Lab3
Task1
火山模型
在Task1当中实现了SeqScan Insert Delete IndexScan,由于均为火山模型,因此在实现上大同小异,就集中说明一下火山模型,和各自所需要注意的即可。
火山模型,或者说迭代器模型,核心就是借助迭代器进行遍历。即对于一个算子来说,自身即为一个迭代器,对外提供一个Next方法,将数据处理后通过Next方法一条条给对外提供。以SeqScan为例,每次调用Next都从table当中获取一条tuple,之后交给上层。
而多个迭代器可以组成迭代器链,上层通过下层的迭代器的Next函数来获取tuple,处理之后又通过自身的迭代器对外返回。就像下图这样,NestedLoopJoin以 MockTableScan作为数据来源,自身处理完的生成的tuple又一条条的通过Next交给Aggregation。
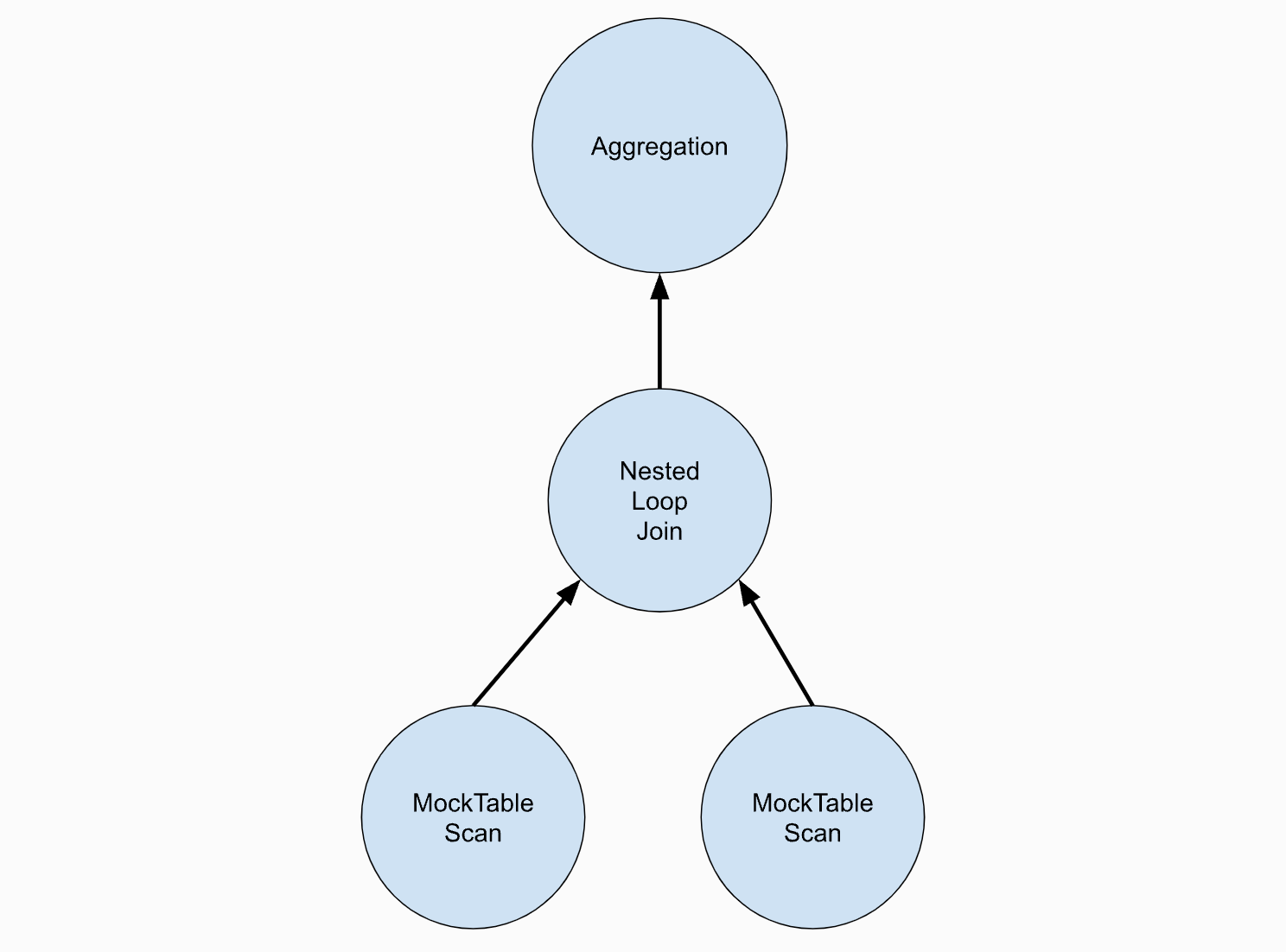
此外,这里迭代器采用的是Top-to-Bottom的方式,即以上层的迭代器为驱动,不断的调用下层的Next来获取数据。
SeqScan:实现一个全表遍历,比较简单,只需要通过table上的迭代器去一条条获取即可
Index&Delete:这两个实现上差不多,将子迭代器当中的一条条插入到目标表当中即可。需要注意的是,由于为火山模型,上层会不断的尝试调用Next直至获取到false,因此为了防止重复插入或删除,需要设置一个flag,在完成插入后置为false,之后再调用即可直接返回,中止迭代。
此外,插入和删除涉及到更新索引,调用一下对应的函数就好
Index Scan:SeqScan为通过table的迭代器进行遍历,Index Scan即通过索引来进行遍历,即之前实现的B+树的迭代器,按照Lab知道上给的提示,转换之后获取其迭代器
| |
由于BusTub实现的是非聚簇索引,因此索引当中存储的为RID,即一个tuple的唯一标识,RID由page_num 和 slot_num组成,表示该tuple属于哪张表,存在于表的哪个位置。
之后再去表当中偏移读取获取到所需的tuple
SQL执行过程
这一部分强烈推荐看一下迟先生写的ButTub养成记。我这里就简单说一下代码当中需要用到的那部分。
首先,根据SQL解析的结果,优化器会生成一个个的plan_node。代表的一个算子的执行策略,即需要从哪获取数据,获取数据的方式,tuple的结构等等。由于通过抽象语法树一步步的来,整个SQL执行的整体plan同样为树结构组织。
之后每个算子,被抽象成一个Executor,代表一个执行的动作。Executor主要有三部分组成,分别为plan, executor_context,child_executor:
plan即为上述通过优化器的来的具体执行方案,以及所需的数据,如Index_Scan当中会提供index的id,join当中会提供一个用于进行join key的Predicate,以及join的child plan
根据情况,其会拥有一个或者多个子算子
child_executor ,即火山模型的迭代器链,通过child_executor来从底层获取数据。executor_context:这个没什么好说的,就是用于保存整个数据库的上下文信息,可以通过其来获取到buffer_pool CataLog LockManager等,相比于6.830将其全部定义在Database类当中作为静态成员变量,个人感觉单独定义一个类作为上下文能够更优雅一点1 2 3 4 5 6 7 8 9Transaction *transaction_; /** The datbase catalog associated with this executor context */ Catalog *catalog_; /** The buffer pool manager associated with this executor context */ BufferPoolManager *bpm_; /** The transaction manager associated with this executor context */ TransactionManager *txn_mgr_; /** The lock manager associated with this executor context */ LockManager *lock_mgr_;
Task2
这里设计的有点绕,主要的相关类为:
AggregationPlanNode、SimpleAggregationHashTable、AggregationExecutor,一个个来看
AggregationPlanNode
包含了整个聚合操作的逻辑,通过对SQL的解析而来,包括进行哪些聚合计算,通过什么字段进行group by等。并且由于进行group by支持多个字段,以及一次可能传入多个算子,因此均为数组的形式:
| |
| |
以上的一条sql解析完之后就是group_bys为空,arggegates,agg_types分别有5个参数。
并且,只有参与Aggregation的列才会在生成plan等时候被加入到这几个数组当中,如下sql当中的v4,v5,v4+v5等均不会参与到Aggregation的过程,也不会被添加到数组当中,因此最终v4 v5会存在于group_bys当中,sum、min、count则会存在于aggregates和agg_types当中。
| |
SimpleAggregationHashTable
SimpleAggregationHashTable在内部维护一个std::unordered_map,key为ArrgegateKey,val为一个ArrgegateVal,二者本质上分别为一个vector的简单封装,与6.830不同的是,这里的group by支持多个字段,对于多个字段,可以视为组合成一个联合索引那样。数组大小为算子的数量,存储在这个groupby字段下的所有算子的计算结果。定义分别如下:
| |
| |
插入
通过查询表得到的最终结果为一个Tuple,而HashTable当中为AggregateKey,AggregateVal,因此需要将tuple进行转换,
key为groupby的字段,如果不需要groupby,那么就使用一个空的数组作为key,之后所有的val都会在这个唯一的key上计算。否则则根据提供的group by字段去tuple当中进行提取,生成一个key。
而对于Value则根据算子所需进行获取即可,如上面的那条Sql,最终vals数组当中所存储的为:[1,val(tuple1),val(tuple1),1(or null),val(tuple1)]
| |
在生成了对应的key,val之后,通过InsertCombine以及CombineAggregateVlues进行插入。在其中找到对应的groupby字段之后,将所有的算子在原本的基础上进行计算。
| |
Iterator:为了将计算结果进行导出成Tuple,ht还提供了一个迭代器,可以用其对key和val分别进行迭代
AggregateExecutor
在大致结构上和其他算子基本相同,都有一个由sql解析出来的plan,和一个用于读取数据的child_iterator,此外还有用于存储聚合结果的hashtable和用于导出聚合结果的迭代器.
| |
与其他的算子不同的是,Aggregation是 pipeline breaker,即其他的火山模型的算子,通过next来获取到一条数据之后,立即向上返回,即自始至终该算子只会拥有或者处理一条tuple,而Aggregation不同的是,他通过child_terator的next获取到所有的数据,当计算完成之后,在通过自身的Next去将结果一条条的向上返回,但是这里依旧是火山模型,只是做了一次截断,并不会像物化模型那样一次性的返回多个tuple。
因此就需要在Init当中迭代完child_iterator当中的所有的tuple,计算完成之后再通过Next将结果一条条向上返回。
Next
正如上面所说,Next的作用就是通过迭代器,迭代上述存储聚合结果的hashtable,根据数据来一条条生成tuple。分别对key val进行迭代,即groupby和 aggregates,将其作为tuple的一列,插入到一个数组当中,之后根据该数组来构建tuple。
NestedLoopJoin
这里实现上和6.830的差不多,主要有三个问题:
duplicated key
需要注意的是不要漏匹配即可,如下表:如果直接双层while嵌套的话,在完成了T1的1 和T2的第一个1匹配完成并返回之后,上层再调用Next,就会调用T1.Next,就会令T1迭代到2,导致T1和T2的第二1匹配遗失,换句话说就是无法处理重复的key
t1 join t2 on t1.colA = t2.colA
| T1.colA | T2.colA | |
|---|---|---|
| 0 | 0 | |
| 1 | 1 | |
| 2 | 1 |
因此为了防止每次调用Join的Next左表都会向下遍历一次,采用一个变量去暂存一下左表当前的tuple,之后当右表完全遍历完一次之后,左表才会通过Next移动至下一条tuple。
大致结构如下:
| |
右迭代器
在NestedLoopJoin当中,左表当中的每一条数据都会遍历右表来寻找能够匹配的tuple,因此会导致右表的迭代器不断耗尽。最偷懒的方式为当右表的while迭代完成一次之后就调用其Init()进行重置,不过这样后续又会去磁盘当中读取,造成不必要的io,因此更好的方式为通过一个数组进行暂存,之后遍历这个缓存下来的数组即可,可以减少多次IO。
left join
BusTub分别支持Inner Join和Left Join,如果左表的一个tuple在右表当中完全没有匹配的话,通过在右表的位置填充null,生成一条数据。
NestedIndexJoin
和NestedLoopJoin稍有不同,主要是数据的来源,由于驱动表一定要遍历,因此选择没有索引的表作为驱动表,右表的数据获取方式通过索引来实现。由于BusTub的索引不支持重复的key,因此也不需要一个变量来保存左表的tuple防止返回迭代了。如果通过索引能找到,那么就创建一条完整的记录,如果索引当中找不到并且当前的类型为left join,那么就创建一条记录,用null对右值进行填充。大致结构如下:
| |
HashJoin
在Lab当中并没有要求实现HashJoin,但是个人感觉比较有意思,再加上单纯在内存当中的HashJoin实现起来并不困难,就给实现了一下
通过一个HashTable来存储右表当中的tuple,而由于join key可能重复,因此HashTable应当以hash为key,数组为value,数组当中存储有相同join key的Tuple。
| |
实现上的大致思路就是首先遍历右表,将tuple存储到HashTable当中。之后再遍历左表,去和右表进行匹配,此时相当于在右表上建立了一个HashIndex,如果匹配成功则将其记录到result_tuple数组当中,如果匹配失败,则去考虑是否为LeftJoin,如果是则添加一条右表为空的记录,先遍历右表的原因也是用于处理LeftJoin
在进行匹配时,需要处理哈希冲突的问题,第一次忘考虑了,出现了9和8300被哈希到了同一个槽当中,之后误匹配上了,解决办法也比较简单,在通过哈希值找到对应的key之后在join前判断一次是否相等即可。
| |
之后在Next当中通过迭代器去访问result_tuple即可
使用HashJoin进行优化之后,Leaderboard bonus的Q1执行会快上很多,如果不进行优化的话为30000,使用HashJoin可以到80多

Task3
分别实现sort limit topN三个算子以及topn对应的优化,前两个没什么好说,SeqScan修修补补即可。
Top-N
Top-N主要针对的为sort+limit的情况,即order by xxx limit n,这种情况如果不进行优化则需要全表遍历并排序,之后再对排序完的结果进行一次计数截取。
通过Top-N即可保证只有一次全表遍历,计算完之后逐条返回。
根据lab的提示,很容易就可以确立思路,维护一个优先队列,并且保证当中只有K个数据,即通过Next不断获取并插入到其中,如果达到了K个就弹出一个,保证至多有K个
Think of what data structure can be used to track the top n elements (Andy mentioned it in the lecture). The struct should hold at most
k elements (wherek is the number specified inLIMIT clause).
不过由于std::priority_queue当中并没有提供迭代器,也没有提供下标访问,而top访问的是排序最低的那个,因此可以使用一个栈,将整个逻辑进行翻转,从而保证从高向低的进行获取。
Top-N Optimizer
| |
将原本未经优化的plan树通过多条规则链式的进行优化,最后得到一个最终的优化结果。对于单个的优化方案,都是采用后续遍历的方式,自底向上的改写plan,将符合的类型进行优化。
因此照猫画虎的实现一个,通过Top-N对sort+limit的情况进行优化,只有上层为limit,下层为sort的情况,才将其优化为Top-N。
Summary
总的来说Lab3的难度并不大,并且在本地提供了全部的测试用例,而且不涉及并发,因此可以安心的单步调试,写起来也就比较的粗放一点,面向bug编程。
整个Lab3做下来给我的感觉是相比于6.830,bustub更注重于深度,在很多地方都提供提供了一定的封装,如磁盘的读写,tuple的读取和写入。虽然少了自行构造table和tuple的过程,对于schema的理解可能差一点,但是在有限的时间内更注重于深度。此外,由于SQL执行这一部分设置在了索引之后,因此在功能的实现上也可以应用索引,如NestedIndexJoin、IndexScan等。在做6.830的基础之上写busTub的话个人感觉会更有收获一点,但是如果只写一个的话,BusTub可能更合适一点,不过需要去阅读一下其他部分的源码,或者像某些佬那样直接自己实现一个BusTub。
最近手头事有点多,也快考试了,整个文章写的比较仓促,Leaderborad bonus暂时也没时间写了,只能先搁置在一边了。