如何理解CPU虚拟化?
CPU虚拟化,用一句话简单的概括就是,通过CPU虚拟化的手段,可以让多个程序在同一时间段内在一台机器上运行,共享CPU,同时对此毫无感知,每个程序认为只有自己在使用CPU。
为了达到此目的,操作系统首先将运行的程序抽象成进程。要运行一个程序即启动一个进程,为其分配相应的资源和内存空间。之后将其交给操作系统管理。而为了实现多个进程都毫无感知的同时运行使用CPU,此时就需要涉及到进程调度算法,如FIFO、多级反馈队列等。并且通过上下文切换的来实现进程之间的切换。此时就可以将单一的CPU交给不同的进程去使用,此时在宏观的时间段上来看,就有多个程序在同时执行,使用同一个CPU。
进程相关API
fork():通过fork()可以创建一个子进程,fork的调用和返回都比较奇怪,调用当一个进程调用fork之后,当前进程会从fork返回,同时也会创建一个子进程,也从fork当中返回。如果不加以区分的话,二者之后会执行相同代码。
子进程与父进程之间的区分方式采用的为进程描述符 pid,对于父进程,返回时会得到子进程的pid,而对于子进程,得到的pid为0,之后可以通过if的方式区分,另父进程和子进程执行不同的代码。但是此时父进程与子进程执行的为同一个程序,只不过是不同的部分
代码的格式如下:
| |
最终的执行结果如下:
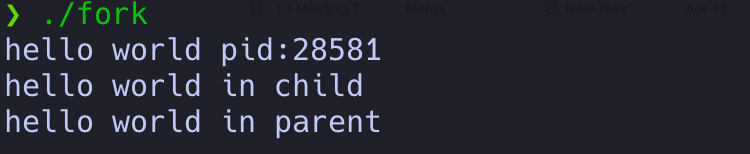
wait()父进程可以通过调用wait函数来等待子进程执行完成,如上面的结果一样,父进程打印的消息在子进程之后,如果不加wait则会乱序打印。
wait只应当在父进程中调用,如果在子进程当中调用,则会产生一个错误,并返回-1
exec():通过exec()可以令父子进程执行完全不同的程序。当子进程返回之后,可以调用exec令其执行不同的程序,exec不会创建新的进程,调用之后会将当前的子进程给覆盖掉,就像原本的进程没有执行过一样,包括代码段、堆、栈及其他内存空间都会被初始化,因此,exec之后的代码也都不会执行,对exec的调用也永远不会返回。
首先设置一个简单的打印数组的函数,用于之后给exec调用
| |
程序主体结构如下,创建出子进程之后调用exec,用于不需要参数,只需要传递一个程序名即可
| |
最终的执行结果如下:
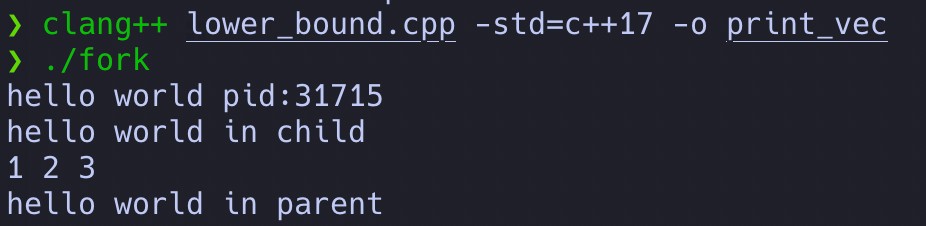
当前程序创建子进程之后,子进程调用exec执行其他的程序,exec之后的那一条输出也没有被执行,父进程通过wait等待新的子进程执行结束。
通过这三种看起来较为诡异的API,可以很方便的实现shell,shell本身也为一个程序,比如输入一个可执行程序时,shell就通过fork创建一个新的子进程,并调用exec将输入的程序名传递给exec,执行新的程序,之后shell通过wait等待新程序的执行结束。结束之后,再输出一个提示符,等待用户的下一次输入。
用户态与内核态
为了保证安全性,操作系统不能令进程不受任何限制的执行,就像早期的操作系统那样,仅仅是一个库。
为了对进程加以限制,操作系统有了用户态和内核态的概念,在用户态的模式下,进行只能执行一些基础的操作,不能发起IO访问硬件资源,而在内核态下,操作系统可以访问机器的全部资源,如发起IO等。用户态和内核态的之间通过陷阱指令和从从陷阱返回的指令来实现用户态和内核态的切换。
陷阱表是什么
陷阱表由一系列条目组成,每个条目与特定的系统调用、异常或中断相关联。每个条目包含处理程序的地址或处理程序的指针,当相应的事件发生时,操作系统会根据陷阱表中的条目找到对应的处理程序来处理事件,而执行了陷阱表上的相关指令就会从用户态切换到内核态。提升权限,完成一些操作。之后操作系统可以将控制权返回给用户态,使进程继续执行。
对于一个发起IO的进程,整个的执行流程是什么?
- 当要创建一个进程时,操作系统首先在内核态为该进程分配内存,之后将程序加载到内存当中,根据argv来设置程序栈,用寄存器/pc填充内核栈,之后从陷阱当中返回
- 此时操作系统转换为用户态,跳转到main函数,进行执行,直至执行到发起IO的系统调用
- 此时将寄存器保存到内核栈,转向内核模式,根据陷阱表来跳转到对应的处理程序
- 在内核态下处理陷阱,完成系统调用的工作,从陷阱返回
- 从内核栈恢复寄存器,切换到用户模式,pc进行相应的跳转
- 继续执行,直至从main函数中返回,通过exit(0)系统调用重新切换到内核态
- 在内核态下释放进程的内存,将进程从进程列表当中清除。
进程间如何进行切换?
在单CPU单核的前提下。首先操作系统本身也是一个特殊的应用程序,如果此时CPU在运行某个应用进程,那么他就不能运行操作系统,此时操作系统失去了对计算机的控制。为解决此问题,采用的是时钟中断的方式,即每隔一段时间CPU会发出一次中断。产生中断时,正在运行的进程会终止,此时操作系统即可重获对计算机的控制,之后可以决定是让之前的进程继续运行还是做其他的工作。
此时确定了操作系统能够间隔性的重新获取计算机的控制权。当操作系统获取到控制权之后,即可通过上下文切换的方式完成进行的切换
如何理解上下文?
上下文这个概念在计算机当中出现的较为频繁,如操作系统当中和spring当中的Application Context。简单来说就是保存了某一个时刻的全部状态,所需的信息都可以从上下文当中获取,对于操作系统来说,进程上下文即指描述进程或线程当前状态的所有信息的集合。它包含了使进程或线程能够继续执行的所有必要信息,包括寄存器值、程序计数器、栈指针、内存映射、打开的文件描述符、信号处理程序、权限等等。
因此在上下文切换时,则将当前正在运行的进程的上下文保存到内存的某个位置,之后再将另外一个进程的上下文进行加载,从内核态返回之后再执行的就是另外一个进程了。
这个过程有点类似于函数调用,在进行函数调用时,将当前函数的在寄存器当中的一些信息压入到栈中进行保存,之后便可以进行跳转,执行另外一个函数。只不过上下文切换所需保存和恢复到信息更广,而且进程之间的程序栈不共享,因此信息保存与内存当中另外的某个区域。
常见的进程调度算法有哪些
- 先来先服务(First-Come, First-Served,FCFS):按照进程到达的先后顺序进行调度,即先到先服务。
- 最短作业优先(Shortest Job Next,SJN):选择估计运行时间最短的进程进行调度,以最小化平均等待时间。
- 最短剩余时间优先(Shortest Remaining Time First,SRTF):选择剩余执行时间最短的进程进行调度,以最小化等待时间。
- 优先级调度(Priority Scheduling):每个进程都分配了一个优先级,优先级高的进程优先被调度。
- 轮转调度(Round Robin,RR):按照轮转的方式分配处理器时间片给每个进程,每个进程依次执行一个时间片。
- 最高响应比优先(Highest Response Ratio Next,HRRN):根据等待时间和服务时间的比率来选择下一个被调度的进程,以提高系统响应性。
- 多级反馈队列调度(Multilevel Feedback Queue,MLFQ):将进程划分为多个队列,每个队列有不同的优先级和时间片大小,进程根据行为在队列之间切换
介绍一下多级反馈队列调度
共有五条规则:
- 如果A的优先级 > B的优先级,则运行A
- 如果A和B的优先级相同,则轮转运行A和B
- 当一个进程进入系统时,先将其加入到最高的优先级当中
- 一旦一个进程在某一层用完了其的时间配额(无论中间是否有主动放弃过CPU,放弃了多少次)都将其移动到下一层当中,降低优先级
- 每经过一段时间S,就将系统中所有的工作全部重新添加到最高一级的队列当中
多级反馈队列基于优先级调度,即规则1 2 3。在此基础之上,为了解决底层计算密集型的进程饥饿的问题,提出了规则4,可以使新加入系统的优先级逐渐下降,同时规则4也可以防止某些进程通过主动放弃CPU的方式长期占有高优先级,规则5则可以使底层的长期得不到执行的进行重新到最高层得以执行。