BusTub Lab1 Buffer Pool Manager
Task1 可扩展哈希表
相关函数
Find(K,V):查询一个Key是否存在,如果存在则将其V指针指向相关的值,返回true,否则返回falseInsert(K,V):插入一个值,如果已经存在,则覆盖原本的值,返回true,如果当前k-v不能被插入(bucket满了,并且不是对原有的key进行更新),则:- 如果局部深度(容量)等于全局深度,增加全局深度,并且对dict的容量翻倍
- 增加当前要插入的bucket的深度
- 分裂当前的bucket,对其进行rehash
之后再进行重试,在此Lab当中,在插入之前进行容量的检测并进行rehash
Remove(K):删除给定的Key,存在则返回true,否则返回falseGetGlobalDepth():返回全局深度GetNumBuckets():返回当前存在的bucket的总量
Hint:
- 可以使用
IndexOf(K)来求出当前Key所属的bucket - Bucket作为一个内嵌类之于HashTable
- 保证线程安全,使用std::mutex
实现
逻辑上较为清晰,首先实现Bucket类,在KV的管理上,需要实现Find、Insert、Remove操作,并且需要有一系列获取相关信息的操作,
Bucket本身是由一个链表进行组织的,实现上直接调用std::list的API即可
主要讨论一下Hash过程
对于可扩展哈希,主要有四个变量:
- size_dir_:表示整个目录的大小,扩展时进行翻倍
- size_bucket_:一个bucket中能够存放的最大的元素,为固定值
- global_depth:根据global_depth的位数将key hash到对应的bucket当中
- local_depth:在bucket split时使用local_depth进行rehash
在引入了深度的概念之后,由于可扩展哈希分为bucket和bucket当中的元素,对应的就有全局深度和本地深度的区分,如果全局深度为2,则证明当前至多只能有4个Bucket,(而实际的bucket数量可能并没有4个,存在多个dir指向同一个bucket的情况)而如果本地深度为2,则下次bucket进行分裂时,使用local_depth +1位进行rehash(如果认为最右一位为第1位,实际上只需要将1左移local_depth位即可)
在搜索时,先根据global_depth找到所属的bucket,再在bucket其中遍历寻找到元素
明确了概念之后,可以捋一下整个过程:
尝试向其中插入[0,1,2,3,4,5]
当bucket满了时:
- 如果局部深度(容量)等于全局深度,增加全局深度,并且对dict的容量翻倍
- 增加当前要插入的bucket的深度
- 分裂当前的bucket,对其进行rehash
- 最初在初始化时,
global_depth = 0local_depth = 0,此时只有一个bucket,并且当中能够存放一个元素

之后向其中插入元素1,而此时bucket当中有两个元素,需要对其进行区分,(触发了全局深度等于本地深度的条件),因此:
- 增加全局深度,
global_depth = 1,bucket数量翻倍 - 增加本地深度,
local_depth = 1 - rehash
说一下最后的rehash的过程,虽然此时
local_depth = 1,但是在gloabal_depth=1的条件下,hash码01无法定位到0号bucket,因此需要对其进行rehash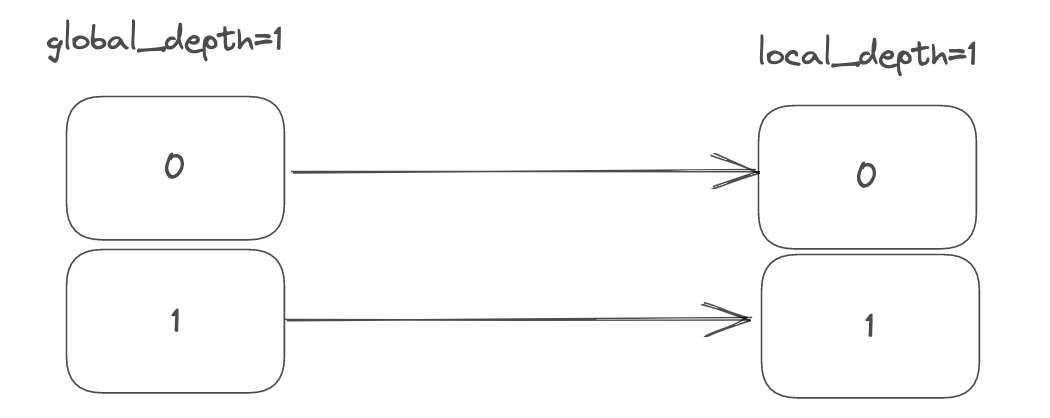
- 增加全局深度,
此时再向其中插入2(10),
global_depth = 1因此会被rehash到0号bucket当中,而0号bucket并未满,因此可以将其插入到其中,3(11)同理,结果如下: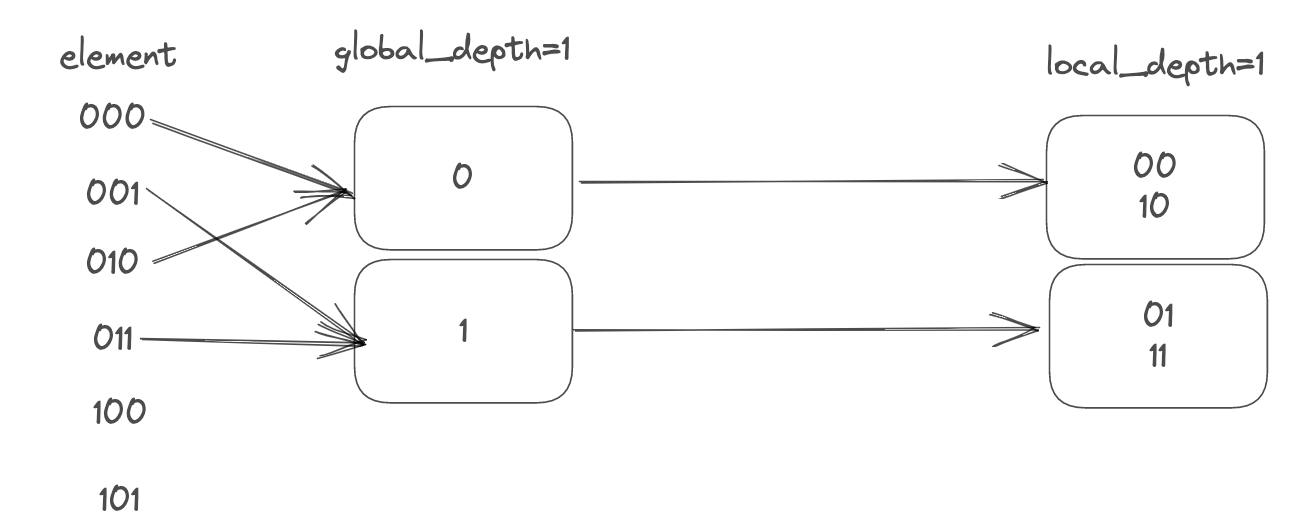
再向其中插入4(100),在
global_depth = 1的条件下被分配到0号bucket,而此时bucket0已满,按照上面的要求步骤对bucket0再split一次,插入后的结果如下: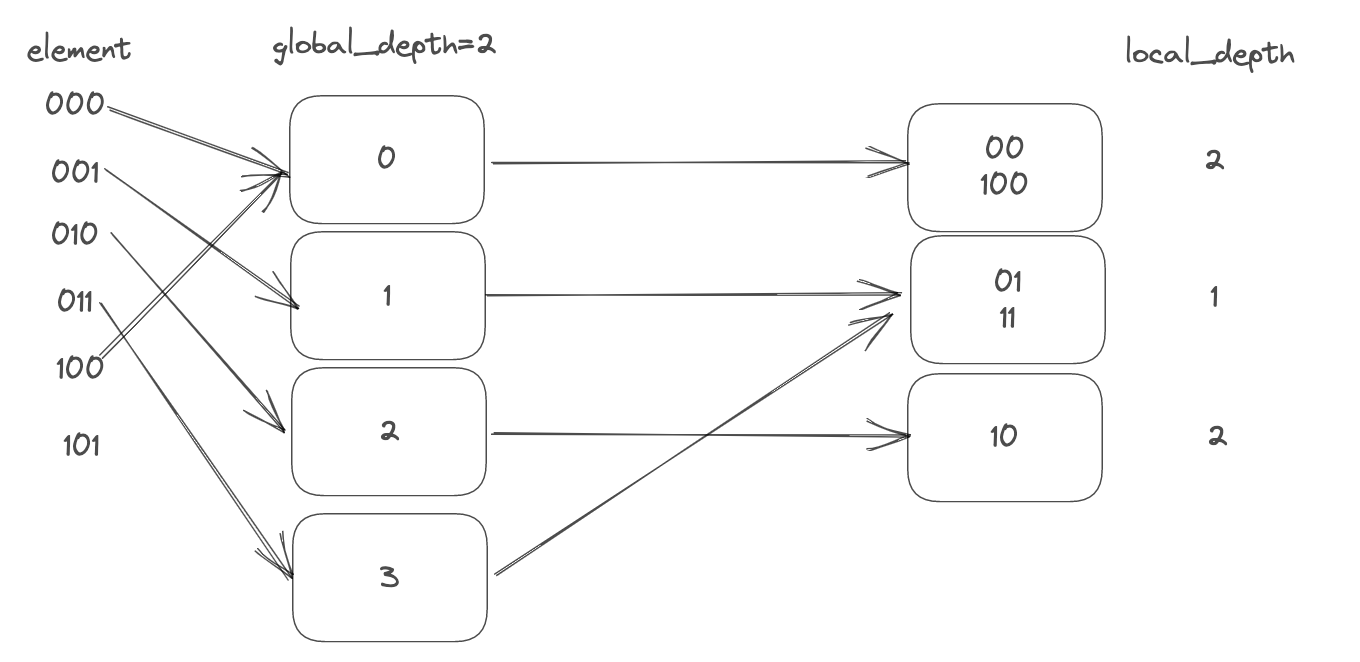
插入5和4同理,将bucket1进行split,最终结果如下:
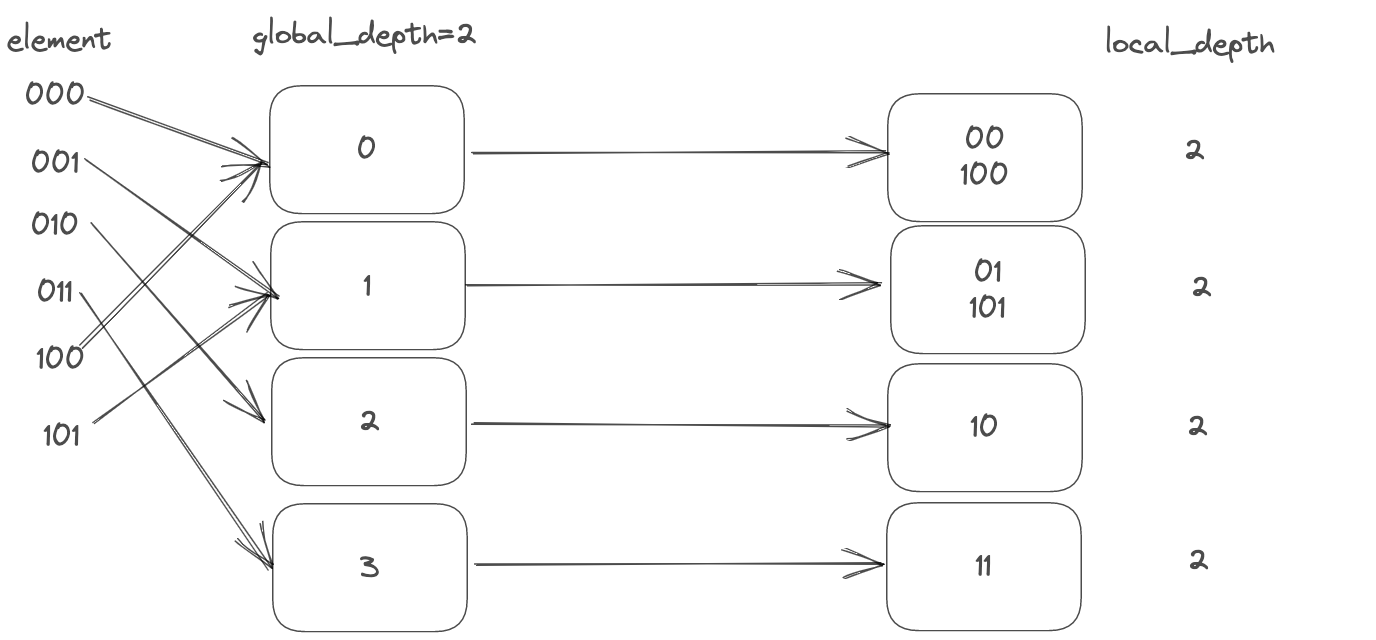
还有一点需要讨论的是,并不是通过gloal_depth + local_depth对key给进行定位,对于global_depth,既是代表当前的dir数量,2则代表有00 01 10 11四个bucket,并且对于一个哈希码,确实可以通过global_depth位就将其归于属于的bucket当中,但是对于local_depth,仅仅只是在split时用于将当前bucket中的元素和新插入的元素rehash到不同的bucket当中,即与key的搜索无关,也与bucket的容量无关。
对于local_depteh < global_depth的bucket,会存在多个dir指向同一个bucket的情况,当local_depth = global_depth时,则只会有一个dir指向该bucket。
而在bucket split时,通过local_depth来决定元素都属于哪一个新的bucket当中。即将1左移local_depth位,即为local_mask,hash该位为1的归于一个bucket当中,为0的归于一个bucket当中。
之后再去考虑两个新的bucket均需要属于哪个dir,上一步位与为0应当对应原本的dir[i],而另外一个应当为dir[i+local_mask]。因此现在所做的就是需要找到i为多少,计算hash值然后取local_depth位,再与local_mask位与,结果为0即为low_bucket,为1即为high_bucket。
此外需要考虑连续分裂的问题,如[0 1024 4]进行一次split不足以将这三者区分开,因此一种解决方法是在split最后调用extendiable_hash_table中的Insert,而不是调用bucket的insert,让哈希表的Insert再去判断一遍是否还需要分裂,不过这样嵌套调用无法使用RAII类型的锁,需要手动去加锁解锁。
| |
| |
在实现上先实现Bucket即可,先将Bucket设置为无锁的类型,再整个HashTable上加一把大锁,后续再考虑进行改进,以提高并发度
Task2 LRU-K
在淘汰时选择Backward k-distance最大的进行淘汰,Backword-distance使用当前的时间戳和第前K次访问的时间戳进行计算,还未达到K次访问的Backword-distance记为正无穷,而当有多个正无穷时,则选择最早的时间戳进行淘汰。
LRUKReplacer和BufferPool的大小一致,但是任何时刻下并不是所有page都会去考虑被淘汰,
相关函数
Evict(frame_id_t*):在被Replacer记录的所有的可淘汰的frame中选择Backward k-distance最大的那一个,在参数中保存淘汰page的Id,返回true,如果没有可淘汰的frame则返回falseRecordAccess(frame_id_t):基于当前的时间戳,记录给定的frameid,当一个page被BufferPoolManagerpin时调用Remove(frame_id_t):清除一个frame的所有相关历史,当page被删除时调用SetEvictable(frame_id_t,bool set_evictable):标记一个frame是否可清理Size()返回可清除的frame的数量。
实现
相关概念
LRU-K所针对的为缓存污染的问题,即遇到全表遍历等大量读取多个不重复的page时,如果使用LRU会将当前缓存中的所有的page全部淘汰掉,从而造成缓存失效的问题。
在LRU-K中,主要的淘汰依据为backword k-distance,即据K次访问前的距离,
- 而此处的距离作为时间的抽象,访问时间距离当前越久则为时间越长。而前K次访问的距离则是前K次访问的时间,可以用时间戳来表示
- 而对于访问次数还未到K次的情况,则是将其记为+inf,即正无穷
- 当进行淘汰时,选择
backword k-distance最大的frame进行淘汰
因此,由于还未访问到K次的frame会被记为正无穷,因此淘汰时会选择还未访问到k次的进行淘汰,而如果存在多个访问还不到K次的frame,则该几个frame之间使用普通的LRU进行淘汰,比较上一次的访问时间,其实即为k = 1的情况。
而如果全部为访问了K次以及以上的frame,那么则选择distance最大的进行淘汰。
目前能够想到的方案就是对于frame使用一个map来管理,而对每个frame封装一个frameInfo,在其中维护如是否为+inf,一次一个长度为K的链表,记录前K次的访问时间。但是这样的问题就是每次淘汰frame时需要遍历整个map,统计出K次访问最久远的frame,无法想LRU那样在O(1)的时间复杂度完成get/put。
时间戳可使用自增的id即可。
此外还有一个概念,BufferPool和LRU-K Replacer当中存储的为frame,在BufferPool当中,应当预先初始化好一定的frame,之后frame的数量一直不变,每个frame对应一个frame_id,任何大于总容量的frame_id均为非法的frame_id。在replacer当中定义一个replacer_size,其大小应当和buffer_pool的size大小相同,同样对违法的frame_id进行检测
实现
单HashMap内嵌List
说清楚了相关概念,就再说一下如何实现,我主要想到了两种实现方案,第一种是上述的FrameInfo,然后在一个HashMap当中去管理所有的FrameInfo,定义如下:
| |
isInf表示当前是否已经被访问了K次,如果还未,则设置为true,之后进行淘汰时优先淘汰还未访问K次的frame,当到达K次之后再设置为false。evictable表示当前的frame是否能被淘汰,用于在bufferpool当中pin住一些page,同时evictable也决定当前replacer的size。deque表示当前的该frame被访问的时间戳,大小上限为K,只保存K次以内的情况(不知道为什么用list就插入不进去,最后选择了deque,c++学太烂了先不管了)

在这种实现方式下就不怎么分历史队列和缓冲队列了,反正历史队列和缓冲队列本身都要要存入bufferPool当中的,不如直接统一管理
Record_access:添加一次访问记录时首先判断之前是否访问过,如果访问过则找到之前的访问记录,则在尾部添加一条新的,注意是否超过K次取消掉+inf和超过K次之后把最早的删除掉即可,如果之前没有相关记录则直接新建一条即可
Remove、Size、SetEvictable的实现较为简单,按照注释完成即可
Evict:按照LRU-K原本的定义,应当先遍历历史队列,如果当中有frame的访问历史记录,则从历史队列中删除,历史队列当中如果没有能够可以淘汰的再选择从缓存队列中进行淘汰。因此对整个FrameInfo Map进行遍历,
标记所有的inf,记录最小的时间戳,同时也记录访问了K次的,记录最小的时间戳,最终如果找到过inf的,则选择inf的进行淘汰,否则淘汰访问了K次的,注意跳过non-evictable即可,弄清楚了LRU-K的概念之后实现起来就没有什么难度了。
双List+单HashMap
这种方式则使用将历史记录和缓存分别使用两个List管理,之后删除是先遍历历史记录的List,如果找不到可以删除的,则再遍历缓存的List,
- 在添加一次新的访问时,如果之前毫无记录,则将其添加到历史记录当中,并使用HashMap存储记录当前的迭代器位置和所属的队列,
- 如果访问次数i
1< i < k,由于比较的是最早的访问时间,因此什么都不用做 - 如果访问次数到达K次,则将其移入到缓冲队列当中,更新Map当中相关的迭代器和所属队列
- 如果超过K次,则将其移入到缓冲队列的尾部,淘汰时从头部开始进行淘汰,更新迭代器
当淘汰时则先遍历历史队列,寻找第一个evictable的frame进行淘汰,如果找不到,再去缓冲队列当中去寻找。
严格来说这种实现方法更符合LRU-K原本的定义,这样如果不考虑 evictable所带来的额外比较,在evict remove时的时间复杂度为O(1),而之前那种实现方式需要遍历整个Map因此为常数复杂度,等有空考虑重构优化一下。
本身也没有什么线程安全问题,各个函数直接一个区域锁利用 RAII保平安。
Task3 Buffer Pool Manager Instance
从磁盘当中去读取page存储到内存当中,当Buffer Pool满了之后,再使用LRU-K将page从内存中淘汰,写回到硬盘上。
内存中的Page使用Page对象进行抽象,buffer pool无需关心page当中的内容,page当中包含一块内存,对应一个物理页,之后将对应的内存上的内容写入到硬盘上,一个Page对应一个物理页,通过page_id进行表述,如果该page没有对应的物理页,则page_id为INVALID_PAGE_ID
Page当中需要有一个计数器记录有多少个线程pinned了该page,对于被pinned的page,不允许将其释放,page需要记录是否为dirty,如果非dirty则淘汰时不需要回写硬盘,而dirty的page需要先回写再重新使用
使用之前的ExtendiableHashTable进行page_id到frame_id的映射,使用LRUKReplacer来记录各个page的使用情况
FetchPgImp(page_id):如果没有可用的page并且其他的page全部被pinned了,返回nullptrUnpinPgImp(page_id, is_dirty)FlushPgImp(page_id):不管是否被pin,都将page给刷盘NewPgImp(page_id):AllocatePage用于生成一个唯一的PageId,DeallocatePage 模拟将page刷盘到硬盘上,在DeletePgImp当中调用DeletePgImp(page_id)FlushAllPagesImpl()
实现
Buffer Pool的整体实现并不难,首先描述一下整个Buffer Pool的物理结构,Buffer Pool当中的容器或者说page的载体为frame,所有的frame本身是不变的,即frame的数量即为Buffer Pool的大小,在Buffer Pool进行初始化时,初始化一个Frame数组,其中每一个元素及对应着一个Frame,数组的下表即为Frame_id,如果page为尚未初始化的状态,则代表该frame当中还未存放元素,当有一个Page要受到Buffer Pool管理时,则对该Page进行初始化,设置对应的PageId和元数据 以及Page当中存储的数据设置到该Page当中。
除此之外还有Buffer Pool的管理数据结构,即前两个task所实现的可扩展哈希表和LRU-K Replacer,以及一个用于记录空frame的链表
当一个Page要加入到Buffer Pool当中,无论是新建一个Page还是从硬盘当中读取一个Page,首先先尝试从空frame链表当中获取一个frame_id,之后在Page数组当中对其进行初始化,而如果空闲链表当中没有额外的frame_id去分配,则证明当前的Buffer Pool已满,因此需要尝试通过LRU-K去淘汰一个当前Page的,获取一个新的Page,为了流程的统一,就淘汰之后再将frame加入到空闲链表当中,之后再从空闲链表当中尝试去获取一个Page。将新的Page重新让Replacer和page_table去管理。
以NewPage为例,大致架构如下:
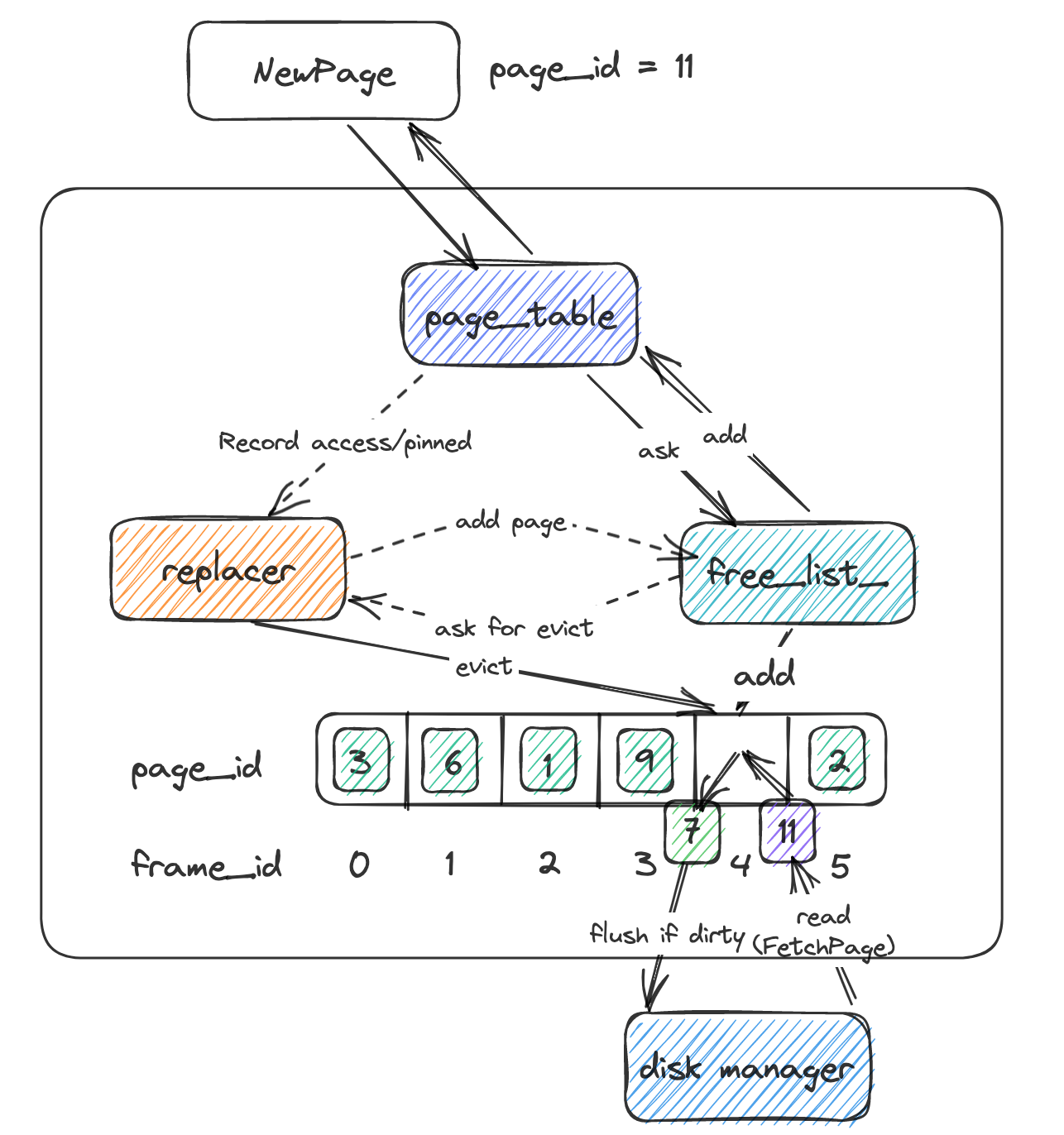
搞清楚了整体架构再实现起来就比较方便了,这里就简单解释一下几个函数的相关作用,
NewPage:即为上层需要创建一个新的Page用于存储新的数据,如在Insert时进行调用,即按照上图的步骤完成即可,先后尝试从
free_list_,若不能则告知replacer进行淘汰,再从free_list_当中进行获取,最后创建Page,并Page交给BufferPool管理。此外,创建Page即代表上层需要一个Page来承载数据,即当前需要使用该Page,因此需要该Page驻留在Buffer Pool当中,因此创建之后应当
pin住它,即修改pin_count_和evictable。由于涉及修改好几个数据结构,因此做了一个封装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14auto BufferPoolManagerInstance::CreateNewPage(frame_id_t empty_frame_id) -> Page * { auto new_page_id = AllocatePage(); Page *new_page = &pages_[empty_frame_id]; ResetPage(new_page, new_page_id); // pin a new page new_page->pin_count_++; AddNewPageToBufferPool(empty_frame_id, new_page_id); return new_page; } auto BufferPoolManagerInstance::AddNewPageToBufferPool(frame_id_t frame_id, page_id_t page_id) -> void { replacer_->RecordAccess(frame_id); replacer_->SetEvictable(frame_id, false); page_table_->Insert(page_id, frame_id); }通过
replacer_淘汰一个page封装成一个函数,淘汰之后如果为脏页则需要进行Flush刷盘,因为EvictPage会被加锁的NewPage调用,因此自身并不加锁,而且调用无锁的FlushPage1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17auto BufferPoolManagerInstance::EvictPage() -> bool { frame_id_t frame_id; bool result = replacer_->Evict(&frame_id); if (!result) { return false; } // if frame can be evicted,it means page is not pinned; Page *page_to_evict = &pages_[frame_id]; if (page_to_evict->IsDirty()) { FlushWithoutLock(page_to_evict->GetPageId()); } free_list_.push_back(frame_id); page_table_->Remove(page_to_evict->page_id_); replacer_->Remove(frame_id); return true; }FetchPage:在流程上和
NewPage差不多,尝试从Buffer Pool当中获取一个Page,如果page_table_当中有则证明存在于Buffer Pool当中 ,直接读取返回。而如果没有则分别从free_list_和replacer当中尝试找到一个frame来承载Page,使用disk_manager_进行读取,然后交给Buffer Pool管理。由于
FetchPage的目的也是去读取一个Page为上层所用,因此同样需要将其pin住,直至使用完。此外如果是通过
free_list_和replacer_所获取的Frame需要先清除上一个Page在其中残留的数据,之后加载新数据,由于grade_scope上传时不会去打包Page.h,因此不应当对Page.h进行修改,因此将该函数封装到Buffer Pool当中1 2 3 4 5 6auto BufferPoolManagerInstance::ResetPage(Page *page, page_id_t page_id) -> void { page->ResetMemory(); page->page_id_ = page_id; page->pin_count_ = 0; page->is_dirty_ = false; }UnpinPage:
NewPage和FetchPage均为获取一个Page,之后为上层所用,因此获取的同时会Pin住该Page,而UnpinPage即为用于在使用完page之后取消对该page的占用,让其可以被淘汰。Unpin一次则对pin_count_递减一次,当为0时证明没有任何上层函数在占用该Page,则可以set evictable,之后replacer即可对其进行淘汰同时
UnpinPage会传入一个is_dirty,来代表之前占有Page时进行的操作是读操作还是写操作。此外Page上is_diry的修改会有一定的限制,即如果原本为脏页,那么此次进行的是读操作,那么不能进行修改,需要保持脏页状态。而如果原本非脏页,那么即可随意修改。FlushPageDeletePageFlushAllPage等逻辑比较简单,按照注释写基本就没什么问题。
debug
关于线程安全,保险的方案就是使用一个区域锁锁住整个函数,一把大锁保平安,但是之前写的时候在EvictPage当中偷懒复用了一下FlushPage,因此调用前解锁,调用完再加锁,导致了一个中间状态,再解锁的间隙所就被在并发的其他函数(UnpinPage)抢走了,如果按照事务的说法就是违反了原子性,导致已经pin_count_ = 0的Page又被其他的线程抢走了重新Unpin一次
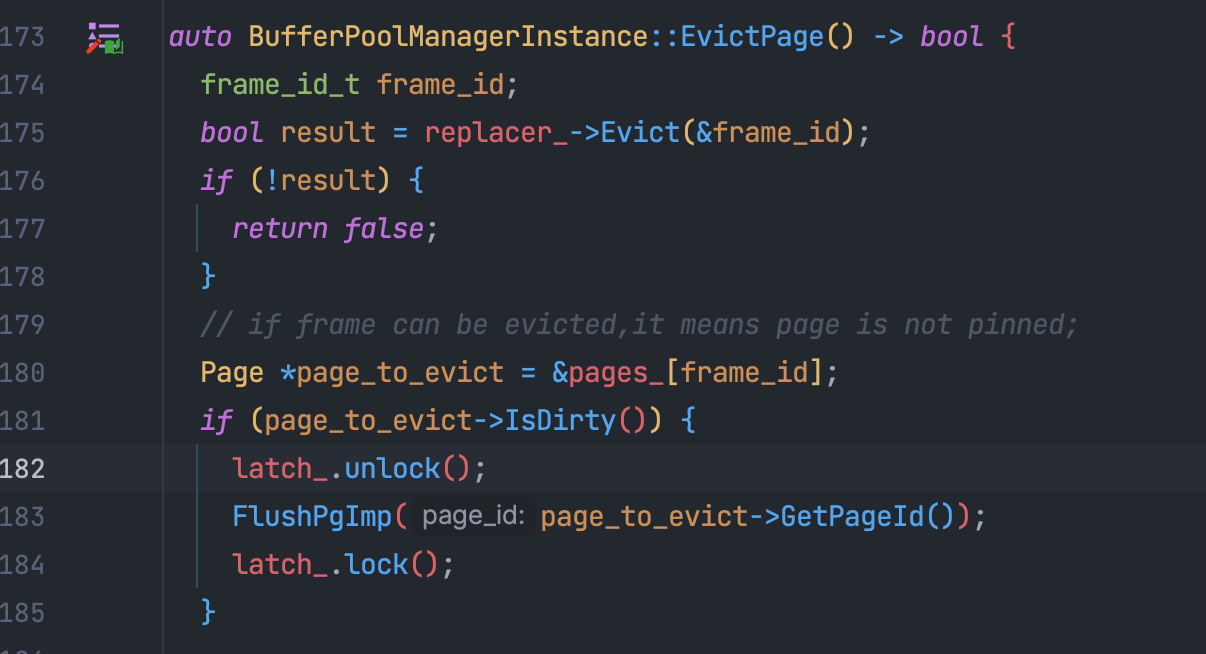
因此最终选择单独封装了一个无锁版本的FlushWithoutLock,之后EvictPage FlushPage FlushAllPage全部调用该函数。即可保证线程安全,不会出现中间态。
Summary
整个Buffer Pool的难度并不算大,写完之后也大致感受到了BusTub和6.830的侧重点 相比于6.830 BusTub少了很多dirty work,更注重于核心部分的实现,像表结构,Catalog,和HeapFile统统没有让我去写,而是专注于整个Buffer Pool。
Buffer Pool 从0开始 可扩展哈希表+LRU-K的实现也有意思很多,相比于6.830的直接无脑一个ConcurrentHashMap,淘汰策略也没有做任何要求,FIFO也能通过测试。
不过个人感觉刚接触数据库的话6.830可能比较友好一点,能对数据库的各方面都有一定的了解,有些dirty work首先一边体会才更深,例如HeapPage HeapFile里面的一个比较Tricky的位于算和Bit map,445的话就不能光去实现project了,其他地方的源码最好也读一读。