数据库基础结构
数据库结构
为什么需要DBMS?
一个数据库在最基础的层次上需要完成两件事情:当你把数据交给数据库时,它应当把数据存储起来;而后当你向数据库要数据时,它应当把数据返回给你。
因此,最简单的数据库可以使用两条bash脚本来完成,在ddia当中也给出了例子:
| |
存储时,则对其进行追加写入,将新数据添加到文件的末尾,因此对于重复的key,永远在末尾为最新的数据,因此在读取时,则读取指定key的最后一个数据作为结果。
不妨思考一下这个最简单的数据库有什么又存在什么问题,可以得到最终的答案
首先该数据库采用的为基于日志结构的,可以提供持久化存储,作为数据库的最基本功能
- 之后由于所有数据全部存储于硬盘之上,每次读取都涉及到较高的磁盘IO,因此需要通过buffer pool manager来将数据存储于内存当中进行缓存以提高性能
- 每次读取都需要遍历所有数据,可以通过构建索引进行优化,如bitcask在内存当中构建一个hashmap或者构建B+树
- 在末尾追加会在磁盘当中产生大量冗余,因此需要优化存储,最简单的方式为采用bitcask进行定期压缩,或者直接采用LSM-Tree结构进行存储。以上两种为采用基于日志的结构的,此外,还可以采用基于Page的HeapPage进行存储
- 对于某些业务,需要提供事务的支持,即事务的ACID
- 为防止数据丢失并且优化写入速度,即将随机写入转换为顺序写入,引入日志系统
- 对多线程的访问提供支持,相关数据结构需要保证线程安全,并且对于事务也需要提供Lock Manager的支持
- 以上为KV类型的,如果需要实现关系型数据库,那么则需要实现关系模型,和SQL的执行引擎和优化器
为什么需要Buffer Pool?
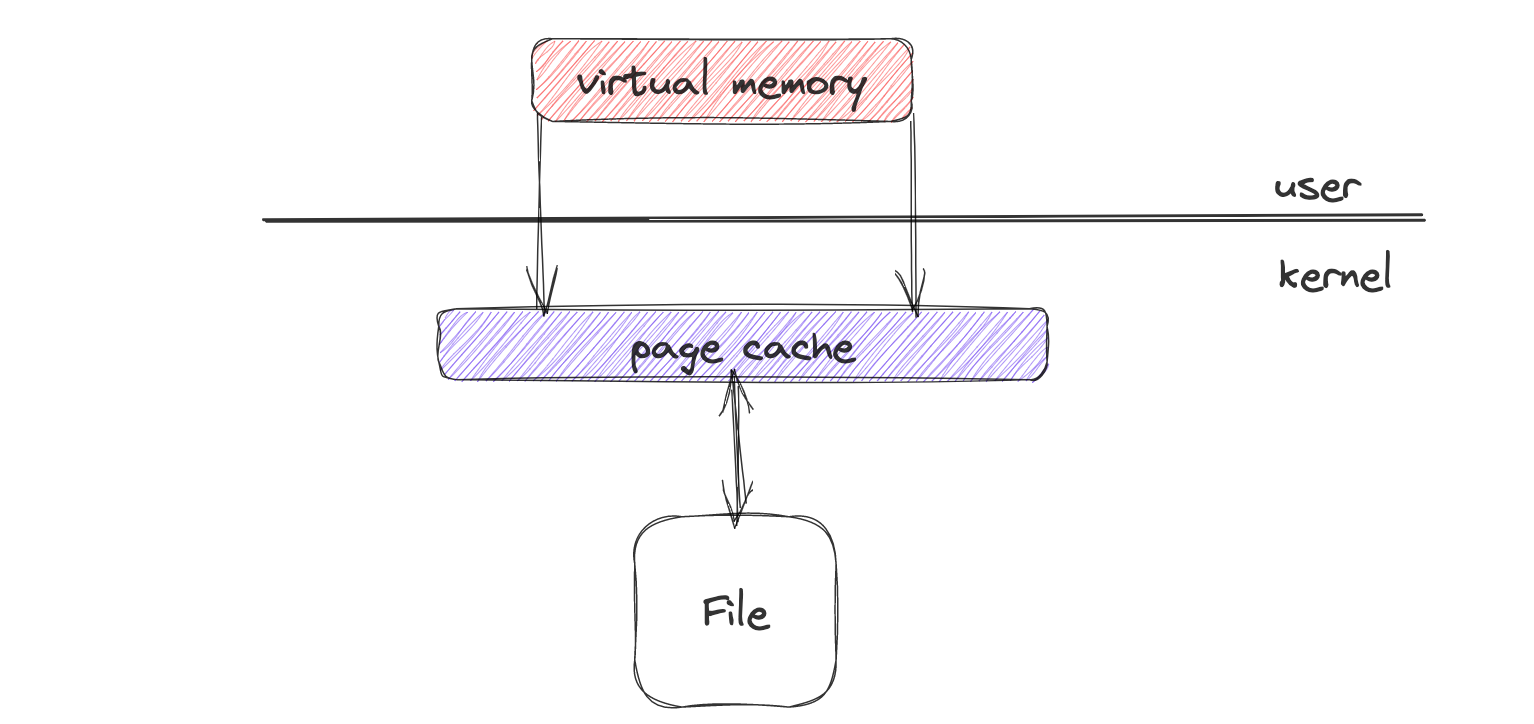
说明了数据从硬盘到内存当中最后为CPU所用的过程,而操作系统作为之上的最底层,为了防止过分频繁的访问,OS本身也会对操作系统的Page进行缓存(OS的Page区分于DBMS的Page),即page Cache
当通过系统调用read()进行读取时,内核首先会从page cache当中去寻找是否存在缓存,如果不存在缓存,则申请页帧空间,进行IO操作,之后将其存放到page cache当中,进行缓存,之后再将其拷贝到程序的缓存当中,读取结束
这样存在的问题是一份数据在page cache当中进行了一次缓存的同时,还在程序当中进行一次缓存,缓存两次导致CPU cache命中率不高。因此提出的内存映射机制(linux当中为 mmap)
在使用mmap调用时,系统并不马上为其分配内存空间,而仅仅是添加一个VMA(Virtual Memory Area)到该进程中,当程序访问到目标空间时,产生缺页中断。在缺页中断中,从page cache中查找要访问的文件块,若未命中,则启动磁盘I/O从磁盘中加载到page cache,然后将文件块在page cache中的物理页映射到进程mmap地址空间。数据在内存当中只会存在一份,并且之后当程序退出或者关闭文件时,page cache当中的数据并不会清除,如果物理内存足够的情况下,会一直保存在内存当中,供之后的进行去读取。
由此可见,OS对于数据已经提供了一定的缓存能力,但是我们仍需要在DBMS当中提供一个Buffer Pool去手动管理内存,原因如下:
- OS对于数据库当中的内容一无所知,即OS并不知道当前的那些Page对于数据库来说是较为重要,不能被淘汰的,想象这样一个场景,遍历table1从中获取到age最大的那一行数据,而在遍历读取page的过程当中,OS判定系统的物理内存不足,需要进行淘汰,但是把之前加载到内存当中的page进行淘汰。导致整个SQL执行出现问题。
- 使用Buffer Pool进行手动管理,可以明确
pin住某些page,在Buffer Pool进行淘汰时则不会选择其进行淘汰。 - 同时Buffer Pool高度自定义性,整个Buffer Pool的大小,以及单个page的大小,不再受限于OS
如何管理Buffer pool当中的Page?
OS相关的page淘汰策略都可以拿来直接使用,如FIFO、Random、LRU、RR等,此外还可以使用LRU-K的淘汰策略,
简单介绍一下LRU-K?
LRU-K将缓冲区分为历史队列和缓冲队列,一个page首先加入到历史队列当中,在淘汰前访问了k次,那么就将其移动到缓冲队列当中。并且引入了K- distance的概念,即前K次的距离,可以简单使用逻辑时间戳来表示,在历史队列当中的K- distance为正无穷,而在缓冲队列当中的Page的K- distance即为前K次访问的距离(即时间戳的差值)在淘汰时选择K- distance最大的进行淘汰
通过LRU-K,可以避免由于全表遍历而导致的缓存污染问题
LRU-K的缺点?
ChatGPT:
LRU-K(Least Recently Used K)是一种缓存淘汰策略,它根据最近使用的频率来确定要淘汰的缓存项。虽然 LRU-K 在某些情况下表现良好,但也存在一些缺点:
- 内存消耗:LRU-K 需要维护额外的数据结构(如计数器或时间戳数组)来跟踪最近使用的频率。这会增加额外的内存消耗,并可能影响缓存系统的整体性能。
- 算法复杂性:相比于简单的 LRU 算法,LRU-K 需要更多的逻辑和计算来跟踪和更新每个缓存项的使用频率。这增加了算法的复杂性,可能导致实现和维护的困难。
- 参数选择:选择适当的 K 值是 LRU-K 的一个挑战。K 值的选择需要综合考虑系统的特性和工作负载。选择过小的 K 值可能导致频繁的缓存项淘汰,而选择过大的 K 值可能导致缓存命中率下降。
- 不适用于突发访问模式:当出现突发访问模式时,LRU-K 的性能可能下降。如果有一组热点数据在短时间内被频繁访问,而其他数据很少被访问,LRU-K 可能无法准确识别这种热点数据,并导致它们被提前淘汰。
综上所述,虽然 LRU-K 在某些场景下可以改善缓存命中率,但它也存在一些不足之处。在选择缓存淘汰策略时,需要考虑系统的特性、工作负载以及对内存消耗和算法复杂性的容忍度。
Buffer Pool当中的Page Table有什么作用?
此处可以对比OS的内存映射和读取进行理解,在OS当中,首先数据是真实存储于物理内存当中,将物理内存划分为多个Page大小的槽位,每个槽位可以存储一个Page,而该槽位通过PFN(Phyical frame number)来表示。
当程序访问虚拟内存当中的数据时,虚拟内存当中的数据会属于某一个Page,用VPN(virtual page number)进行表示。
因此在读取数据时,就需要一个从VPN到PFN到一个映射,这个工作就交给Page Table来完成,其最简单的组织方式为一个数组,当中存储所有可能的映射(有效无效都存在),而如果采用多级页表的方式,其组织形式就是一个哈希表,key为VPN,val为PFN
在buffer pool 当中同理,首先创建一个Page*[]用于存储内存当中所有的Page,对应OS当中的物理内存,该数组的下标即为一个frame_id(对应PFN),对于上层获取数据而言,要拿到一个Page则需要通过page_id(对应VPN),此处的page table同样完成page_id -> frame_id的映射关系。
数据在磁盘上有什么组织形式?
主要分为两种组织形式,分别为基于Page的和基于日志的
Page
基于Page的主要方式以Page为基本数据单位,当中的数据主体为Tuple,此外还有一些元数据用于辅助读取,之后多个Page组成一个File,一个File可对应一个一张表。基于Page的最常见的为HeapFile-Page的组织形式。HeapPage承载Tuple,多个HeapPage构成一个HeapFIle。
首先,在HeapFile-Page的情况下为乱序存储的,即按顺序插入tuple a 和b,并不保证b存储于a之前。
因此在一个Page当中,只要能够找到空余空间,就可以将数据存储于其中,在这种规则下,HeapPage的结构为一个byte[]数组的header,用于表示该slot上是否为空余,之后则是一个Tuple[]数组,用于存储具体的tuple,在6.830当中,header[]的长度设置为8,即一个HeapPage当中可以存储256个tuple
之后HeapPage即可组成HeapFile,对于HeapPage的管理方式,最简单的方式即为不管理,当需要一个page时就根据pageId和pageSize计算出偏移量去偏移读取,也可通过一个Page Directory进行管理,本质上为一个page_id->offset的偏移量,有点类似于Bitcask
基于日志
Bitcask
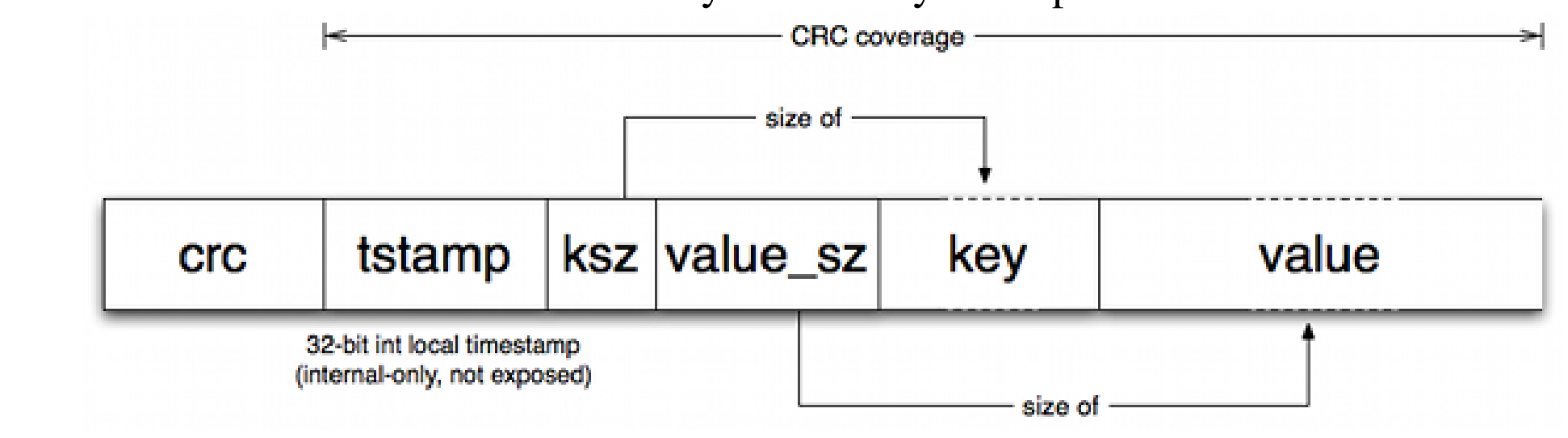
基于日志最经典的就是Bitcask模型,硬盘上为只进行顺序写入的文件,在内存当中再维护一个哈希表记录偏移,简单的以k-v类型为例,在写入时只进行追加写入,insert和update delete合并为一个put操作,insert update只需要向其中写入最新的数据,并更新索引,delete操作则写入一个墓碑标志,用于进行压缩,并且删除索引。在读取时只需要根据索引进行读取即可。
由于一直顺序写入会导致当中存储很多陈旧数据,此时就涉及到一个压缩操作,即将顺序扫描原本的db文件,并只保存最新的值
存储单元通常如下
LSM-Tree
首先对于一个段或者level,内部key需要按照顺序维护,这也是与Bitcask存储模型的最大的不同。
在存储上分为内存和磁盘两部分,所有的请求首先会写入到内存当中,在内存中进行管理,为了维护有序结构,在内存中可以使用跳表或者B+树等方式管理key,当内存当中的key到达上限时,在将其顺序写入到磁盘上,即可保证磁盘当中内容的有序性。
在写入之后,内存当中只需要保存稀疏的一个索引结构即可,不必保存所有的key。
在磁盘上即为SSTable,其中分为两种数据块,一种为存储数据,另一种为索引块,标明各个块的key的范围。
读写操作
- 写:就像上面所说的那样,先写入到内存当中,之后再刷盘进行持久化,形成一个有序数据块。
- 读:由于是追加写入,为了获取到最新的key,先尝试从内存中进行获取,如果没有则去读取最新的对应范围的数据块,如果获取不到再去寻找更陈旧的数据块,在第一次获取时则完成搜索,否则继续直至完成搜索。而对于范围查询,可以并行的查询多个符合范围的component
合并
为了解决磁盘当中component积累导致的读性能下降的问题,需要将多个component合并,以去除重复的key,从而减少查询的次数。主要有两种方案:
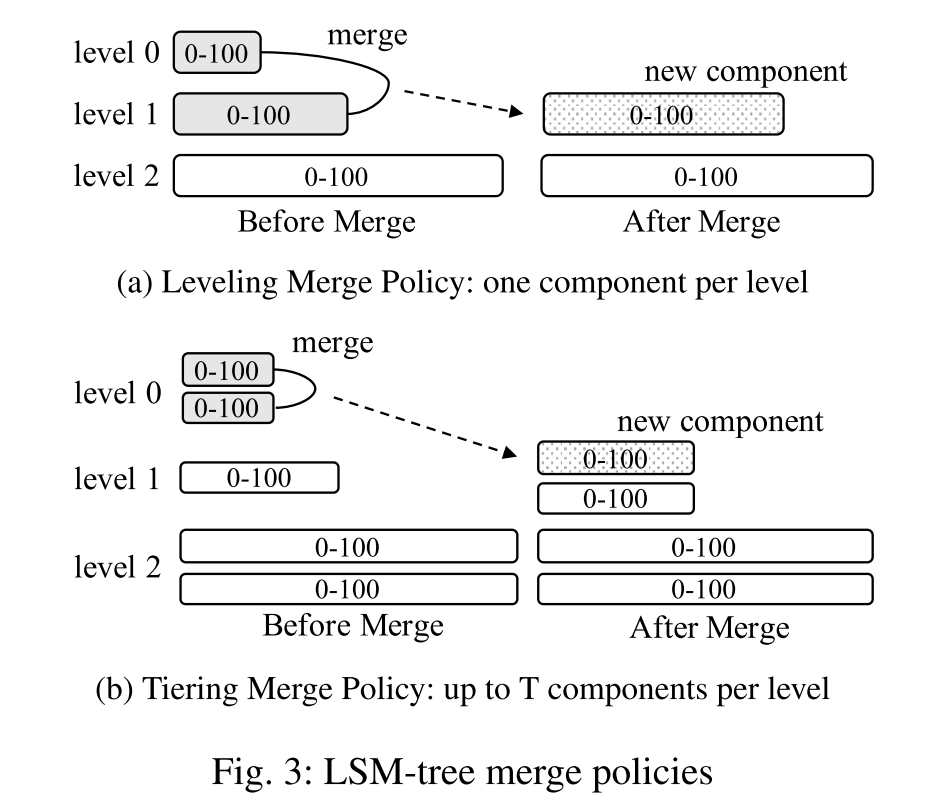
- level:在L层级的一个component会接受从L-1层级来的合并,直至达到该层的上限,之后向L+1层去进行合并
- tiers:一层当中会有T个component,当满了需要合并时,T个component合并成一个并放入到下一层。
L+1层能够容纳的key的数量为L层的T倍,并且对于插入删除数量相等的均衡情况,层数维持不变。
level策略下会通过频繁的合并以减少component的数量,对读请求较为友好,tiers策略下合并较少(一层满了T个之后才会合并),因此对于写请求较为友好。
索引
谈一谈索引和常见的索引形式
数据库索引是一种用于提高数据库查询性能的数据结构。它类似于书籍的目录,通过按照特定字段或字段组合对数据库表中的数据进行排序和组织,从而加快对数据的检索速度。
较为常见的索引类型为hashtable 和 B+ Tree,在形式上分为聚簇索引和非聚簇索引
- 对于聚簇索引索引,则存在一个主键,默认为主键创建索引,之后主键的索引上存储真实的数据,通过在主键索引上搜索即可找到对应的Tuple,这样的好处是当需要通过主键进行搜索时,可以通过对索引的一次访问就找到数据,而对于二级索引,其中存储的为key -> 主键,即通过二级索引只能找到一个主键索引的标志,之后再通过这个标识去主键索引当中读取,这个过程称为回表。
- 对于非聚簇索引,不存在主键、二级索引的概念,所有的索引所存储的都是一个key -> offset,这个offset通常为一个组合,当中可能包含table_id page_id offset,拿到这个offset之后再去HeapFile-Page当中偏移读取。
说一说B+树
不想说了。。。移步Bustub Lab2
简单介绍一下哈希表
这里不针对哈希索引,只是说一下哈希表这种数据结构,主要分为静态哈希和动态哈希
静态哈希
静态哈希的本质上为一个数组,通过哈希函数 % len的方式找到一个数组下标,该下标就对应着真实的存储位置。
对于哈希冲突问题,根据不同的解决方式可以继续细分:
最基础的即为线性探测,即向下一个哈希槽移动,在删除时将由于冲突向下移动的均向原来的位置移动一格,或者设置一个墓碑,令该哈希槽不可用
罗宾汉哈希
罗宾汉劫富济贫,缩小贫富差距,因此引入一个权重,来标识距离原本计算出来的槽的距离,最终的目标是令所有的所有的key的权重(距离)较为平均
下图蓝色标识原本计算出的槽的位置,val[i]标识最终的位置具体最初计算出的位置的距离
D[1]<E[2],因此为了保证均衡,E进入当前D所在的槽,将D挤到下一个槽处,这样D E的权重均为2,而不是一个1一个3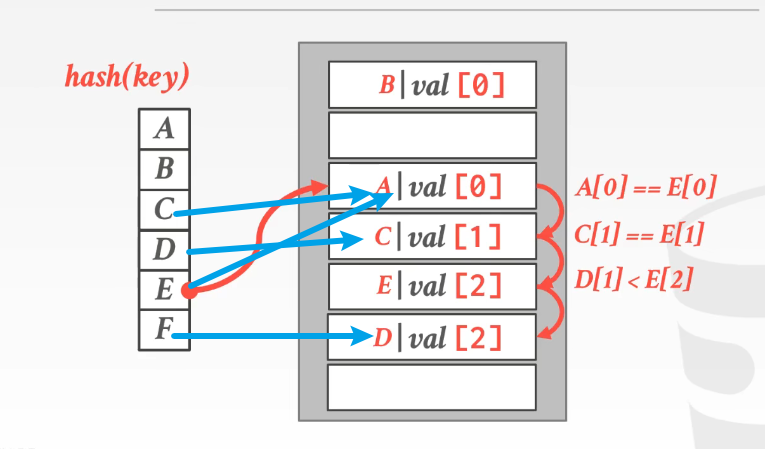
CUCKOO 哈希
- 创建两个哈希表,但加入一个键是,使用两个不同的哈希函数进行运算,在两个哈希表中挑选一个没有冲突的槽放入
- 如果两个均冲突了,选择一个槽,假设选择了1号哈希表,将其中原本的元素取出,使用2号哈希函数计算,试图放入到2号哈希表中,如果还冲突,取出2号的去1号尝试
- 这个过程中可能存在无限循环的问题,需要进行检测,并对哈希表扩容
动态哈希
链哈希:在一个哈希槽上存在多个哈希桶,各个哈希桶之间用链表连接,哈希桶中存在多个Key
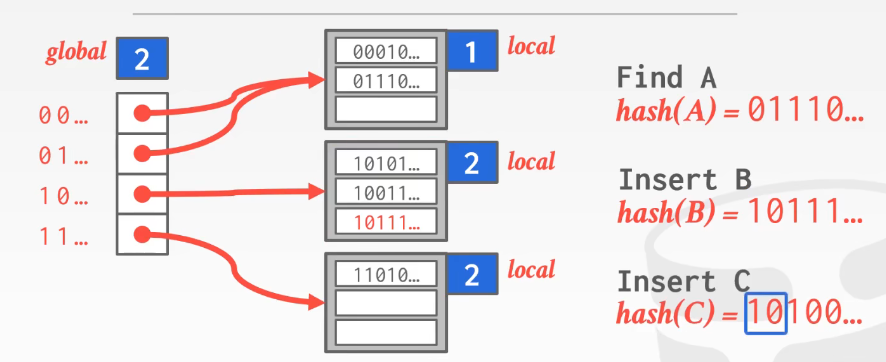
EXTENDIBLE HASHING:
- 维护一个全局计数器,标识一个哈希在寻找哈希槽是需要比较的位数
- 每个哈希槽维护一个local计数器,标识在这个哈希槽内需要比较的位数
全局计数器用于找到对应的哈希槽,局部计数器用于在扩容时分配元素