Intro#
什么是CURP#
Curp是一种新的分布式共识算法,curp的提出是针对于跨域等高网络延迟场景,传统的raft和paxos等共识算法需要两个RTT,在高网络延迟的场景下,两个RTT对系统来说是难以忍受的,网络通信会成为系统的瓶颈。
为了解决该问题,CURP期望在大多数情况下,通过一个RTT来完成,这主要基于两点背景:
- 在请求中,各个请求之间通常是互不冲突的,例如 set a =1 和 set b = 2, 对于同一个key的重复性读写是比较少见的
- 系统并不需要对所有请求建立一个全局的顺序,相对的,只需要对于互相冲突的key建立起一个局部顺序即可
如果想进一步了解CURP,欢迎阅读笔者的另一篇文章:
zhuanlan.zhihu.com/p/692464275
为什么是从 0.5 到 1#
CURP是非侵入性的,即curp只是在原本的共识系统的基础上,提供一套额外的逻辑,来加速原本的共识算法,在curp原文中,选择的是使用primary-backup架构来作为基础,而在CURP作者在phD论文中,扩展了CURP,提出了CURP-Q,其构建于如Raft,Paxos等Leader-Follower共识算法上。
而etcd/raft是目前工业界比较成熟的raft实现,其将raft抽象成状态机,非常地简单易用。同时,其实现了如check quorum, leader lease prevote 批处理,流水线发送了等优化,性能有基础保证。因此,在本文中,笔者选择了etcd/raft,充当CURP的slow path,再次基础上,构建了CURP。
CURP Server#
ectd/raft以及如何与raft交互已经在上一章阐述,因此在这里将重点放在CURP Server的状态机上。CURP状态机的设计参考了 6.824 和 Xline。状态机负责接收网络请求,与client完成交互。随后将其发送给raft完成propose,同时CURP状态机还要维护一个kv store,存储已经commit的内容。
状态机定义如下,主要包括:
- KVStore:存储已经commit的内容,这里选择了boltdb作为持久化实现
- Witness:CURP的重要机制,在follower上运作,用于暂存未提交的请求以进行冲突检测,由于没有实现recovery,因此这里直接使用map存储
- CommandBoard:记录目前接收到的请求,并在适当的时机响应Client结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| type StateMachine struct {
NodeId int
proposeC chan<- string // channel for proposing updates
mu sync.RWMutex
// kvStore map[string]string // current committed key-value pairs
KVStore *xkv.KVStore
commandBoard *command.CommandBoard
snapshotter *snap.Snapshotter
raftState raft.StateType
fastPath chan *curp_proto.CurpClientCommand
slowPath chan *curp_proto.CurpClientCommand
// both fast and slow path will execute commands,this set is used to avoid executing the same command twice
commandSet map[command.ProposeId]struct{}
witness witness.Witness
stateChangeC chan raft.StateType
}
|
Witness#
Witness机制是CURP的核心,用于提供冲突检测功能,这里的实现非常简单,仅仅只使用map存储+Mutex并发控制,定义如下:
1
2
3
4
| type Witness struct {
mu sync.Mutex
commandMap map[string]map[command.ProposeId]*curp_proto.CurpClientCommand
}
|
目前实现的冲突检测的策略非常简单,仅支持kv层面,即对于同一条key,写-写和读-写这两种情况是冲突的,在插入一条记录时,如果检测到冲突,那么就直接返回false,否则将其保存到map当中。
Witness中的数据应当进行持久化保存,以用于在宕机后恢复数据,由于Witness中数据是暂存的,在commit之后就会删除,因此curp原文中提出了存储在NVM等硬件上会更合适。这里由于暂时没有实现recovery机制,所以目前是直接使用map存储。
CommandBoard#
CmdBoard的作用为记录接收到的请求,等待请求执行完成,而具体的执行则交给 CommandWorker 来完成,前台接收请求的线程只需要通过CommandBoard来获取结果,并结果响应给客户端。不过由于CURP存在fast path和slow path的概念,因此会稍微复杂一些,定义如下:
1
2
3
4
5
6
7
8
9
10
11
| type CommandBoard struct {
mu sync.Mutex
// store all notifiers for execution results
erNotifiers map[ProposeId]chan string
// store all notifiers for after sync results
asrNotifiers map[ProposeId]chan struct{}
erBuffer map[ProposeId]string
asrBuffer map[ProposeId]struct{}
}
|
er 为 execution result,asr 即为 async execution result,分别代表fast path和slow path的执行结果。
请求通过 ProposeId 来标识,ProposeId 为 ClientId 和 SeqId 的组合,以区分不同Client的不同请求:
1
2
3
4
| type ProposeId struct {
ClientId uint64
SeqId uint64
}
|
leader在通过fast path执行请求,在接收到请求后,会通过 WaitForEr() 来等待fast path的执行结果,在 WaitForEr() 中,涉及到erBuffer和erNotifiers。erBuffer用于缓存命令的执行结果,经fast path完成执行的内容都会存储到其中,而erNotifiers则存储一个channel,前台监听该channel,等待执行结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| func (c *CommandBoard) WaitForEr(id ProposeId) string {
c.mu.Lock()
if result, ok := c.erBuffer[id]; ok {
c.mu.Unlock()
return result
}
if _, ok := c.erNotifiers[id]; !ok {
c.erNotifiers[id] = make(chan string, 1)
}
notifyChan := c.erNotifiers[id]
c.mu.Unlock()
result := <-notifyChan
c.erBuffer[id] = result
return result
}
|
WaitForAsr 用于等待command在slow path中完成共识,返回执行的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| func (c *CommandBoard) WaitForAsr(id ProposeId) string {
c.mu.Lock()
defer c.mu.Unlock()
//trace.Trace(trace.Client, "Wait Synced [clientId: %d,seqId: %d]", id.ClientId, id.SeqId)
_, asrOk := c.asrBuffer[id]
result, erOk := c.erBuffer[id]
defer delete(c.asrBuffer, id)
defer delete(c.erBuffer, id)
// command has already been executed in both fast path and slow path
if asrOk && erOk {
return result
}
if _, ok := c.asrNotifiers[id]; !ok {
c.asrNotifiers[id] = make(chan struct{}, 1)
}
notifyChan := c.asrNotifiers[id]
// release lock and wait
c.mu.Unlock()
<-notifyChan
c.mu.Lock()
if result, ok := c.erBuffer[id]; ok {
return result
}
// UNREACHABLE
return "NOT FOUND IN BUFFER"
}
|
Why Buffer#
在 6.824 中,执行结果通过一个channel即可传递,但是这里额外使用一个Buffer主要是用于兼容slow path,来保证线性一致性。er和asr都引入了buffer,二者需要分开讨论
首先说明一下为什么需要 erBuffer 。设想这样一个场景:client1 先 cmd1 set a = 1,随后client 1 发送 cmd 2 get a,此时被witness检测到冲突,需等待slow path执行完毕,此时,client 1 又发送了 cmd 3 set a = 3,由于leader上Witness是关闭的,set a = 3 可以直接执行,这会导致cmd3 在cmd2 之前被执行,对于client而言,观测到的结果与发送顺序不一致。
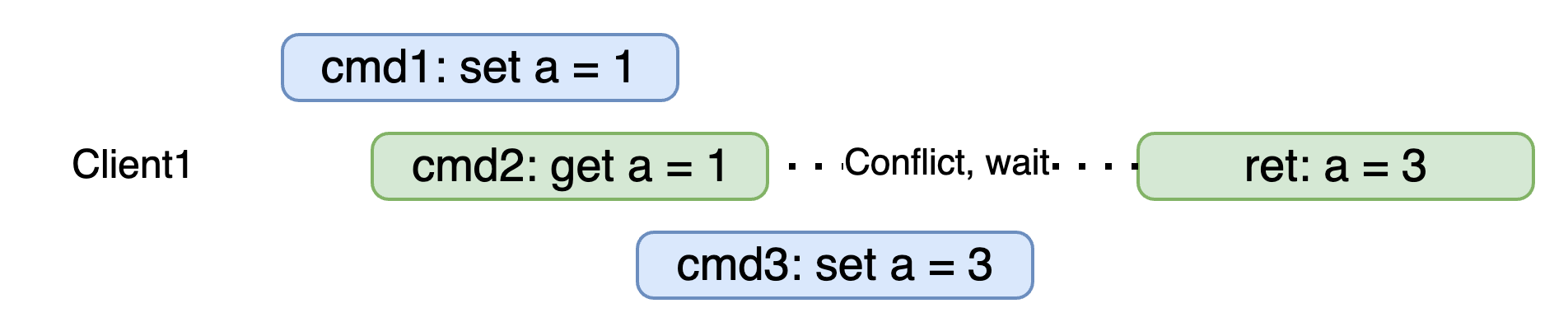
因此,cmd2 不能等待从slow path中commit才执行,而是应当在fast path中执行完成,保存结果,等到对应的日志commit之后,再将该结果返回给client。
对于不同的client来说,即cmd1 cmd3 由client 1 发送,cmd2 由client 2 发送,此时cmd2 和cmd3 处于一种并发的状态,是允许以任意的结果完成执行的,但是如果只有一个client,则会违背线性一致性。
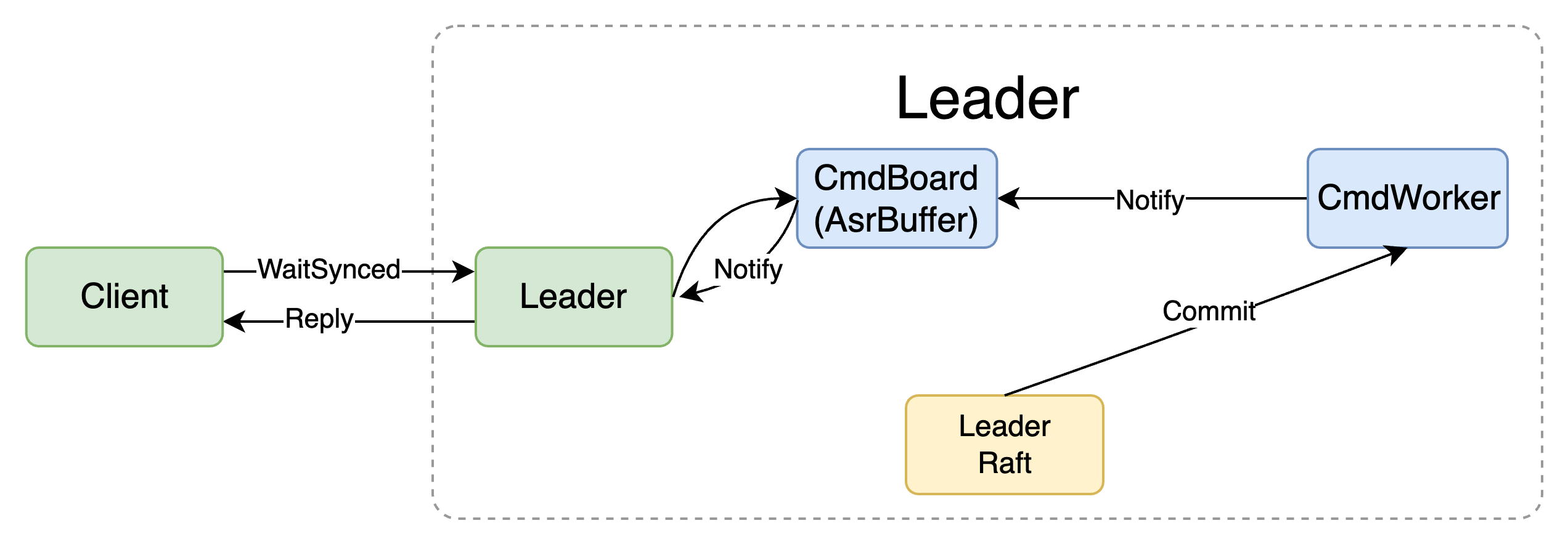
而 AsrBuffer 主要是用于解决slow path的异步执行问题,如果后台raft commit的效率比较高,那么会导致在client调用WaitSynced之前就已经commit完毕,此时如果创建一个channel并监听,那么后续就会永远无法接收到结果。
对于这个问题,有两个解决方案,一是遍历当前commit id前所有对应的channel,全部通知一遍,二就是添加一个缓存,可以通过先查询buffer来判断是否执行完成,如果没有,后续再通过channel监听结果。buffer当中只需要存储一个空struct{},起到通知作用即可。个人认为第一种实现方式优雅一些,因此就引入了buffer。
Command Worker#
与Command Board相对应的是Command Worker,Command Board记录请求,Worker负责具体的执行。
Command Worker中会分别从fast path和slow path中接收请求:
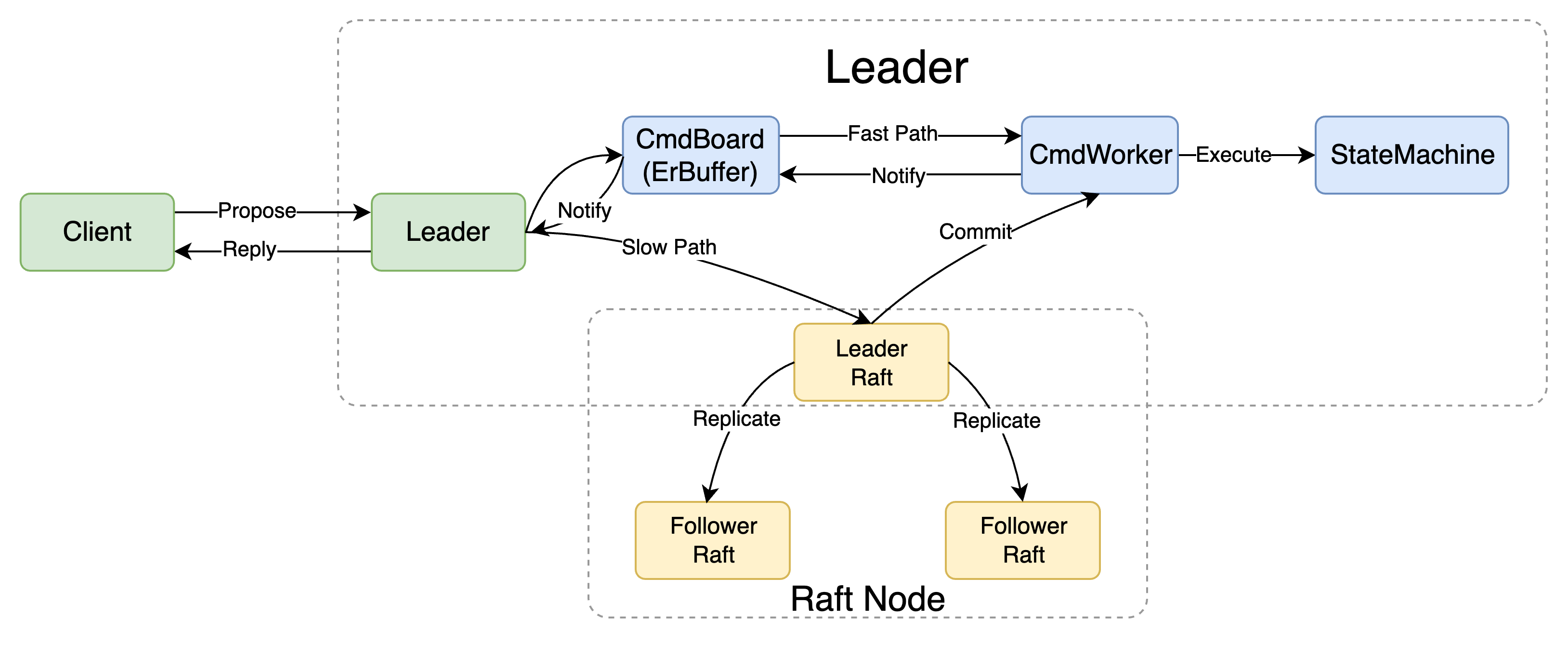
leader在接收到请求之后,会直接将其通过fast path channel发送至cmd worker处,follower只进行witness不执行,因此不会从fast path中接收任何内容。leader执行完成之后就可以通过 InsertEr 将结果添加到Command Board当中,通知前台返回结果给client
raft会将已经commit了的请求通过slow path发送至cmd worker。由于leader已经通过fast path执行过一次了,因此leader在这里应当忽略掉该请求,而follower应当执行来跟随leader的状态。
这一部分与传统raft最大的不同就是:leader会通过fast path进行“抢跑”,从而给系统引入了额外的复杂度:
Leader通过fast path提前执行,修改了状态机,但是由于witness机制的存在,这个执行结果在commit之前是不会暴露给client的。
Leader提前修改了状态机,那么slow path中的内容就无需再执行一遍,额外写一遍kv store的开销比较高。如果slow path会再执行一遍,虽然可能会导致fast path和slow path的内容相互覆盖,但是由于冲突检测的机制存在,相互覆盖的中间态不会对外暴露,因此执行一遍slow也不会影响正确性,等到commit后,状态机与只执行fast无异。Leader通过fast path已经完成了持久化,因此Leader也不会依赖raft log来完成recovery。
Follower没有额外的动作,只需要witness判断冲突,并且通过slow path来跟随leader的状态即可。
此外还有一个CommandSet,用于对命令进行去重,防止已经执行过一遍,但是没来及响应client,宕机,随后client又重试,导致命令被重复执行。在 6.824 的lab3 中,需要这样一个设计是因为其中的append命令是不幂等的,即会在原有value的基础上追加数据,而如果将命令设计成幂等的,就不需要这个CommandSet了,命令重复执行也不会产生负面影响。
Command Worker是单线程执行的,以确保线性一致性。但实际上,正如CURP本身的思想——全局顺序是不必要的,可以将全局顺序缩小范围到存在冲突的key之间维护一个顺序。在实现上可以维护多个worker,将存在冲突的key分配至同一个worker处,确保能够按照顺序来执行。不同worker之间由于不存在冲突,可以并行执行。
此外,由于kvstore和commandSet只会在这里修改,加上其为单线程,因此这里完全可以不加锁执行,临界区仅仅只有判断当前节点状态
这里的实现可以参考Xline,其中实现了一个非常完备的冲突检测队列 + worker:zhuanlan.zhihu.com/p/662504235
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| func (s *StateMachine) cmdWorker() {
for {
select {
case cmd := <-s.fastPath:
trace.Trace(trace.Fast, s.NodeId, "got cmd from fast path %v", cmd)
proposeId := command.ProposeId{
ClientId: cmd.ClientId,
SeqId: cmd.SeqId,
}
if _, ok := s.commandSet[proposeId]; ok {
// command executed before,nothing to do
trace.Trace(trace.Fast, s.NodeId, "cmd already executed %v", cmd)
} else {
s.commandSet[proposeId] = struct{}{}
result := s.execute(cmd)
trace.Trace(trace.Fast, s.NodeId, "cmd %v executed,result is %v", cmd, result)
s.commandBoard.InsertEr(proposeId, result)
}
case cmd := <-s.slowPath:
s.mu.Lock()
isLeader := s.raftState == raft.StateLeader
s.mu.Unlock()
trace.Trace(trace.Slow, s.NodeId, "got cmd from slow path %v", cmd)
if _, ok := s.commandSet[cmd.ProposeId()]; ok || isLeader {
// command executed before,nothing to do
trace.Trace(trace.Slow, s.NodeId, "cmd already executed %v", cmd)
} else {
s.commandSet[cmd.ProposeId()] = struct{}{}
s.execute(cmd)
}
trace.Trace(trace.Slow, s.NodeId, "WAIT Notify result in slow path,proposeId:[clientId: %d,seqId: %d]", cmd.ClientId, cmd.SeqId)
s.commandBoard.NotifyAsr(cmd.ProposeId())
trace.Trace(trace.Slow, s.NodeId, "Notify result in slow path,proposeId:[clientId: %d,seqId: %d]", cmd.ClientId, cmd.SeqId)
// when command is committed, it can be remove from witness and command set safely
s.removeRecord(cmd.ProposeId())
}
}
}
// we don't need to lock this function,because it's the only func which modifies KVStore
func (s *StateMachine) execute(cmd *curp_proto.CurpClientCommand) string {
if cmd.Op == command.PUT {
s.KVStore.Put(cmd.Key, cmd.Value)
} else if cmd.Op == command.DELETE {
s.KVStore.Delete(cmd.Key)
} else if cmd.Op == command.GET {
result, err := s.KVStore.Get(cmd.Key)
if err != nil {
return "NOT FOUND IN STATE"
} else {
return result
}
}
// unreachable!
return ""
}
|
Fast Path#
在分析完Command Board和Command Worker之后,就可以串通CURP的fast path和slow path的全流程了。
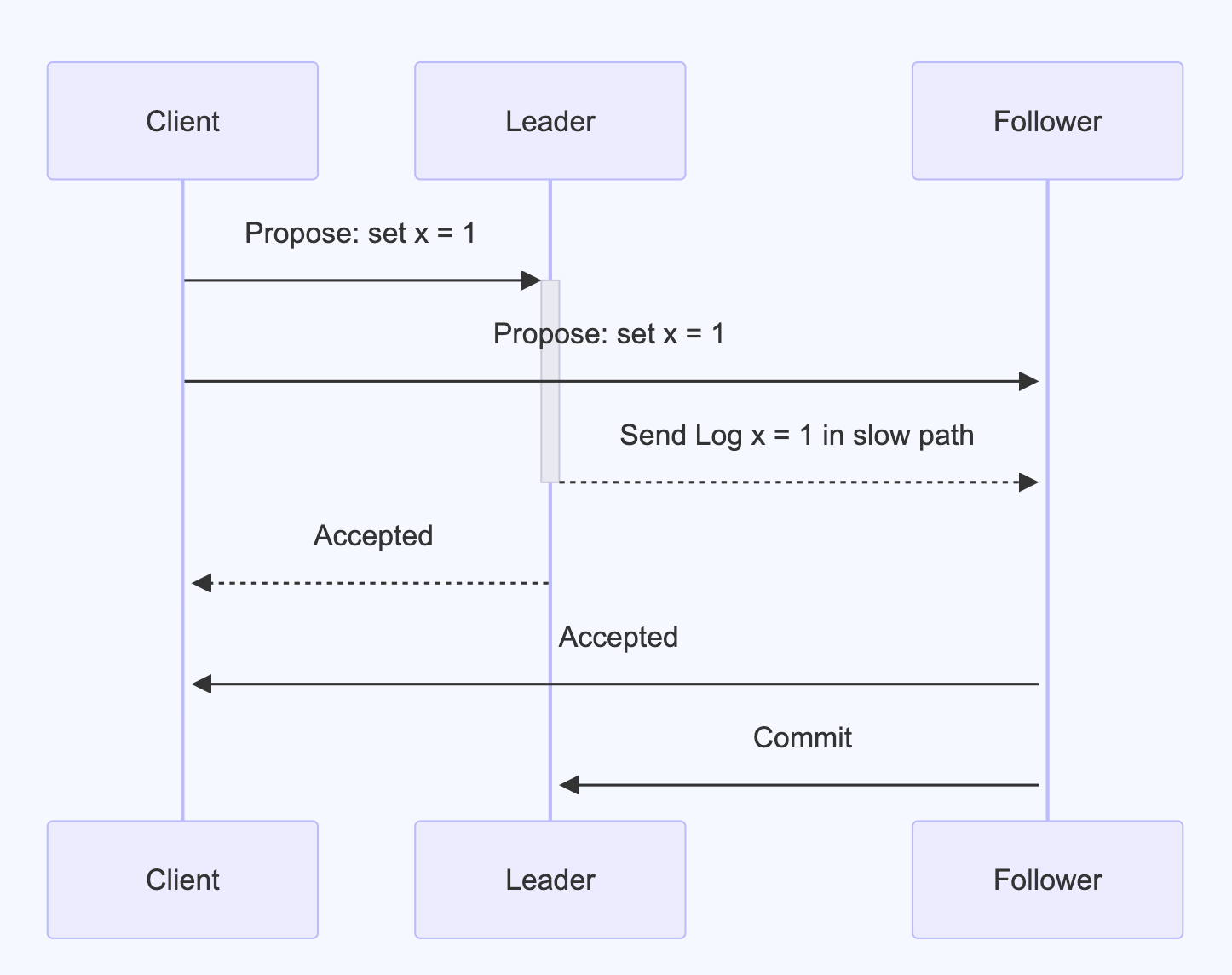
fast path通过 Propose () 完成,无论读写请求都会被封装成一个ClientCommand,随后调用 Propose() ,流程如下:
- 首先进行冲突检测,将请求添加到Witness当中,并且返回是否冲突
- follower在fast path中只起到witness作用。如果当前节点非Leader,那么此时就可以返回了,响应CONFLICT或者ACCEPT
- 对于Leader后续应当直接继续执行,通过fast path的channel将cmd交给 cmd worker,并通过proposeC将cmd传递给raft
- 通过CommandBoard等待结果,响应给Client
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| func (s *StateMachine) Propose(cmd *curp_proto.CurpClientCommand) *curp_proto.CurpReply {
isConflict := s.witness.InsertIfNotConflict(cmd)
s.mu.Lock()
if s.raftState == raft.StateLeader {
trace.Trace(trace.Leader, s.NodeId, "propose command %s,type: %s,conflict: %v", cmd.Key, command.OpFmt[cmd.Op], isConflict)
} else {
trace.Trace(trace.Follower, s.NodeId, "propose command %s,type: %s,conflict: %v", cmd.Key, command.OpFmt[cmd.Op], isConflict)
}
reply := &curp_proto.CurpReply{
Content: "",
}
if s.raftState != raft.StateLeader {
if isConflict {
s.mu.Unlock()
reply.StatusCode = curp_proto.CONFLICT
return reply
} else {
s.mu.Unlock()
reply.StatusCode = curp_proto.ACCEPTED
return reply
}
}
buf := cmd.Encode()
go func() {
s.fastPath <- cmd
}()
// command will update the state machine or get command is conflict
trace.Trace(trace.Leader, s.NodeId, "send propose[clientId:%d seqId: %d] msg to raft node", cmd.ClientId, cmd.SeqId)
go func() {
s.proposeC <- buf
}()
s.mu.Unlock()
proposeId := command.ProposeId{
ClientId: cmd.ClientId,
SeqId: cmd.SeqId,
}
result := s.commandBoard.WaitForEr(proposeId)
reply.Content = result
if isConflict {
reply.StatusCode = curp_proto.CONFLICT
} else {
reply.StatusCode = curp_proto.ACCEPTED
}
return reply
}
|
这里有一个细节,在CURP-Q的论文当中描述:Leader的witness应当是关闭的,即Leader并不进行冲突检测,对于所有请求都直接执行,但是在Xline的实现中,Leader是启动了Witness并进行冲突检测的。对于这个细节,个人认为并不会对并不会对系统正确性产生影响,暂时没有深究。
Witnesses in leaders are inactive, and all client requests are serialized and logged in their command logs directly.
Slow Path#
Slow Path的入口很简单,只需要调用 WaitForAsr() 来等待commit即可,通过 WaitSynced() 来实现
1
2
3
4
5
6
7
8
9
10
11
| func (s *StateMachine) WaitSynced(id command.ProposeId) *curp_proto.CurpReply {
// only send wait synced message to leader
trace.Trace(trace.Leader, s.NodeId, "got wait synced message: %v", id)
result := s.commandBoard.WaitForAsr(id)
reply := &curp_proto.CurpReply{
Content: result,
StatusCode: curp_proto.ACCEPTED,
}
trace.Trace(trace.Leader, s.NodeId, "wait synced finished,id: %v,result: %v", id, result)
return reply
}
|
在Fast Path中,Leader会通过proposeC发送给Raft,此时就相当于进入了Slow Path,在Raft中,完成共识的cmd会通过Ready返回,经RaftNode转手又通过commitC发送会了状态机,状态机收到之后,对cmd进行decode,随机通过slow path channel又将请求发送给了cmd worker
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| func (s *StateMachine) readCommits(commitC <-chan *commit, errorC <-chan error) {
for commit := range commitC {
if commit == nil {
// signaled to load snapshot
snapshot, err := s.loadSnapshot()
if err != nil {
log.Panic(err)
}
if snapshot != nil {
log.Printf("loading snapshot at term %d and index %d", snapshot.Metadata.Term, snapshot.Metadata.Index)
if err := s.recoverFromSnapshot(snapshot.Data); err != nil {
log.Panic(err)
}
}
continue
}
for _, data := range commit.data {
var cmd curp_proto.CurpClientCommand
dec := gob.NewDecoder(bytes.NewBufferString(data))
if err := dec.Decode(&cmd); err != nil {
log.Fatalf("raftexample: could not decode message (%v)", err)
}
s.slowPath <- &cmd
}
close(commit.applyDoneC)
}
if err, ok := <-errorC; ok {
log.Fatal(err)
}
}
|
之后就是cmd worker的逻辑了,在上面已经分析过了,这里简要整合一下。对于leader而言,直接忽略slow path中的内容,以免内容覆盖影响线性一致性。而对于follower而言,直接应用以跟随Leader。slow path执行完成,即可认定其为commit,此时可以通过 NotifyAsr 获取执行结果,并通知 WaitSynced 结束阻塞。
CURP Client#
对应地,在CURP Client端也分为了fast path和slow path,均通过grpc实现,此外,还需要一个isLeader来确定server中的leader,以确定应当向谁发送 WaitSynced()。
Fast path#
在fast path中,client需要做的就是将请求广播给所有的server,然后监听统计结果:
- 如果响应结果中存在冲突,那么就返回冲突,后续转向slow round
- 如果达到了superquorum (f个节点,对应为f + f / 2 + 1,即 4 节点需要 3 个,3 节点需要 3个 ),就返回请求成功
- 超时检测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| func (c *GrpcClient) fastRound(cmd *curp_proto.CurpClientCommand, notifyC []chan *curp_proto.CurpReply) (*curp_proto.CurpReply, error) {
timeout := time.NewTicker(time.Second * 5)
fastPathChan := make(chan *curp_proto.CurpReply)
for i := 0; i < len(c.grpc_servers); i++ {
go func(i int) {
c.sendC[i] <- cmd
result := <-notifyC[i]
fastPathChan <- result
}(i)
}
acceptedCount := 0
result := &curp_proto.CurpReply{
StatusCode: curp_proto.TIMEOUT,
Content: "",
}
for {
select {
case fastResult := <-fastPathChan:
trace.Trace(trace.Client, -1, "client receive fast path result: %v", fastResult)
if fastResult.StatusCode == curp_proto.ACCEPTED {
acceptedCount++
if fastResult.Content != "" {
result = fastResult
}
} else {
return fastResult, nil
}
if acceptedCount == c.superQuorum() {
return result, nil
}
case <-timeout.C:
fmt.Printf("timeout !!\n")
return result, fmt.Errorf("fast path time out")
}
}
}
|
slow path#
slow path比较简单,只需要将请求发送给Leader即可
1
2
3
4
5
6
7
8
9
10
11
| func (c *GrpcClient) slowRound(cmd *curp_proto.CurpClientCommand, notifyC []chan *curp_proto.CurpReply) (string, error) {
sync_cmd := &curp_proto.CurpClientCommand{ClientId: cmd.ClientId, SeqId: cmd.SeqId, Sync: 1}
c.sendC[c.LeaderId] <- sync_cmd
reply := <-notifyC[c.LeaderId]
trace.Trace(trace.Client, -1, "client wait synced finished, id: %v", cmd.ProposeId)
if reply.StatusCode == curp_proto.CONFLICT {
return "", fmt.Errorf("command is still conflict after wait synced")
}
return reply.Content, nil
}
|
随后,将fast path和slow path做一个整合,封装成 Propose() ,在 Propose() 中:
- 首先调用
fast_round() ,将请求进行广播,如果不存在冲突,那么就可以直接返回,代表此次请求在 1 个RTT内结束 - 如果
fast_round() 中存在冲突,那么再调用 slow_round(),通过 server对 Waitsynced() 来等待commit,解决冲突
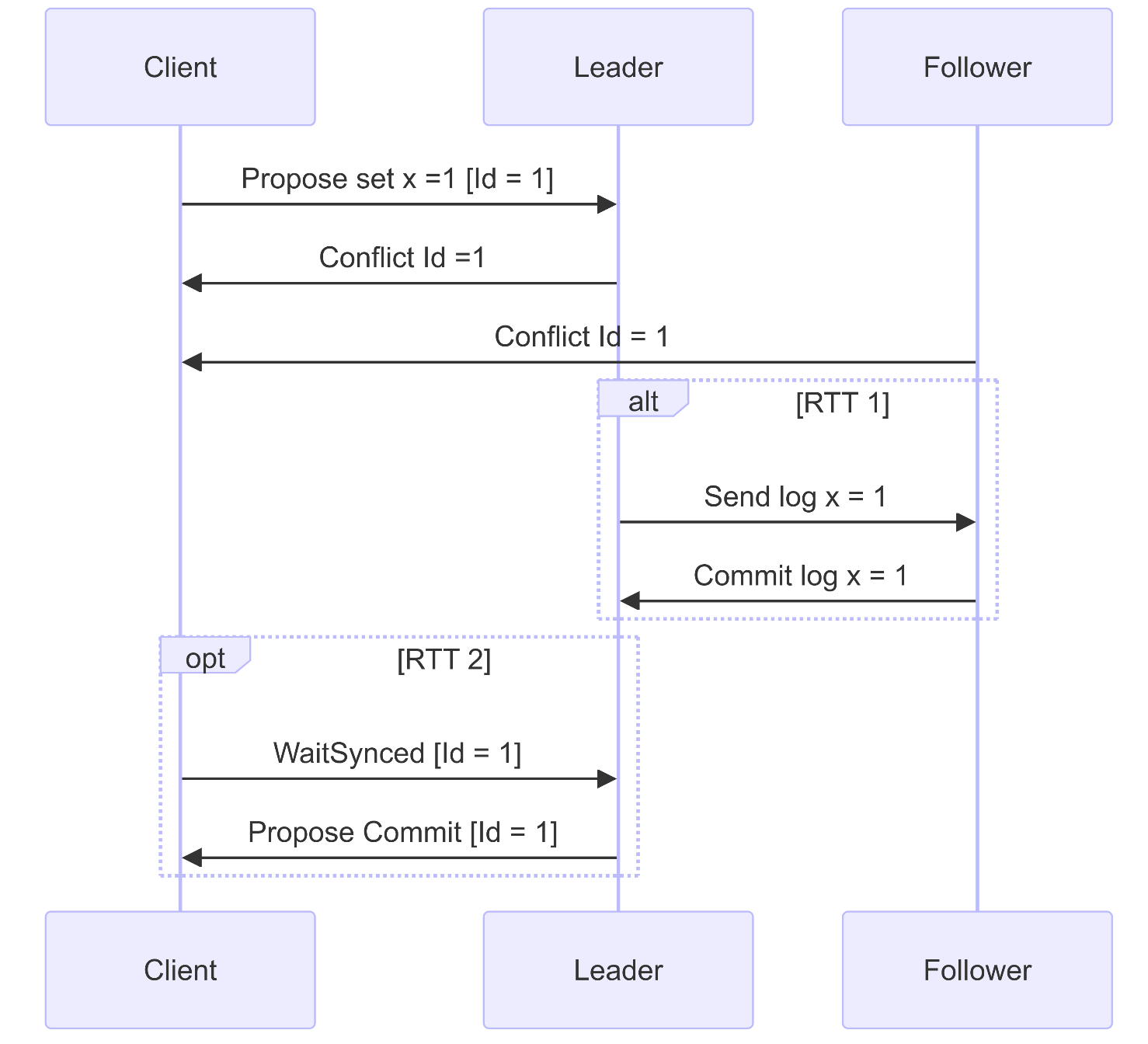
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| func (c *GrpcClient) Propose(cmd *curp_proto.CurpClientCommand) (string, error) {
ntfC := c.NewNotifyC(cmd.SeqId)
defer c.DeleteNotifyC(cmd.SeqId)
reply, err := c.fastRound(cmd, ntfC)
if err != nil {
return "", err
}
if reply.StatusCode == curp_proto.ACCEPTED {
c.static.fast++
return reply.Content, nil
}
c.static.slow++
trace.Trace(trace.Client, -1, "client receive conflict result, turn to slow path: %v", reply)
resultStr, err := c.slowRound(cmd, ntfC)
return resultStr, err
}
|
这里有一个小的优化,即可以同时发送fast round和slow round请求,这样可以更快地获取WaitSynced的结果。
benchmark#
这里使用benchmark对curp的性能做了一个简单的测试,选择的是比较通用的go-ycsb,借用了一下go-ycsb的加载数据和统计结果的功能,然后自己通过tcp为curp实现了一个server,然后在ycsb中实现了一个client,这样就可以把请求从ycsb成功发送到curp了。
这里实现的确实是比较草率,但是你就说能不能用吧😀
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| type GetResponse struct {
Count int64
Kvs []*Command
}
func (r *GetResponse) Encode() []byte {
buf := &bytes.Buffer{}
enc := gob.NewEncoder(buf)
err := enc.Encode(r)
if err != nil {
fmt.Println("encode error:", err)
}
return buf.Bytes()
}
const (
GET uint8 = iota
PUT
DELETE
)
type Command struct {
Op uint8
Key string
Value string
}
func bench_server(port string, client *curp.GrpcClient) {
listener, err := net.Listen("tcp", port)
if err != nil {
fmt.Println("Error listening:", err.Error())
os.Exit(1)
}
defer listener.Close()
fmt.Printf("Server is listening on :%v\n", port)
for {
conn, err := listener.Accept()
if err != nil {
fmt.Println("Error accepting: ", err.Error())
os.Exit(1)
}
go handleRequest(conn, client)
}
}
func handleRequest(conn net.Conn, client *curp.GrpcClient) {
buf := make([]byte, 4096)
n, _ := conn.Read(buf)
aCmd := &Command{}
dec := gob.NewDecoder(bytes.NewReader(buf[:n]))
err := dec.Decode(aCmd)
if err != nil {
fmt.Println(err)
return
}
// fmt.Printf("Received: %+v\n", aCmd)
if aCmd.Op == GET {
// call client.get
key := aCmd.Key
// value := "myValue"
value, _ := client.Get(aCmd.Key)
cmd := Command{
Op: GET,
Key: key,
Value: value,
}
cmds := []*Command{&cmd}
resp := GetResponse{
Count: 1,
Kvs: cmds,
}
buf := resp.Encode()
conn.Write(buf)
} else if aCmd.Op == PUT {
// call client.put
client.Put(aCmd.Key, aCmd.Value)
conn.Write([]byte("Received PUT Response!"))
} else if aCmd.Op == DELETE {
// call client.delete
client.Del(aCmd.Key)
conn.Write([]byte("Received DELETE Response!"))
}
}
|
跑了一个简单的benchmark,由于没有实现scan操作,因此就只选择了ycsb中的workload a-b-c,其中workloada为 50%read 50%write,workloadb为 95%read 5% write,workloadc 100% read,。
可以看到无论是哪个workload,curp的性能均好于raft,对于a,大约是个 20-30%的提升,b, c由于主要是读请求为主,curp中只需要一轮rtt加查询状态机即可,而raft需要走一遍日志复制+查询状态机,因此差距被进一步拉大(这里二者都没有开启线性一致性读优化的,即lease read或read index)
这个benchmark是在单机上跑的,如果真正到了跨域的高网络延迟的场景下,差距会被进一步的拉大
| curp | raft |
|---|
| workload a | 5.2s | 6.7s |
| workload b | 1.2s | 4.4s |
| wrokload c | 0.6s | 4.1s
|
go-ycsb的详细结果如下:
CURP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| workloada
READ - Takes(s): 5.2, Count: 488, OPS: 94.2, Avg(us): 600, Min(us): 433, Max(us): 25103, 50th(us): 534, 90th(us): 612, 95th(us): 652, 99th(us): 948, 99.9th(us): 25103, 99.99th(us): 25103
TOTAL - Takes(s): 5.2, Count: 1000, OPS: 192.8, Avg(us): 5185, Min(us): 433, Max(us): 52991, 50th(us): 6859, 90th(us): 11503, 95th(us): 12847, 99th(us): 16559, 99.9th(us): 27471, 99.99th(us): 52991
UPDATE - Takes(s): 5.2, Count: 512, OPS: 98.7, Avg(us): 9556, Min(us): 5396, Max(us): 52991, 50th(us): 8703, 90th(us): 12823, 95th(us): 14599, 99th(us): 18991, 99.9th(us): 27471, 99.99th(us): 52991
workloadb
Run finished, takes 1.198906187s
READ - Takes(s): 1.2, Count: 950, OPS: 793.1, Avg(us): 567, Min(us): 304, Max(us): 43807, 50th(us): 507, 90th(us): 582, 95th(us): 640, 99th(us): 1156, 99.9th(us): 1788, 99.99th(us): 43807
TOTAL - Takes(s): 1.2, Count: 1000, OPS: 834.4, Avg(us): 1192, Min(us): 304, Max(us): 43807, 50th(us): 511, 90th(us): 631, 95th(us): 6403, 99th(us): 15151, 99.9th(us): 20879, 99.99th(us): 43807
UPDATE - Takes(s): 1.1, Count: 50, OPS: 43.9, Avg(us): 13067, Min(us): 6400, Max(us): 20879, 50th(us): 13175, 90th(us): 15527, 95th(us): 16767, 99th(us): 20879, 99.9th(us): 20879, 99.99th(us): 20879
workloadc
Run finished, takes 596.022766ms
READ - Takes(s): 0.6, Count: 1000, OPS: 1680.6, Avg(us): 590, Min(us): 313, Max(us): 60863, 50th(us): 511, 90th(us): 614, 95th(us): 682, 99th(us): 1099, 99.9th(us): 1634, 99.99th(us): 60863
TOTAL - Takes(s): 0.6, Count: 1000, OPS: 1680.0, Avg(us): 590, Min(us): 313, Max(us): 60863, 50th(us): 511, 90th(us): 614, 95th(us): 682, 99th(us): 1099, 99.9th(us): 1634, 99.99th(us): 60863
|
Raft
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| workloada
Run finished, takes 6.741194029s
READ - Takes(s): 6.7, Count: 490, OPS: 72.8, Avg(us): 4182, Min(us): 3188, Max(us): 25279, 50th(us): 3571, 90th(us): 4787, 95th(us): 7699, 99th(us): 12015, 99.9th(us): 25279, 99.99th(us): 25279
TOTAL - Takes(s): 6.7, Count: 1000, OPS: 148.7, Avg(us): 6733, Min(us): 3188, Max(us): 42047, 50th(us): 7979, 90th(us): 9599, 95th(us): 12111, 99th(us): 17407, 99.9th(us): 25279, 99.99th(us): 42047
UPDATE - Takes(s): 6.7, Count: 510, OPS: 76.0, Avg(us): 9183, Min(us): 6908, Max(us): 42047, 50th(us): 8295, 90th(us): 11175, 95th(us): 15455, 99th(us): 18591, 99.9th(us): 20079, 99.99th(us): 42047
workloadb
Run finished, takes 4.386455138s
READ - Takes(s): 4.4, Count: 952, OPS: 217.6, Avg(us): 4152, Min(us): 3196, Max(us): 27407, 50th(us): 3553, 90th(us): 5947, 95th(us): 10591, 99th(us): 11487, 99.9th(us): 18127, 99.99th(us): 27407
TOTAL - Takes(s): 4.4, Count: 1000, OPS: 228.6, Avg(us): 4380, Min(us): 3196, Max(us): 27407, 50th(us): 3559, 90th(us): 7479, 95th(us): 10799, 99th(us): 11599, 99.9th(us): 18127, 99.99th(us): 27407
UPDATE - Takes(s): 4.3, Count: 48, OPS: 11.1, Avg(us): 8898, Min(us): 7096, Max(us): 15031, 50th(us): 8271, 90th(us): 10735, 95th(us): 14975, 99th(us): 15031, 99.9th(us): 15031, 99.99th(us): 15031
workloadc
Run finished, takes 4.143589849s
READ - Takes(s): 4.1, Count: 1000, OPS: 242.1, Avg(us): 4138, Min(us): 3272, Max(us): 44351, 50th(us): 3575, 90th(us): 5939, 95th(us): 7511, 99th(us): 11207, 99.9th(us): 13191, 99.99th(us): 44351
TOTAL - Takes(s): 4.1, Count: 1000, OPS: 242.1, Avg(us): 4138, Min(us): 3272, Max(us): 44351, 50th(us): 3575, 90th(us): 5939, 95th(us): 7511, 99th(us): 11207, 99.9th(us): 13191, 99.99th(us): 44351
|
TODO#
目前的CURP只实现了基础的运行,并没有考虑crash-recovery,这对于一个共识来说显然是不足的,不过碍于时间和精力,短时间笔者是无法补全这一部分了,在这里简单说一下思路。
Version#
首先,对于挂掉和回复的节点,整个集群应当能够感知,论文中中给出的方案是维护一个集群列表+version,client首次从配置中心处持有该列表和version,之后每次请求是携带上version,随后配置中心接收到请求后会校验version,来判断client持有的配置是否过期, 如果过期就拒绝掉此次请求,并告知Client
在实现上,配置中心可以实现在Leader上,Client在调用 isLeader () 确定集群Leader时顺便获取到version和配置,并在client端维护,随后扩展一下protobuf的结构体,每次请求携带上version。server端,server端在从raft处检测到身份变更时,就应当由新的leader去生成一份新的配置+version。将其返回给client
1
2
3
4
5
6
7
8
9
10
| func (s *StateMachine) listenRaftState() {
for state := range s.stateChangeC {
s.mu.Lock()
trace.Trace(trace.Vote, s.NodeId, "raft state update: before: %s,current: %s", stmap[s.raftState], stmap[state])
// 如果是Leader,那么就生成新配置
s.raftState = state
s.mu.Unlock()
}
}
|
Witness#
由于Leader进行了抢跑,因此会有一些请求还未commit,但也已经返回给client了,这些请求的结果,或者说这些请求对状态机的影响暂时不会暴露出来(后续如果想要获取结果,或者说对其修改,都会因冲突而被拒绝)但是请求成功也确实是实打实的响应给client了。因此这一部分的请求结果不能丢失,但是又没有通过log发送给follower,因此就需要通过Witness中的存储来完成恢复。
具体来说,需要添加一条rpc,使得新的Leader能够获取到follower的witness中的数据,然后再leader处按照顺序执行并写入log。从而解决冲突并确定顺序。当log commit时,即可自动删除掉witness中的内容。
Summary#
本文基于etcd/raft,实现了一个简易的CURP,提供了fast path + slow path的逻辑,使得不冲突的请求可以在一个RTT完成。目前还欠缺recovery的逻辑,但临近毕业,笔者精力实在有限,短时间内应该是没有精力去补完了。如果想学习工业级CURP的实现,可以去看Xline:GitHub - xline-kv/Xline: A geo-distributed KV store for metadata management
目前的curp和组里的一个项目代码混在一起,不太方便全部开源,等后续有空了给分离出来扔到github上。
对于CURP而言,虽然其在性能上领先Raft不少,但是在笔者测试的过程中,发现slow path对于系统性能影响较大,ectd/raft中,log是由wal + 内存实现存储的,关闭wal之后,workloada可以从 5s缩短至 3s左右,那么是否有一种办法在不存在冲突时彻底绕过slow path呢?