3 任意顺序执行,互不干扰。(由于网络延迟问题,key可能以不同顺序到达不同节点,如果直接执行则会得到不同的结果)
持久化与顺序分离:传统算法一般通过Primary/Leader确定一个全局的顺序,然后广播给Follower,之后Follower回应,在这个过程中完成了持久化,保证崩溃之后依旧能够恢复出来,在CURP当中将二者分离,在Witness中完成一个临时的存储(临时但持久化),但并不会记录任何的顺序信息,当冲突的时再依赖Primary确定冲突key之间的偏序,再由Primary广播给backup去执行,这样可以保证一致性顺序,但是代价是需要两个RTT,最差情况下需要三个RTT (Client -> Witness检测到冲突,Client->Primary生成顺序,Primary->Backup按序执行)
CURP
非侵入式架构
CURP本身是基于Primary-Backup架构的拓展(f+1 个节点其中一个为Primary剩下为Backup)。非侵入式的构建于普通的Primary-Backup架构之上,在此之上Witness,Primary和Backup按照原本的逻辑继续执行,即Primary执行后发送给Backup进行备份,Witness用于进行冲突检测,会记录当前还未commit的请求。Witness和Backup是两个独立的逻辑概念,Backup用于执行,Witness用于记录和检测,但是二者在构建系统时,可以构建于同一台主机之上
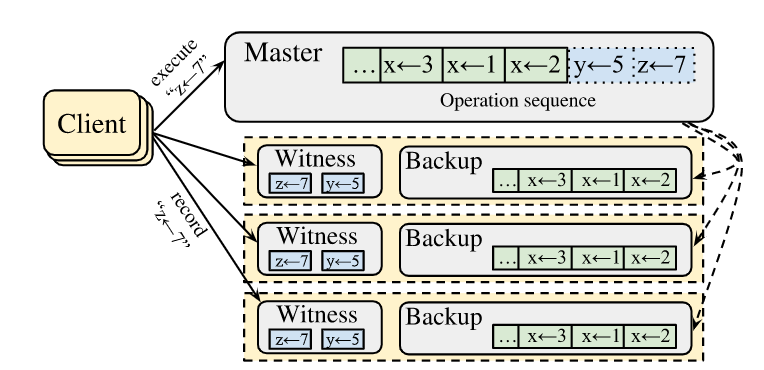
CURP提供了线性一致性和fail-stop模型,不会处理拜占庭错误
Client
Client的行为逻辑在原本与Primary通信的基础上,会并行的向Witness发送信息,Primary向Backup备份,Witness做记录,但是Primary在备份前就会向Client回复, 一旦Client接受到了f个响应,那么就可以认为此次请求完成,主备同步后续异步的完成。此次请求可以在一次RTT内完成。
如果无法收到f个正确的响应 (节点崩溃或者产生冲突被拒绝),则无法在一个RTT内完成请求,此时需要Primary介入, client通过sync rpc来通知Primary,以Primary的顺序完成执行并备份,此时需要 2 个-3 个RTT才能够完成请求。(client->primary, primary->backup为两个,client->witness,client接收到冲突之后primary还未开始进行同步,那么除了client->witness,还需要额外的client->primary, primary->backup共三个RTT)。


在实际的实现上,可以选择同时开启fast path和slow path,即同时进行propose和wait_synced,这样的好处是可以保证在最差的情况下, 2RTT也可以解决,即可以省略掉client向primary发送 sync rpc的这个步骤,最差的情况下,只需要client同时发送propose和wait_synced,client与wait_synced之间存在一个RTT,primary和backup进行同步时存在一个RTT,wait_synced等到主从同步完成即可返回,但是代价是client需要时刻向server发送两个请求 (wait_synced的结果在fast path可以得到结果时可以忽略)。
Witness
Witness 支持 3 个基本操作:记录响应客户端请求,保存直到被告知丢弃,以及在recovery时提供存储的数据。并且各个Witness之间独立工作无需进行通信。
Witness的记录并不提供顺序,仅记录请求本身,然后做冲突检测,Witness中的内容需要持久化保存,以用于进行recovery,但是又仅需要临时保存,因此可能像是NVM会更合适一些。
对于冲突检测,类似于sql或者其他的原生请求很难判断出涉及到的数据的冲突,因此,将这个过程下推到存储层以kv的形式来处理更加合理,以kv为单位进行同步和冲突检测(即SQL构建于KV之上,类似CockroachDB或者TiDB)。
Master
CURP 中的Master接收、序列化并执行来自客户端的所有更新 RPC 请求。对于非只读请求,会向Backup进行同步,这个过程是异步的,在通过log同步数据之前会先响应Client以保证一个RTT完成请求。而如果master检测到了冲突,则必须在回复Client成功之前完成同步,此时就是 2 个RTT,此时以Synced作为结果响应Client,Client收到之后,就可以避免Client去再次发送sync rpc
Recovery
recovery比较的直观,由于数据存储在两部分上,那么恢复同样也是从两部分恢复,即首先从backup,然后是witness,在进行witness恢复时,需要保证至少f个witness在线。在整个恢复过程中,需要停止接受前台新的请求 (master和witness)。
GC
Witness仅作临时存储用于判断冲突,因此当master成功将数据同步到backup上之后,数据即可安全删除,这个动作由master通知witness来完成。
集群信息更新
对于集群信息更新,主要涉及到三部分,主动的或被动的,分别是backup宕机,witness宕机,和Primary迁移:
- 对于backup宕机,curp是非侵入式的,因此这一部分交给原本的primary-backup协议来处理
- witness宕机:configuration manger会将宕机的witness从配置中下线,然后分配一个新的witness给manager (这里引出了一个新的概念即configuration manager,但是并没有具体说明实现方式,仅仅用"the owner of all cluster configurations",究竟是单独的一个节点,还是由master担当没有详细介绍)。此时,client依旧会将信息发送到旧配置中已经下线的节点,为了解决该问题,curp引入了版本机制,即client在从configuration manager处获取到witness list时会获取到一个version,之后请求时携带上这个version,matster处同样会保存witness list和version,version会随着每次配置更新自增。master如果发现client携带了旧的version,就会拒绝,并且返回最新的witness list给client,之后client再根据最新的配置去请求。
- 数据迁移:数据迁移分为两阶段:
- 在第一阶段会继续提供服务,并且进行数据迁移
- 在第二阶段进行收尾工作,终止掉服务以便迁移所有数据,最后更新配置 为了进行简化,在第二阶段前会将当前master的数据同步到backup上,然后重置witness,之后停止服务,因此,在整个迁移过程中,witness完全不参与 (仅在第一阶段用于提供服务检测冲突),之后client也会被拒绝然后重新拉取配置 (这一部分依旧有基础的primary-backup来负责)
Backup Read
为了实现从机读,curp利用witness来避免读取到陈旧的数据,curp会选择一个就近的witness (或者同一主机上的),进行冲突检测,如果不存在冲突,那么就可以认为当前backup上的数据是最新的,可以进行读取,否则则会存在陈旧数据,需要从master处读取。
由于witness上的gc依赖于backup的sync,因此如果在witness上能找到一个冲突的key,那么就证明当前key有正在写入的其他请求,由于写backup之间存在延迟,直接从机读就会破坏针对该key的顺序,因此会违反线性一致性 (如果发现冲突,那么读取的流程就如下图:
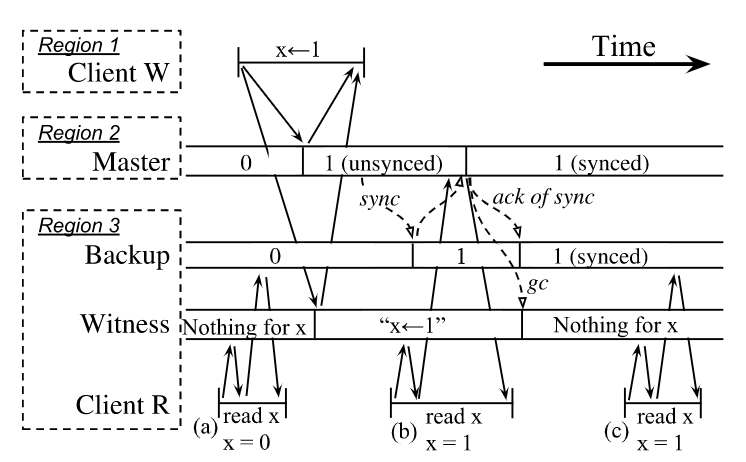
由于primary-backup架构下不存在(n +1)/2 这样的commit,需要写到所有的backup上才能够认定为commit,只有完全同步之后,才能够允许从机读,这种设置是必要的,通过witness进行冲突检测也是为了保证这个,如果违反,在两种情况下会出现问题:
- 首先从backup1 上读取到了x =1,第二次请求发送到了backup2,backup2 同步速度慢于backup1,会读取到x=0,读取到了陈旧的数据,因此需要拒绝掉第一次的读取
- master宕机恢复时同样会出现问题,client从一个进度比较新的backup上读取了数据,但是master选择从一个进度比较落后的backup恢复数据,此时再从master读取,就会读取到陈旧的数据
CURP-Q
CURP-Q作为CURP的扩展,在CURP作者的phd论文中进行了介绍,这里简单提一下。由于curp本身是非侵入式的,即然可以构建于主从架构上,那么构建于选举共识算法 (这里以Raft为例)自然也是没什么问题。
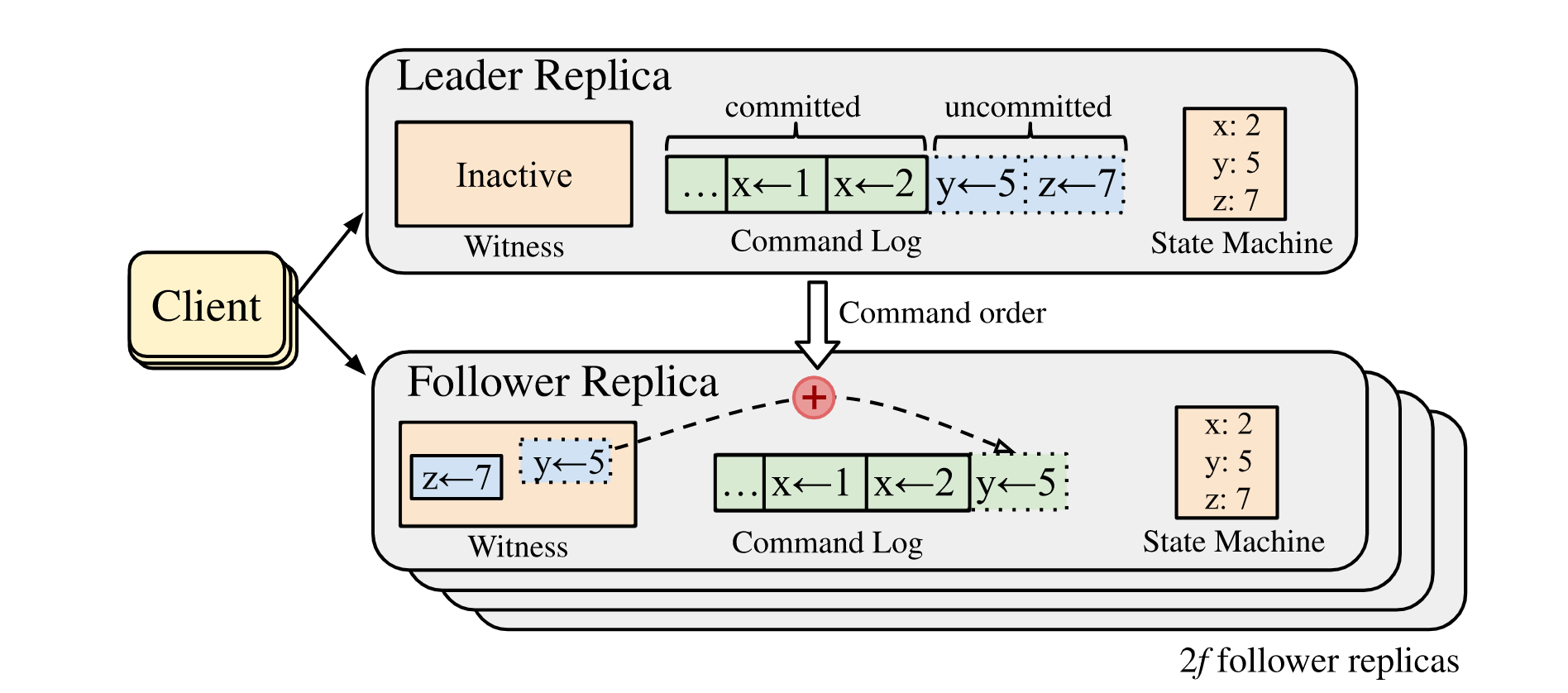
在网络正常的情况下,就走fast path,通过 witness快速在一个RTT完成,如果存在冲突,那么走slow path,借助Raft的日志来解决冲突确定顺序。各个节点的身份由Raft本身选举完成,日志复制同样可以交给Raft来完成。Witness与Follower此时构建于同一个物理主机上。
简而言之,Raft无需做任何修改,只需要按照其原本的逻辑运行,CURP-Q构建于Raft之上,根据冲突来选择是否将命令交给Raft来执行,CURP-Q的架构如下;
Summary
CURP为分布式共识算法带来了新的思考,即为了实现线性一致性,我们并不是在所有情况都需要确定一个全局顺序,对于不存在冲突的key,可以按照任意顺序执行。对于冲突的key,再选择一个可以提供线性一致性的算法来完成执行。
因此,按照这种思路,可以做一个组合,即fast path采用一个RTT能完成的算法 (2pc, quorum)等均可,slow path选择一个可以提供线性一种线性一致性保证的算法 (Primary-backup, Raft, paxos)。
实现:curp的论文代码没有开源,目前能够找到的比较好的实现就是Datenlord的Xline:GitHub - xline-kv/Xline: A geo-distributed KV store for metadata management
Xline实际选择以Raft作为线性一致性的分布式共识算法,实现了一个CURP-Q,细节上可能和论文有出入,不过架构上遵循了论文中的设计,rust异步来实现分布式,还是很值得一读的。
Discussions
正确性证明 (非正式)
在正确性证明这一部分,主要关注在宕机恢复方面的三个问题:
- 持久性:如果Client完成了一次请求,那么请求的结果在恢复后应当存在
- 一致性:Client完成了一次请求,并且得到了结果,那么在恢复后结果依旧是一致的
- 线性一致性:宕机恢复应当保证线性一致性
在证明前,重述一遍在前文中提及的规则:
- Rule1: 只有请求被所有的witness记录或者同步到所有的backup上面才能够认定为成功
- Rule2:一个完成了并且未同步的请求一定与其他未同步的请求之间是不冲突的
持久性
在恢复过程中,master会从一个backup和一个witness来读取数据,根据上述规则,要么它已经被同步,可以从backup中读取到,要么未同步,但是记录在witness当中
一致性
这里的一致性指的是恢复前后能够读取到的结果是否一致,而非线形一致性。我们将请求称为 $a$,而对于key a之前的结果称为 $H_a$。在进行宕机恢复时,共有 2 种情况:
- $a$ 已经被同步到backup:那么就可直接通过backup进行恢复,并且由于去重机制RIFL的存在,witness中还未来得及gc的内容也不会影响结果
- $a$ 还未进行同步:根据规则 2,还未同步并且请求成功,那么一定记录在witness中,并且是不冲突的,直接恢复即可,而恢复过程先恢复backup中的内容,因此backup中的 $H_a$ 会被witness中的内容覆盖,因此不会吧曾经的历史记录暴露出来
线性一致性
这里依旧分为三种情况讨论:
- 宕机前 $a$ 的结果被其他依赖 (dependent)的操作观测到,如 read a,那么根据 rule 2,$a$ 一定已经同步到 backup 上
- 通过请求 $a$ 的完成观测到结果,在崩溃之前对 $a$ 的唯一观察是返回的执行结果,并且由于一致性属性,即使在恢复之后它也必须仍然一致。即没有任何其他的相关操作
- 宕机前对于 a 的结果没有任何的观测,即 a 执行失败,那么 client 就会在恢复后进行重试,由于 RIFL 的存在,无论是 a 没有被执行,还是执行成功,没能够返回 client,结果都是一样且符合线性一致性的。
Witnesses 与 Backup 分离
这样实现的好处是可以保证代码的非侵入性,即完全不需要修改原本 backup 的代码,可以很轻易的构建在现有的系统上。
而在 backup 上实现 witness 同样也有好处,即同步过程会方便很多,master 可以只发送一个 log Id,而不是完整的请求,之后 backup 就可以根据 id 从 witness 中获取数据,减少网络发送的数据量,并且可以直接将 witness 中的数据直接移动到 backup 中,减少了一次 gc 请求。
这个实现在 CURP 的 PhD 论文中也有提及,称为 CURP-H(Hybrids)
扩展 CURP 至共识算法
即 CURP-Q(Quorum)在 PhD 论文中同样有所提及。这里简单说几个点
- 通常共识算法使用 2 f+1 个副本,以容忍 f 个宕机 (failed)的副本,在 CURP-Q 中同样适用 2 f+1 容忍 f 个副本,但这只是最低要求,即可以通过 slow path 来完成共识,如果想要通过 fast path,那么依旧需要 superquorum。如果只是简单的大多数,即将 f+1 个,在产生 f 个宕机后 (包括 Leader),那么就只有一个 Witness 中会记录请求。在进行恢复时,而如果其他 f 个接受了与之冲突的请求,那么在恢复过程中就无法分辨和确定顺序。(仅仅只是接受或者记录过,这 f 个 witness 中的内容不需要 commit,就会产生影响)
- 在发生 Leader 身份切换时,由于 Leader 的偷跑行为(Leader 不进行冲突检测,这里指 Leader 执行成功但 Wintess 没有记录成功的内容,此时该请求并未成功执行,但是结果已经写入到状态机)会导致 Leader 的状态机与其他副本有所分歧,即旧 Leader 在进度上会领先其他副本,一个比较简单的方法就是引入 checkpoint,对数据进行重新加载。但如果原本的旧 Leader 并不是因为宕机而下线,可以读取旧 Leader 的 uncommitted log,应用至新的 Leader。(这样虽然可以同步状态,但是会将一些被视为失败的结果进行成功写入?)
- 最后一个问题是 Client 如何识别出那些陈旧的,但是依旧视自己为有效的 Leader(Zombie Leader)。在 Raft 和 Paxos 中是不存在这个问题的,因为 Leader 的请求需要 Follower 的确认,在 CURP 中,虽然 slow path 中同样存在这个过程,Leader 最终也会退位,但是 Fast path 是广播形式,Leader 与 Witness 相互独立,无法进行检测。因此,需要引入一个 Term 机制,通过 Witness 的回复 RPC,Client 可以判断当前的 Leader 是否为有效 Leader